 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitePT: Lighter Yet Stronger Point Transformer
Dec 15, 2025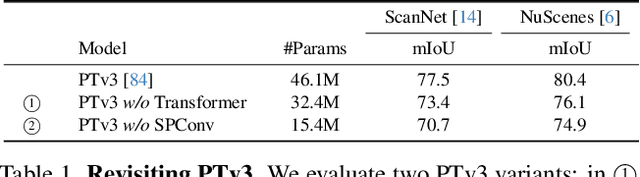
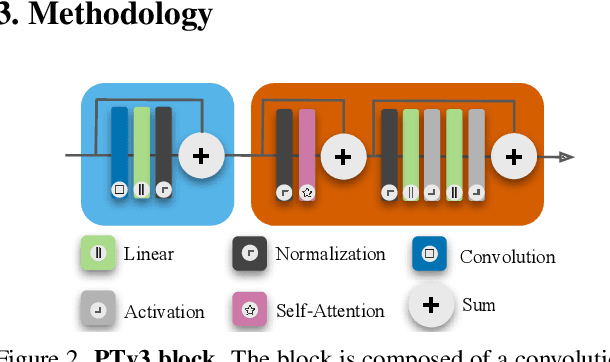
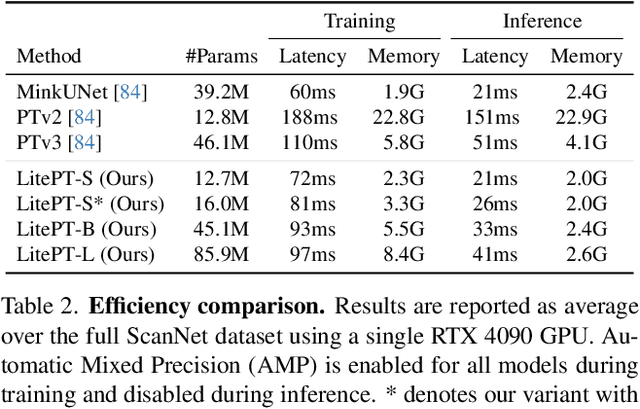
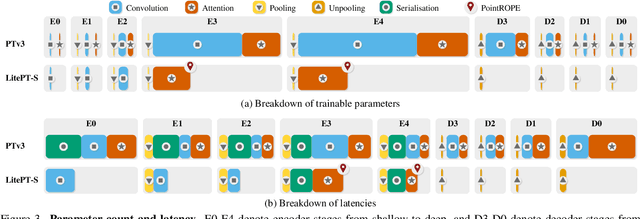
Modern neural architectures for 3D point cloud processing contain both convolutional layers and attention blocks, but the best way to assemble them remains unclear. We analyse the role of different computational blocks in 3D point cloud networks and find an intuitive behaviour: convolution is adequate to extract low-level geometry at high-resolution in early layers, where attention is expensive without bringing any benefits; attention captures high-level semantics and context in low-resolution, deep layers more efficiently. Guided by this design principle, we propose a new, improved 3D point cloud backbone that employs convolutions in early stages and switches to attention for deeper layers. To avoid the loss of spatial layout information when discarding redundant convolution layers, we introduce a novel, training-free 3D positional encoding, PointROPE. The resulting LitePT model has $3.6\times$ fewer parameters, runs $2\times$ faster, and uses $2\times$ less memory than the state-of-the-art Point Transformer V3, but nonetheless matches or even outperforms it on a range of tasks and datasets. Code and models are available at: https://github.com/prs-eth/LitePT.
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Jul 29, 2024



Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.
Is Continual Learning Ready for Real-world Challenges?
Feb 15, 2024Despite continual learning's long and well-established academic history, its application in real-world scenarios remains rather limited. This paper contends that this gap is attributable to a misalignment between the actual challenges of continual learning and the evaluation protocols in use, rendering proposed solutions ineffective for addressing the complexities of real-world setups. We validate our hypothesis and assess progress to date, using a new 3D semantic segmentation benchmark, OCL-3DSS. We investigate various continual learning schemes from the literature by utilizing more realistic protocols that necessitate online and continual learning for dynamic, real-world scenarios (eg., in robotics and 3D vision applications). The outcomes are sobering: all considered methods perform poorly, significantly deviating from the upper bound of joint offline training. This raises questions about the applicability of existing methods in realistic settings. Our paper aims to initiate a paradigm shift, advocating for the adoption of continual learning methods through new experimental protocols that better emulate real-world conditions to facilitate breakthroughs in the field.
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation
Jun 01, 2023



During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. From a machine learning perspective the goal is to design the model and the feedback mechanism in a way that minimizes the required user input. The current best practice segments objects one at a time, and asks the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks to indicate regions wrongly assigned to the object (foreground). Sequentially visiting objects is wasteful, since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects, moreover a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. We encode the point cloud into a latent feature representation, and view user clicks as queries and employ cross-attention to represent contextual relations between different click locations as well as between clicks and the 3D point cloud features. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different point cloud datasets, AGILE3D sets a new state of the art, moreover, we also verify its practicality in real-world setups with a real user study.
A Review of Panoptic Segmentation for Mobile Mapping Point Clouds
Apr 27, 2023
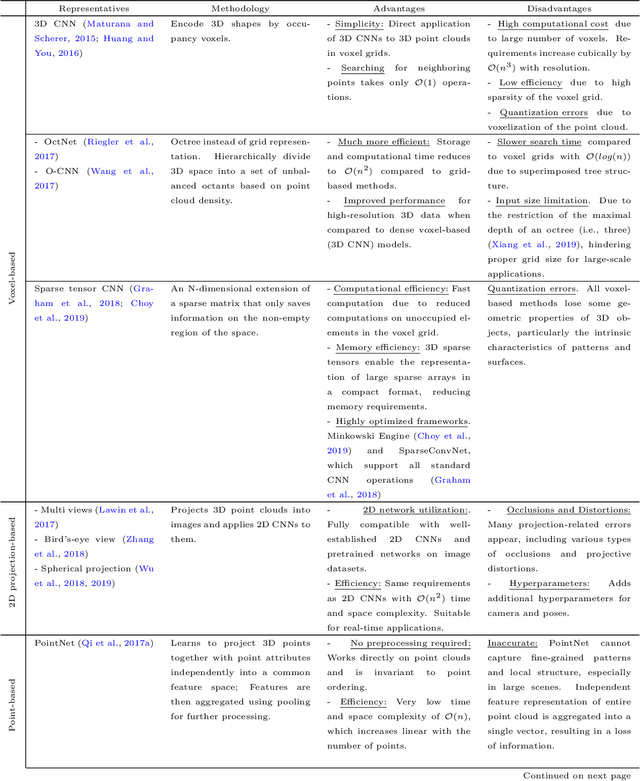
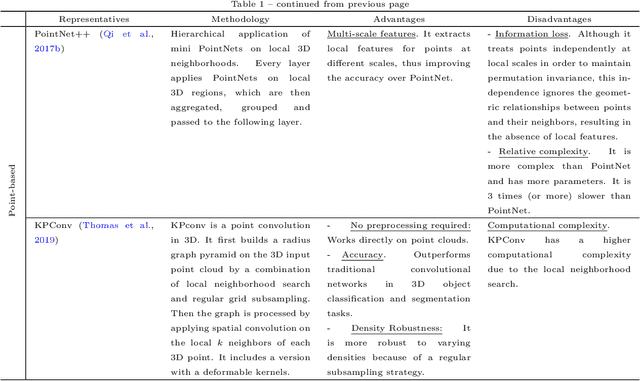

3D point cloud panoptic segmentation is the combined task to (i) assign each point to a semantic class and (ii) separate the points in each class into object instances. Recently there has been an increased interest in such comprehensive 3D scene understanding, building on the rapid advances of semantic segmentation due to the advent of deep 3D neural networks. Yet, to date there is very little work about panoptic segmentation of outdoor mobile-mapping data, and no systematic comparisons. The present paper tries to close that gap. It reviews the building blocks needed to assemble a panoptic segmentation pipeline and the related literature. Moreover, a modular pipeline is set up to perform comprehensive, systematic experiments to assess the state of panoptic segmentation in the context of street mapping. As a byproduct, we also provide the first public dataset for that task, by extending the NPM3D dataset to include instance labels.
Connecting the Dots: Floorplan Reconstruction Using Two-Level Queries
Nov 28, 2022



We address 2D floorplan reconstruction from 3D scans. Existing approaches typically employ heuristically designed multi-stage pipelines. Instead, we formulate floorplan reconstruction as a single-stage structured prediction task: find a variable-size set of polygons, which in turn are variable-length sequences of ordered vertices. To solve it we develop a novel Transformer architecture that generates polygons of multiple rooms in parallel, in a holistic manner without hand-crafted intermediate stages. The model features two-level queries for polygons and corners, and includes polygon matching to make the network end-to-end trainable. Our method achieves a new state-of-the-art for two challenging datasets, Structured3D and SceneCAD, along with significantly faster inference than previous methods. Moreover, it can readily be extended to predict additional information, i.e., semantic room types and architectural elements like doors and windows. Our code and models will be available at: https://github.com/ywyue/RoomFormer.
ImpliCity: City Modeling from Satellite Images with Deep Implicit Occupancy Fields
Jan 24, 2022
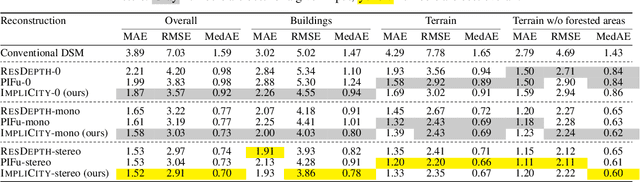
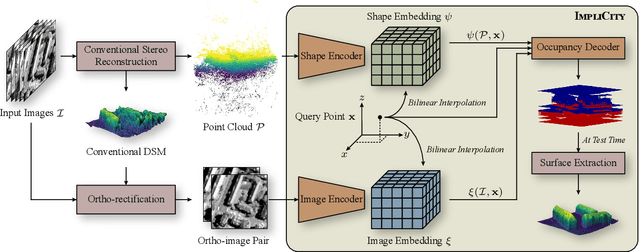

High-resolution optical satellite sensors, in combination with dense stereo algorithms, have made it possible to reconstruct 3D city models from space. However, the resulting models are, in practice, rather noisy, and they tend to miss small geometric features that are clearly visible in the images. We argue that one reason for the limited DSM quality may be a too early, heuristic reduction of the triangulated 3D point cloud to an explicit height field or surface mesh. To make full use of the point cloud and the underlying images, we introduce ImpliCity, a neural representation of the 3D scene as an implicit, continuous occupancy field, driven by learned embeddings of the point cloud and a stereo pair of ortho-photos. We show that this representation enables the extraction of high-quality DSMs: with image resolution 0.5$\,$m, ImpliCity reaches a median height error of $\approx\,$0.7$\,$m and outperforms competing methods, especially w.r.t. building reconstruction, featuring intricate roof details, smooth surfaces, and straight, regular outlines.