 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025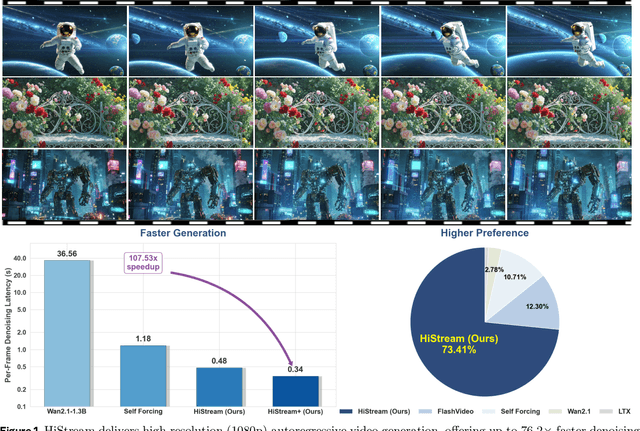
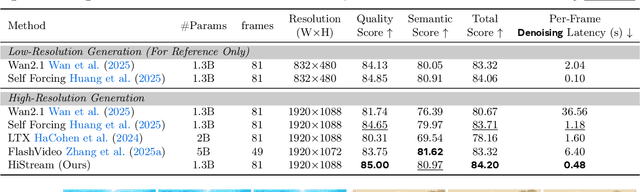
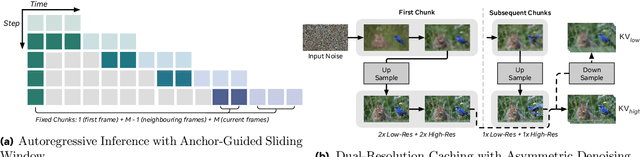
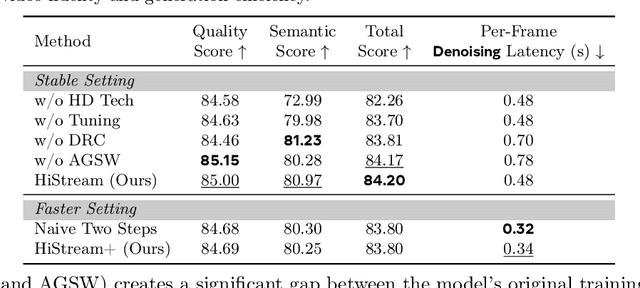
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


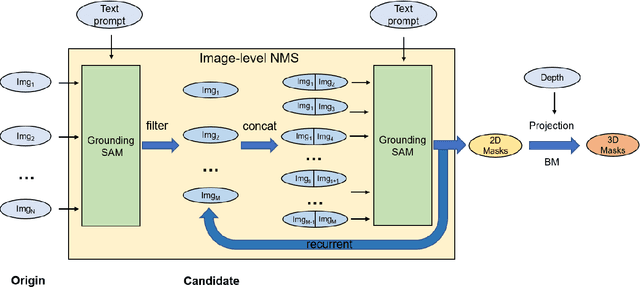
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023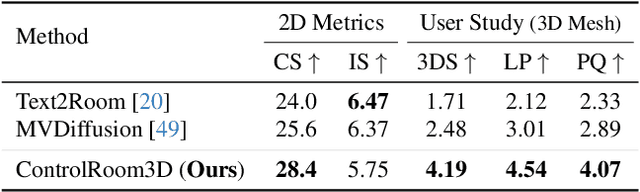
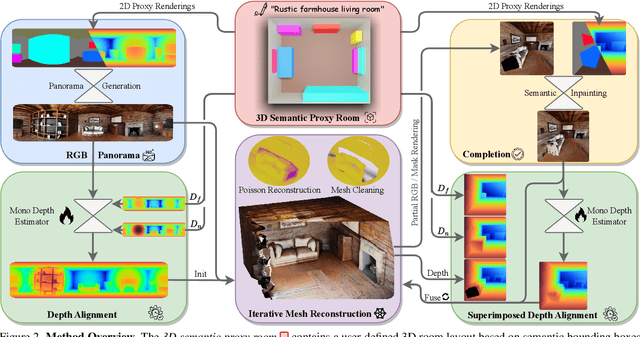
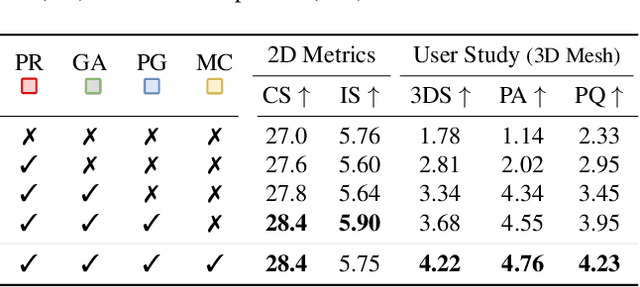
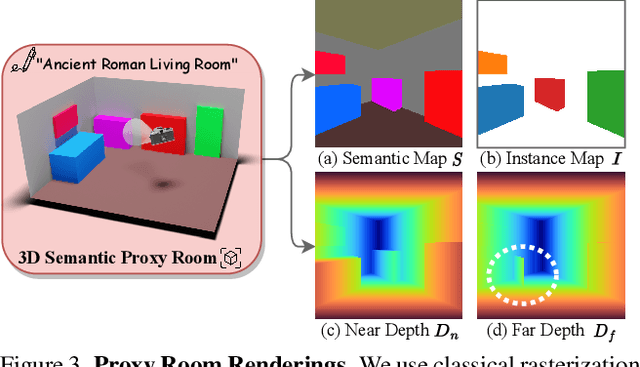
Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
MASK4D: Mask Transformer for 4D Panoptic Segmentation
Sep 28, 2023

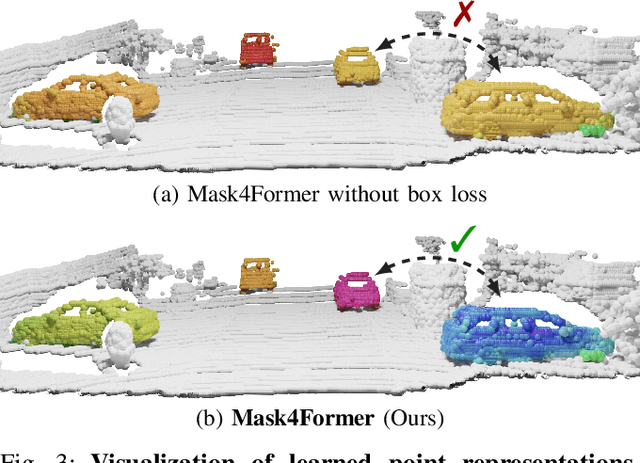

Accurately perceiving and tracking instances over time is essential for the decision-making processes of autonomous agents interacting safely in dynamic environments. With this intention, we propose Mask4D for the challenging task of 4D panoptic segmentation of LiDAR point clouds. Mask4D is the first transformer-based approach unifying semantic instance segmentation and tracking of sparse and irregular sequences of 3D point clouds into a single joint model. Our model directly predicts semantic instances and their temporal associations without relying on any hand-crafted non-learned association strategies such as probabilistic clustering or voting-based center prediction. Instead, Mask4D introduces spatio-temporal instance queries which encode the semantic and geometric properties of each semantic tracklet in the sequence. In an in-depth study, we find that it is critical to promote spatially compact instance predictions as spatio-temporal instance queries tend to merge multiple semantically similar instances, even if they are spatially distant. To this end, we regress 6-DOF bounding box parameters from spatio-temporal instance queries, which is used as an auxiliary task to foster spatially compact predictions. Mask4D achieves a new state-of-the-art on the SemanticKITTI test set with a score of 68.4 LSTQ, improving upon published top-performing methods by at least +4.5%.
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation
Jun 01, 2023



During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. From a machine learning perspective the goal is to design the model and the feedback mechanism in a way that minimizes the required user input. The current best practice segments objects one at a time, and asks the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks to indicate regions wrongly assigned to the object (foreground). Sequentially visiting objects is wasteful, since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects, moreover a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. We encode the point cloud into a latent feature representation, and view user clicks as queries and employ cross-attention to represent contextual relations between different click locations as well as between clicks and the 3D point cloud features. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different point cloud datasets, AGILE3D sets a new state of the art, moreover, we also verify its practicality in real-world setups with a real user study.
Point2Vec for Self-Supervised Representation Learning on Point Clouds
Mar 29, 2023Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds. To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
3D Segmentation of Humans in Point Clouds with Synthetic Data
Dec 09, 2022Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
Mask3D for 3D Semantic Instance Segmentation
Oct 06, 2022

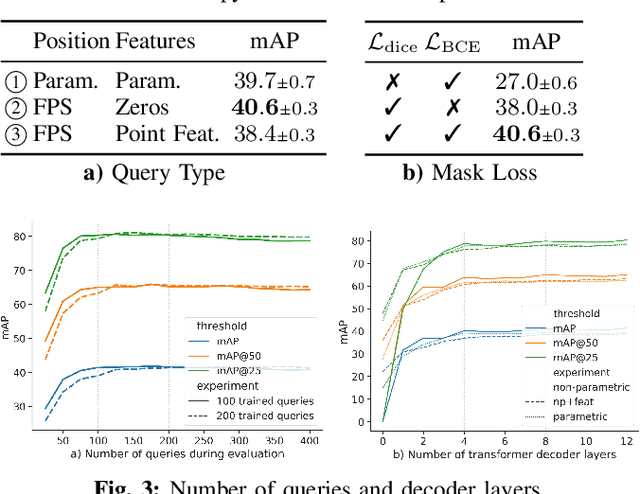
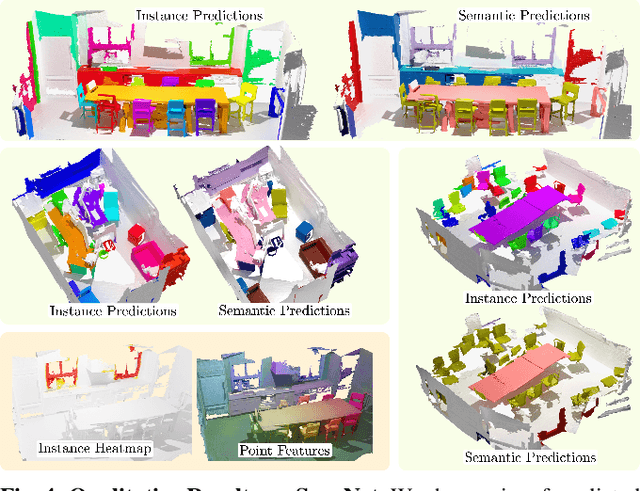
Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
Mix3D: Out-of-Context Data Augmentation for 3D Scenes
Oct 05, 2021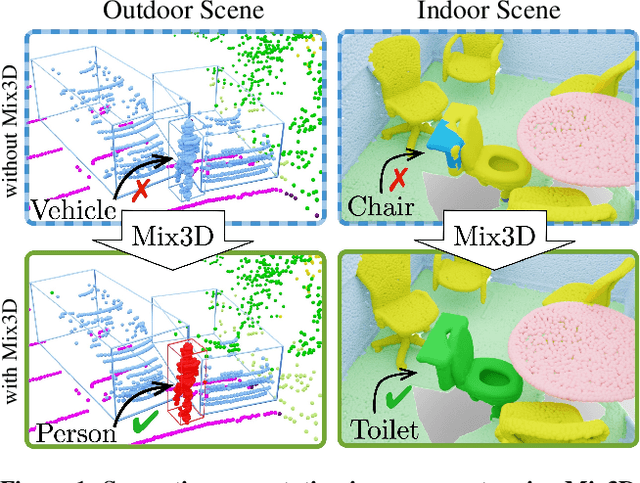
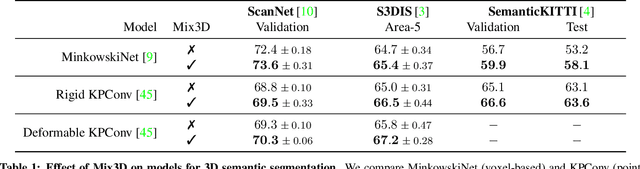


We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/
DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes
Apr 02, 2020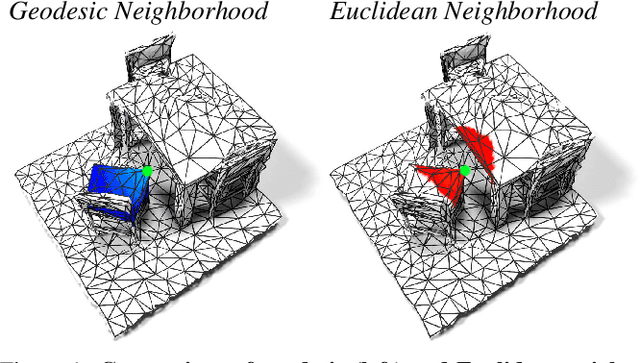
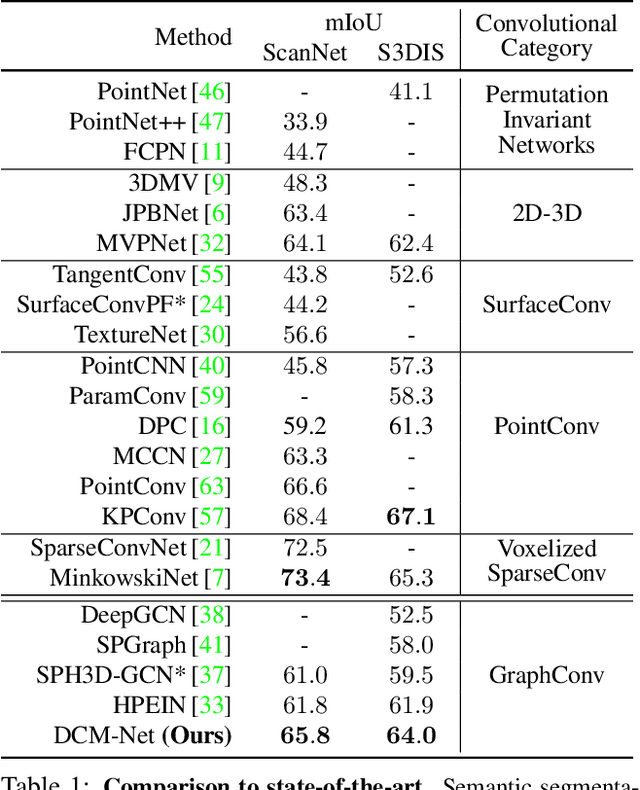
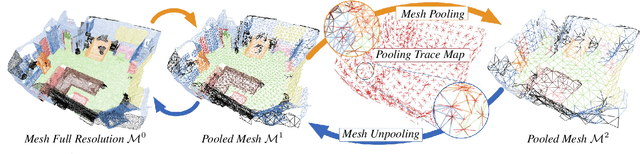
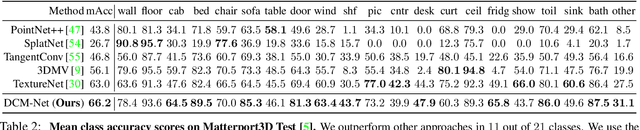
We propose DualConvMesh-Nets (DCM-Net) a family of deep hierarchical convolutional networks over 3D geometric data that combines two types of convolutions. The first type, geodesic convolutions, defines the kernel weights over mesh surfaces or graphs. That is, the convolutional kernel weights are mapped to the local surface of a given mesh. The second type, Euclidean convolutions, is independent of any underlying mesh structure. The convolutional kernel is applied on a neighborhood obtained from a local affinity representation based on the Euclidean distance between 3D points. Intuitively, geodesic convolutions can easily separate objects that are spatially close but have disconnected surfaces, while Euclidean convolutions can represent interactions between nearby objects better, as they are oblivious to object surfaces. To realize a multi-resolution architecture, we borrow well-established mesh simplification methods from the geometry processing domain and adapt them to define mesh-preserving pooling and unpooling operations. We experimentally show that combining both types of convolutions in our architecture leads to significant performance gains for 3D semantic segmentation, and we report competitive results on three scene segmentation benchmarks. Our models and code are publicly available.