 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix3D: Out-of-Context Data Augmentation for 3D Scenes
Paper and Code
Oct 05, 2021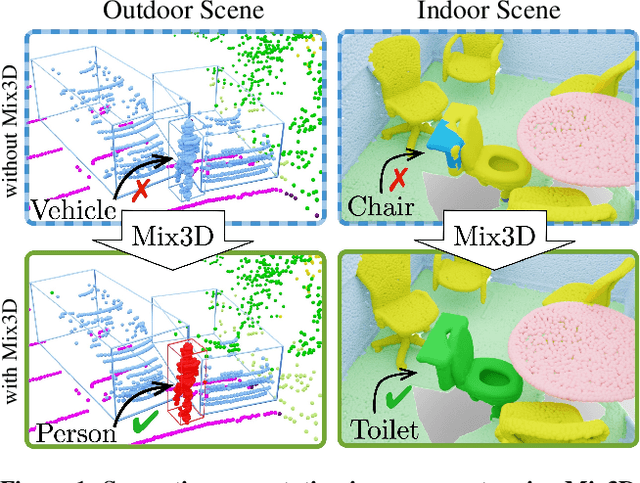
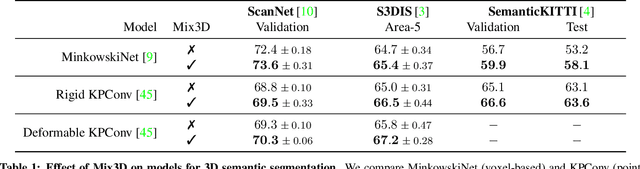


We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/