 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotting the Unexpected (STU): A 3D LiDAR Dataset for Anomaly Segmentation in Autonomous Driving
May 04, 2025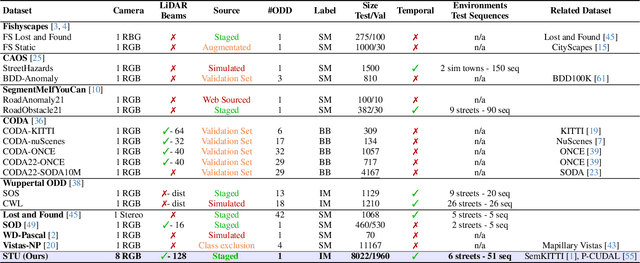



To operate safely, autonomous vehicles (AVs) need to detect and handle unexpected objects or anomalies on the road. While significant research exists for anomaly detection and segmentation in 2D, research progress in 3D is underexplored. Existing datasets lack high-quality multimodal data that are typically found in AVs. This paper presents a novel dataset for anomaly segmentation in driving scenarios. To the best of our knowledge, it is the first publicly available dataset focused on road anomaly segmentation with dense 3D semantic labeling, incorporating both LiDAR and camera data, as well as sequential information to enable anomaly detection across various ranges. This capability is critical for the safe navigation of autonomous vehicles. We adapted and evaluated several baseline models for 3D segmentation, highlighting the challenges of 3D anomaly detection in driving environments. Our dataset and evaluation code will be openly available, facilitating the testing and performance comparison of different approaches.
Panoptic-CUDAL Technical Report: Rural Australia Point Cloud Dataset in Rainy Conditions
Mar 20, 2025Existing autonomous driving datasets are predominantly oriented towards well-structured urban settings and favorable weather conditions, leaving the complexities of rural environments and adverse weather conditions largely unaddressed. Although some datasets encompass variations in weather and lighting, bad weather scenarios do not appear often. Rainfall can significantly impair sensor functionality, introducing noise and reflections in LiDAR and camera data and reducing the system's capabilities for reliable environmental perception and safe navigation. We introduce the Panoptic-CUDAL dataset, a novel dataset purpose-built for panoptic segmentation in rural areas subject to rain. By recording high-resolution LiDAR, camera, and pose data, Panoptic-CUDAL offers a diverse, information-rich dataset in a challenging scenario. We present analysis of the recorded data and provide baseline results for panoptic and semantic segmentation methods on LiDAR point clouds. The dataset can be found here: https://robotics.sydney.edu.au/our-research/intelligent-transportation-systems/
OCCUQ: Exploring Efficient Uncertainty Quantification for 3D Occupancy Prediction
Mar 13, 2025Autonomous driving has the potential to significantly enhance productivity and provide numerous societal benefits. Ensuring robustness in these safety-critical systems is essential, particularly when vehicles must navigate adverse weather conditions and sensor corruptions that may not have been encountered during training. Current methods often overlook uncertainties arising from adversarial conditions or distributional shifts, limiting their real-world applicability. We propose an efficient adaptation of an uncertainty estimation technique for 3D occupancy prediction. Our method dynamically calibrates model confidence using epistemic uncertainty estimates. Our evaluation under various camera corruption scenarios, such as fog or missing cameras, demonstrates that our approach effectively quantifies epistemic uncertainty by assigning higher uncertainty values to unseen data. We introduce region-specific corruptions to simulate defects affecting only a single camera and validate our findings through both scene-level and region-level assessments. Our results show superior performance in Out-of-Distribution (OoD) detection and confidence calibration compared to common baselines such as Deep Ensembles and MC-Dropout. Our approach consistently demonstrates reliable uncertainty measures, indicating its potential for enhancing the robustness of autonomous driving systems in real-world scenarios. Code and dataset are available at https://github.com/ika-rwth-aachen/OCCUQ .
MaskTerial: A Foundation Model for Automated 2D Material Flake Detection
Dec 12, 2024



The detection and classification of exfoliated two-dimensional (2D) material flakes from optical microscope images can be automated using computer vision algorithms. This has the potential to increase the accuracy and objectivity of classification and the efficiency of sample fabrication, and it allows for large-scale data collection. Existing algorithms often exhibit challenges in identifying low-contrast materials and typically require large amounts of training data. Here, we present a deep learning model, called MaskTerial, that uses an instance segmentation network to reliably identify 2D material flakes. The model is extensively pre-trained using a synthetic data generator, that generates realistic microscopy images from unlabeled data. This results in a model that can to quickly adapt to new materials with as little as 5 to 10 images. Furthermore, an uncertainty estimation model is used to finally classify the predictions based on optical contrast. We evaluate our method on eight different datasets comprising five different 2D materials and demonstrate significant improvements over existing techniques in the detection of low-contrast materials such as hexagonal boron nitride.
OoDIS: Anomaly Instance Segmentation Benchmark
Jun 17, 2024



Autonomous vehicles require a precise understanding of their environment to navigate safely. Reliable identification of unknown objects, especially those that are absent during training, such as wild animals, is critical due to their potential to cause serious accidents. Significant progress in semantic segmentation of anomalies has been driven by the availability of out-of-distribution (OOD) benchmarks. However, a comprehensive understanding of scene dynamics requires the segmentation of individual objects, and thus the segmentation of instances is essential. Development in this area has been lagging, largely due to the lack of dedicated benchmarks. To address this gap, we have extended the most commonly used anomaly segmentation benchmarks to include the instance segmentation task. Our evaluation of anomaly instance segmentation methods shows that this challenge remains an unsolved problem. The benchmark website and the competition page can be found at: https://vision.rwth-aachen.de/oodis .
MASK4D: Mask Transformer for 4D Panoptic Segmentation
Sep 28, 2023

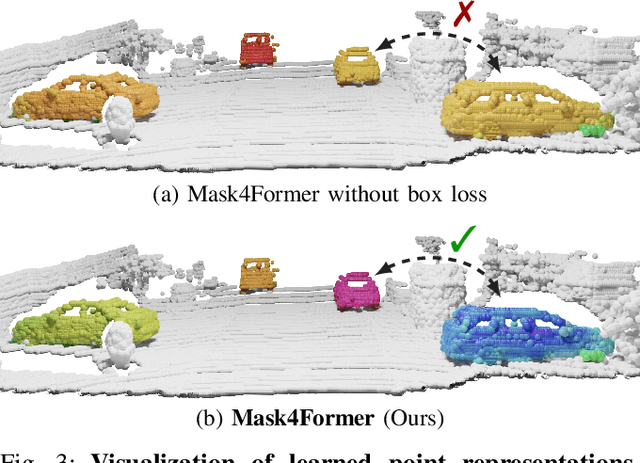

Accurately perceiving and tracking instances over time is essential for the decision-making processes of autonomous agents interacting safely in dynamic environments. With this intention, we propose Mask4D for the challenging task of 4D panoptic segmentation of LiDAR point clouds. Mask4D is the first transformer-based approach unifying semantic instance segmentation and tracking of sparse and irregular sequences of 3D point clouds into a single joint model. Our model directly predicts semantic instances and their temporal associations without relying on any hand-crafted non-learned association strategies such as probabilistic clustering or voting-based center prediction. Instead, Mask4D introduces spatio-temporal instance queries which encode the semantic and geometric properties of each semantic tracklet in the sequence. In an in-depth study, we find that it is critical to promote spatially compact instance predictions as spatio-temporal instance queries tend to merge multiple semantically similar instances, even if they are spatially distant. To this end, we regress 6-DOF bounding box parameters from spatio-temporal instance queries, which is used as an auxiliary task to foster spatially compact predictions. Mask4D achieves a new state-of-the-art on the SemanticKITTI test set with a score of 68.4 LSTQ, improving upon published top-performing methods by at least +4.5%.
UGainS: Uncertainty Guided Anomaly Instance Segmentation
Aug 03, 2023
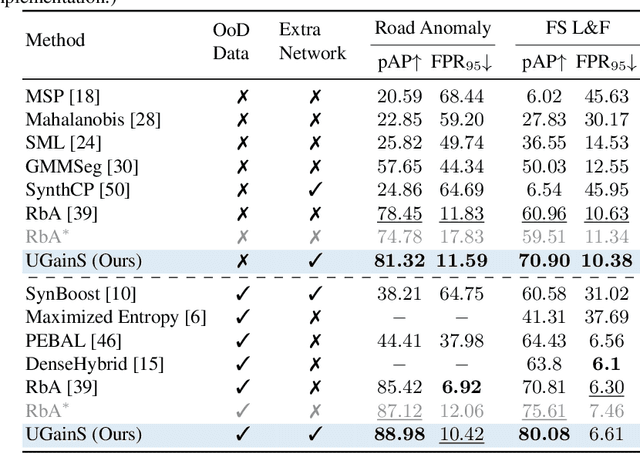
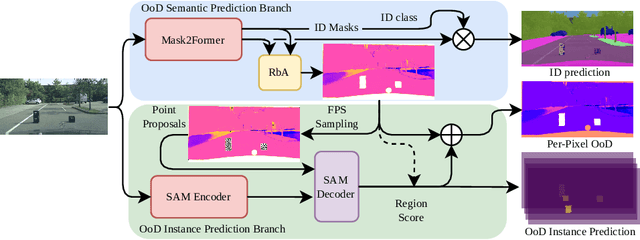
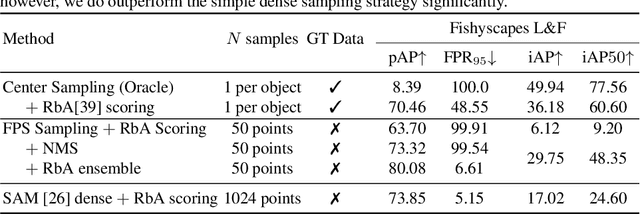
A single unexpected object on the road can cause an accident or may lead to injuries. To prevent this, we need a reliable mechanism for finding anomalous objects on the road. This task, called anomaly segmentation, can be a stepping stone to safe and reliable autonomous driving. Current approaches tackle anomaly segmentation by assigning an anomaly score to each pixel and by grouping anomalous regions using simple heuristics. However, pixel grouping is a limiting factor when it comes to evaluating the segmentation performance of individual anomalous objects. To address the issue of grouping multiple anomaly instances into one, we propose an approach that produces accurate anomaly instance masks. Our approach centers on an out-of-distribution segmentation model for identifying uncertain regions and a strong generalist segmentation model for anomaly instances segmentation. We investigate ways to use uncertain regions to guide such a segmentation model to perform segmentation of anomalous instances. By incorporating strong object priors from a generalist model we additionally improve the per-pixel anomaly segmentation performance. Our approach outperforms current pixel-level anomaly segmentation methods, achieving an AP of 80.08% and 88.98% on the Fishyscapes Lost and Found and the RoadAnomaly validation sets respectively. Project page: https://vision.rwth-aachen.de/ugains
Mix3D: Out-of-Context Data Augmentation for 3D Scenes
Oct 05, 2021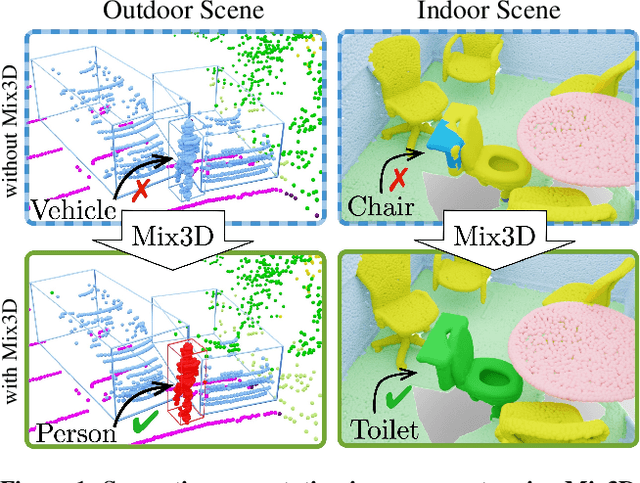
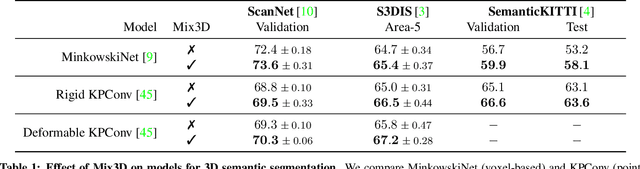


We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/