 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Wheel Sensor Communication using ESP32 -- A Contribution towards a Digital Twin of the Road System
Sep 04, 2025While current onboard state estimation methods are adequate for most driving and safety-related applications, they do not provide insights into the interaction between tires and road surfaces. This paper explores a novel communication concept for efficiently transmitting integrated wheel sensor data from an ESP32 microcontroller. Our proposed approach utilizes a publish-subscribe system, surpassing comparable solutions in the literature regarding data transmission volume. We tested this approach on a drum tire test rig with our prototype sensors system utilizing a diverse selection of sample frequencies between 1 Hz and 32 000 Hz to demonstrate the efficacy of our communication concept. The implemented prototype sensor showcases minimal data loss, approximately 0.1 % of the sampled data, validating the reliability of our developed communication system. This work contributes to advancing real-time data acquisition, providing insights into optimizing integrated wheel sensor communication.
OCCUQ: Exploring Efficient Uncertainty Quantification for 3D Occupancy Prediction
Mar 13, 2025Autonomous driving has the potential to significantly enhance productivity and provide numerous societal benefits. Ensuring robustness in these safety-critical systems is essential, particularly when vehicles must navigate adverse weather conditions and sensor corruptions that may not have been encountered during training. Current methods often overlook uncertainties arising from adversarial conditions or distributional shifts, limiting their real-world applicability. We propose an efficient adaptation of an uncertainty estimation technique for 3D occupancy prediction. Our method dynamically calibrates model confidence using epistemic uncertainty estimates. Our evaluation under various camera corruption scenarios, such as fog or missing cameras, demonstrates that our approach effectively quantifies epistemic uncertainty by assigning higher uncertainty values to unseen data. We introduce region-specific corruptions to simulate defects affecting only a single camera and validate our findings through both scene-level and region-level assessments. Our results show superior performance in Out-of-Distribution (OoD) detection and confidence calibration compared to common baselines such as Deep Ensembles and MC-Dropout. Our approach consistently demonstrates reliable uncertainty measures, indicating its potential for enhancing the robustness of autonomous driving systems in real-world scenarios. Code and dataset are available at https://github.com/ika-rwth-aachen/OCCUQ .
Scenario-based Thermal Management Parametrization Through Deep Reinforcement Learning
Aug 04, 2024The thermal system of battery electric vehicles demands advanced control. Its thermal management needs to effectively control active components across varying operating conditions. While robust control function parametrization is required, current methodologies show significant drawbacks. They consume considerable time, human effort, and extensive real-world testing. Consequently, there is a need for innovative and intelligent solutions that are capable of autonomously parametrizing embedded controllers. Addressing this issue, our paper introduces a learning-based tuning approach. We propose a methodology that benefits from automated scenario generation for increased robustness across vehicle usage scenarios. Our deep reinforcement learning agent processes the tuning task context and incorporates an image-based interpretation of embedded parameter sets. We demonstrate its applicability to a valve controller parametrization task and verify it in real-world vehicle testing. The results highlight the competitive performance to baseline methods. This novel approach contributes to the shift towards virtual development of thermal management functions, with promising potential of large-scale parameter tuning in the automotive industry.
Open-Source Tool Based Framework for Automated Performance Evaluation of an AD Function
Jun 24, 2024



As automation in the field of automated driving (AD) progresses, ensuring the safety and functionality of AD functions (ADFs) becomes crucial. Virtual scenario-based testing has emerged as a prevalent method for evaluating these systems, allowing for a wider range of testing environments and reproducibility of results. This approach involves AD-equipped test vehicles operating within predefined scenarios to achieve specific driving objectives. To comprehensively assess the impact of road network properties on the performance of an ADF, varying parameters such as intersection angle, curvature and lane width is essential. However, covering all potential scenarios is impractical, necessitating the identification of feasible parameter ranges and automated generation of corresponding road networks for simulation. Automating the workflow of road network generation, parameter variation, simulation, and evaluation leads to a comprehensive understanding of an ADF's behavior in diverse road network conditions. This paper aims to investigate the influence of road network parameters on the performance of a prototypical ADF through virtual scenario-based testing, ultimately advocating the importance of road topology in assuring safety and reliability of ADFs.
CARLOS: An Open, Modular, and Scalable Simulation Framework for the Development and Testing of Software for C-ITS
Apr 04, 2024Future mobility systems and their components are increasingly defined by their software. The complexity of these cooperative intelligent transport systems (C-ITS) and the everchanging requirements posed at the software require continual software updates. The dynamic nature of the system and the practically innumerable scenarios in which different software components work together necessitate efficient and automated development and testing procedures that use simulations as one core methodology. The availability of such simulation architectures is a common interest among many stakeholders, especially in the field of automated driving. That is why we propose CARLOS - an open, modular, and scalable simulation framework for the development and testing of software in C-ITS that leverages the rich CARLA and ROS ecosystems. We provide core building blocks for this framework and explain how it can be used and extended by the community. Its architecture builds upon modern microservice and DevOps principles such as containerization and continuous integration. In our paper, we motivate the architecture by describing important design principles and showcasing three major use cases - software prototyping, data-driven development, and automated testing. We make CARLOS and example implementations of the three use cases publicly available at github.com/ika-rwth-aachen/carlos
Determining the Tactical Challenge of Scenarios to Efficiently Test Automated Driving Systems
Apr 03, 2024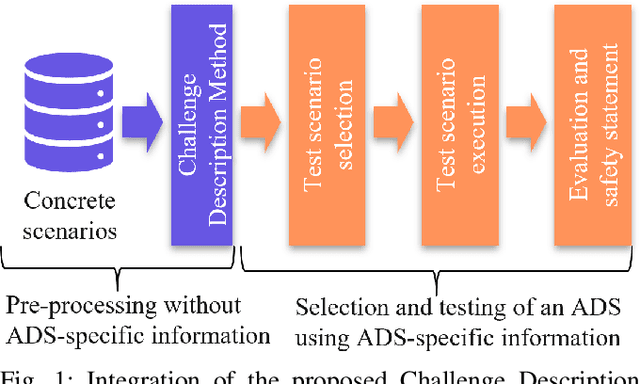



The selection of relevant test scenarios for the scenario-based testing and safety validation of automated driving systems (ADSs) remains challenging. An important aspect of the relevance of a scenario is the challenge it poses for an ADS. Existing methods for calculating the challenge of a scenario aim to express the challenge in terms of a metric value. Metric values are useful to select the least or most challenging scenario. However, they fail to provide human-interpretable information on the cause of the challenge which is critical information for the efficient selection of relevant test scenarios. Therefore, this paper presents the Challenge Description Method that mitigates this issue by analyzing scenarios and providing a description of their challenge in terms of the minimum required lane changes and their difficulty. Applying the method to different highway scenarios showed that it is capable of analyzing complex scenarios and providing easy-to-understand descriptions that can be used to select relevant test scenarios.
Causality-based Transfer of Driving Scenarios to Unseen Intersections
Apr 02, 2024



Scenario-based testing of automated driving functions has become a promising method to reduce time and cost compared to real-world testing. In scenario-based testing automated functions are evaluated in a set of pre-defined scenarios. These scenarios provide information about vehicle behaviors, environmental conditions, or road characteristics using parameters. To create realistic scenarios, parameters and parameter dependencies have to be fitted utilizing real-world data. However, due to the large variety of intersections and movement constellations found in reality, data may not be available for certain scenarios. This paper proposes a methodology to systematically analyze relations between parameters of scenarios. Bayesian networks are utilized to analyze causal dependencies in order to decrease the amount of required data and to transfer causal patterns creating unseen scenarios. Thereby, infrastructural influences on movement patterns are investigated to generate realistic scenarios on unobserved intersections. For evaluation, scenarios and underlying parameters are extracted from the inD dataset. Movement patterns are estimated, transferred and checked against recorded data from those initially unseen intersections.
MultiCorrupt: A Multi-Modal Robustness Dataset and Benchmark of LiDAR-Camera Fusion for 3D Object Detection
Feb 18, 2024Multi-modal 3D object detection models for automated driving have demonstrated exceptional performance on computer vision benchmarks like nuScenes. However, their reliance on densely sampled LiDAR point clouds and meticulously calibrated sensor arrays poses challenges for real-world applications. Issues such as sensor misalignment, miscalibration, and disparate sampling frequencies lead to spatial and temporal misalignment in data from LiDAR and cameras. Additionally, the integrity of LiDAR and camera data is often compromised by adverse environmental conditions such as inclement weather, leading to occlusions and noise interference. To address this challenge, we introduce MultiCorrupt, a comprehensive benchmark designed to evaluate the robustness of multi-modal 3D object detectors against ten distinct types of corruptions. We evaluate five state-of-the-art multi-modal detectors on MultiCorrupt and analyze their performance in terms of their resistance ability. Our results show that existing methods exhibit varying degrees of robustness depending on the type of corruption and their fusion strategy. We provide insights into which multi-modal design choices make such models robust against certain perturbations. The dataset generation code and benchmark are open-sourced at https://github.com/ika-rwth-aachen/MultiCorrupt.
3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods
Feb 18, 2024Storing and transmitting LiDAR point cloud data is essential for many AV applications, such as training data collection, remote control, cloud services or SLAM. However, due to the sparsity and unordered structure of the data, it is difficult to compress point cloud data to a low volume. Transforming the raw point cloud data into a dense 2D matrix structure is a promising way for applying compression algorithms. We propose a new lossless and calibrated 3D-to-2D transformation which allows compression algorithms to efficiently exploit spatial correlations within the 2D representation. To compress the structured representation, we use common image compression methods and also a self-supervised deep compression approach using a recurrent neural network. We also rearrange the LiDAR's intensity measurements to a dense 2D representation and propose a new metric to evaluate the compression performance of the intensity. Compared to approaches that are based on generic octree point cloud compression or based on raw point cloud data compression, our approach achieves the best quantitative and visual performance. Source code and dataset are available at https://github.com/ika-rwth-aachen/Point-Cloud-Compression.
* Code: https://github.com/ika-rwth-aachen/Point-Cloud-Compression
Enhancing Lidar-based Object Detection in Adverse Weather using Offset Sequences in Time
Jan 17, 2024Automated vehicles require an accurate perception of their surroundings for safe and efficient driving. Lidar-based object detection is a widely used method for environment perception, but its performance is significantly affected by adverse weather conditions such as rain and fog. In this work, we investigate various strategies for enhancing the robustness of lidar-based object detection by processing sequential data samples generated by lidar sensors. Our approaches leverage temporal information to improve a lidar object detection model, without the need for additional filtering or pre-processing steps. We compare $10$ different neural network architectures that process point cloud sequences including a novel augmentation strategy introducing a temporal offset between frames of a sequence during training and evaluate the effectiveness of all strategies on lidar point clouds under adverse weather conditions through experiments. Our research provides a comprehensive study of effective methods for mitigating the effects of adverse weather on the reliability of lidar-based object detection using sequential data that are evaluated using public datasets such as nuScenes, Dense, and the Canadian Adverse Driving Conditions Dataset. Our findings demonstrate that our novel method, involving temporal offset augmentation through randomized frame skipping in sequences, enhances object detection accuracy compared to both the baseline model (Pillar-based Object Detection) and no augmentation.