 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Advancing Ocean State Estimation with efficient and scalable AI
Nov 08, 2025Accurate and efficient global ocean state estimation remains a grand challenge for Earth system science, hindered by the dual bottlenecks of computational scalability and degraded data fidelity in traditional data assimilation (DA) and deep learning (DL) approaches. Here we present an AI-driven Data Assimilation Framework for Ocean (ADAF-Ocean) that directly assimilates multi-source and multi-scale observations, ranging from sparse in-situ measurements to 4 km satellite swaths, without any interpolation or data thinning. Inspired by Neural Processes, ADAF-Ocean learns a continuous mapping from heterogeneous inputs to ocean states, preserving native data fidelity. Through AI-driven super-resolution, it reconstructs 0.25$^\circ$ mesoscale dynamics from coarse 1$^\circ$ fields, which ensures both efficiency and scalability, with just 3.7\% more parameters than the 1$^\circ$ configuration. When coupled with a DL forecasting system, ADAF-Ocean extends global forecast skill by up to 20 days compared to baselines without assimilation. This framework establishes a computationally viable and scientifically rigorous pathway toward real-time, high-resolution Earth system monitoring.
Pose State Perception of Interventional Robot for Cardio-cerebrovascular Procedures
Jun 17, 2025In response to the increasing demand for cardiocerebrovascular interventional surgeries, precise control of interventional robots has become increasingly important. Within these complex vascular scenarios, the accurate and reliable perception of the pose state for interventional robots is particularly crucial. This paper presents a novel vision-based approach without the need of additional sensors or markers. The core of this paper's method consists of a three-part framework: firstly, a dual-head multitask U-Net model for simultaneous vessel segment and interventional robot detection; secondly, an advanced algorithm for skeleton extraction and optimization; and finally, a comprehensive pose state perception system based on geometric features is implemented to accurately identify the robot's pose state and provide strategies for subsequent control. The experimental results demonstrate the proposed method's high reliability and accuracy in trajectory tracking and pose state perception.
CLIP-AE: CLIP-assisted Cross-view Audio-Visual Enhancement for Unsupervised Temporal Action Localization
May 29, 2025Temporal Action Localization (TAL) has garnered significant attention in information retrieval. Existing supervised or weakly supervised methods heavily rely on labeled temporal boundaries and action categories, which are labor-intensive and time-consuming. Consequently, unsupervised temporal action localization (UTAL) has gained popularity. However, current methods face two main challenges: 1) Classification pre-trained features overly focus on highly discriminative regions; 2) Solely relying on visual modality information makes it difficult to determine contextual boundaries. To address these issues, we propose a CLIP-assisted cross-view audiovisual enhanced UTAL method. Specifically, we introduce visual language pre-training (VLP) and classification pre-training-based collaborative enhancement to avoid excessive focus on highly discriminative regions; we also incorporate audio perception to provide richer contextual boundary information. Finally, we introduce a self-supervised cross-view learning paradigm to achieve multi-view perceptual enhancement without additional annotations. Extensive experiments on two public datasets demonstrate our model's superiority over several state-of-the-art competitors.
IMDPrompter: Adapting SAM to Image Manipulation Detection by Cross-View Automated Prompt Learning
Feb 04, 2025Using extensive training data from SA-1B, the Segment Anything Model (SAM) has demonstrated exceptional generalization and zero-shot capabilities, attracting widespread attention in areas such as medical image segmentation and remote sensing image segmentation. However, its performance in the field of image manipulation detection remains largely unexplored and unconfirmed. There are two main challenges in applying SAM to image manipulation detection: a) reliance on manual prompts, and b) the difficulty of single-view information in supporting cross-dataset generalization. To address these challenges, we develops a cross-view prompt learning paradigm called IMDPrompter based on SAM. Benefiting from the design of automated prompts, IMDPrompter no longer relies on manual guidance, enabling automated detection and localization. Additionally, we propose components such as Cross-view Feature Perception, Optimal Prompt Selection, and Cross-View Prompt Consistency, which facilitate cross-view perceptual learning and guide SAM to generate accurate masks. Extensive experimental results from five datasets (CASIA, Columbia, Coverage, IMD2020, and NIST16) validate the effectiveness of our proposed method.
Rethinking Pseudo-Label Guided Learning for Weakly Supervised Temporal Action Localization from the Perspective of Noise Correction
Jan 19, 2025



Pseudo-label learning methods have been widely applied in weakly-supervised temporal action localization. Existing works directly utilize weakly-supervised base model to generate instance-level pseudo-labels for training the fully-supervised detection head. We argue that the noise in pseudo-labels would interfere with the learning of fully-supervised detection head, leading to significant performance leakage. Issues with noisy labels include:(1) inaccurate boundary localization; (2) undetected short action clips; (3) multiple adjacent segments incorrectly detected as one segment. To target these issues, we introduce a two-stage noisy label learning strategy to harness every potential useful signal in noisy labels. First, we propose a frame-level pseudo-label generation model with a context-aware denoising algorithm to refine the boundaries. Second, we introduce an online-revised teacher-student framework with a missing instance compensation module and an ambiguous instance correction module to solve the short-action-missing and many-to-one problems. Besides, we apply a high-quality pseudo-label mining loss in our online-revised teacher-student framework to add different weights to the noisy labels to train more effectively. Our model outperforms the previous state-of-the-art method in detection accuracy and inference speed greatly upon the THUMOS14 and ActivityNet v1.2 benchmarks.
Can MLLMs Guide Weakly-Supervised Temporal Action Localization Tasks?
Nov 13, 2024


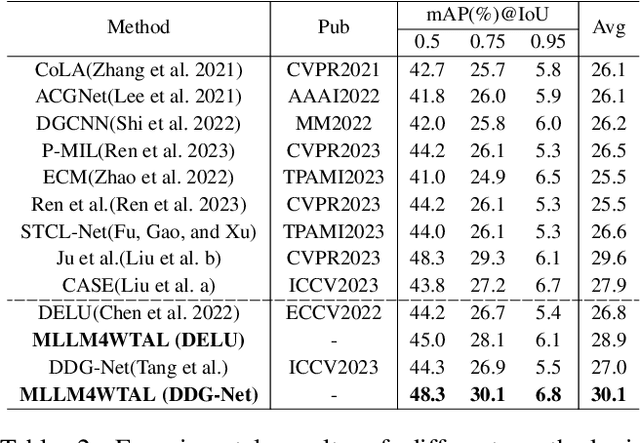
Recent breakthroughs in Multimodal Large Language Models (MLLMs) have gained significant recognition within the deep learning community, where the fusion of the Video Foundation Models (VFMs) and Large Language Models(LLMs) has proven instrumental in constructing robust video understanding systems, effectively surmounting constraints associated with predefined visual tasks. These sophisticated MLLMs exhibit remarkable proficiency in comprehending videos, swiftly attaining unprecedented performance levels across diverse benchmarks. However, their operation demands substantial memory and computational resources, underscoring the continued importance of traditional models in video comprehension tasks. In this paper, we introduce a novel learning paradigm termed MLLM4WTAL. This paradigm harnesses the potential of MLLM to offer temporal action key semantics and complete semantic priors for conventional Weakly-supervised Temporal Action Localization (WTAL) methods. MLLM4WTAL facilitates the enhancement of WTAL by leveraging MLLM guidance. It achieves this by integrating two distinct modules: Key Semantic Matching (KSM) and Complete Semantic Reconstruction (CSR). These modules work in tandem to effectively address prevalent issues like incomplete and over-complete outcomes common in WTAL methods. Rigorous experiments are conducted to validate the efficacy of our proposed approach in augmenting the performance of various heterogeneous WTAL models.
Development of a Simple and Novel Digital Twin Framework for Industrial Robots in Intelligent robotics manufacturing
Oct 19, 2024



This paper has proposed an easily replicable and novel approach for developing a Digital Twin (DT) system for industrial robots in intelligent manufacturing applications. Our framework enables effective communication via Robot Web Service (RWS), while a real-time simulation is implemented in Unity 3D and Web-based Platform without any other 3rd party tools. The framework can do real-time visualization and control of the entire work process, as well as implement real-time path planning based on algorithms executed in MATLAB. Results verify the high communication efficiency with a refresh rate of only $17 ms$. Furthermore, our developed web-based platform and Graphical User Interface (GUI) enable easy accessibility and user-friendliness in real-time control.
A Novel Approach to Grasping Control of Soft Robotic Grippers based on Digital Twin
Oct 19, 2024



This paper has proposed a Digital Twin (DT) framework for real-time motion and pose control of soft robotic grippers. The developed DT is based on an industrial robot workstation, integrated with our newly proposed approach for soft gripper control, primarily based on computer vision, for setting the driving pressure for desired gripper status in real-time. Knowing the gripper motion, the gripper parameters (e.g. curvatures and bending angles, etc.) are simulated by kinematics modelling in Unity 3D, which is based on four-piecewise constant curvature kinematics. The mapping in between the driving pressure and gripper parameters is achieved by implementing OpenCV based image processing algorithms and data fitting. Results show that our DT-based approach can achieve satisfactory performance in real-time control of soft gripper manipulation, which can satisfy a wide range of industrial applications.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024
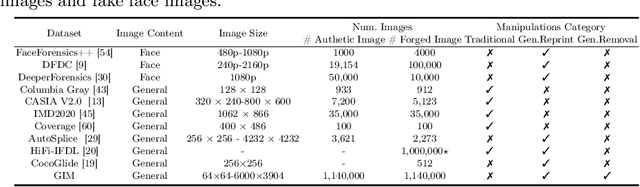
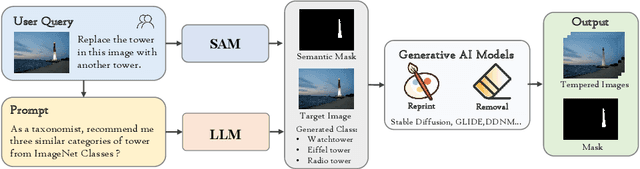
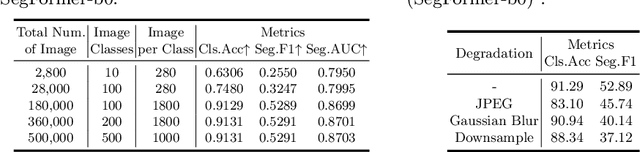
The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.