 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Latent Reasoning via Hierarchical Visual Cues Injection
Feb 05, 2026The advancement of multimodal large language models (MLLMs) has enabled impressive perception capabilities. However, their reasoning process often remains a "fast thinking" paradigm, reliant on end-to-end generation or explicit, language-centric chains of thought (CoT), which can be inefficient, verbose, and prone to hallucination. This work posits that robust reasoning should evolve within a latent space, integrating multimodal signals seamlessly. We propose multimodal latent reasoning via HIerarchical Visual cuEs injection (\emph{HIVE}), a novel framework that instills deliberate, "slow thinking" without depending on superficial textual rationales. Our method recursively extends transformer blocks, creating an internal loop for iterative reasoning refinement. Crucially, it injectively grounds this process with hierarchical visual cues from global scene context to fine-grained regional details directly into the model's latent representations. This enables the model to perform grounded, multi-step inference entirely in the aligned latent space. Extensive evaluations demonstrate that test-time scaling is effective when incorporating vision knowledge, and that integrating hierarchical information significantly enhances the model's understanding of complex scenes.
OmniEval: A Benchmark for Evaluating Omni-modal Models with Visual, Auditory, and Textual Inputs
Jun 26, 2025In this paper, we introduce OmniEval, a benchmark for evaluating omni-modality models like MiniCPM-O 2.6, which encompasses visual, auditory, and textual inputs. Compared with existing benchmarks, our OmniEval has several distinctive features: (i) Full-modal collaboration: We design evaluation tasks that highlight the strong coupling between audio and video, requiring models to effectively leverage the collaborative perception of all modalities; (ii) Diversity of videos: OmniEval includes 810 audio-visual synchronized videos, 285 Chinese videos and 525 English videos; (iii) Diversity and granularity of tasks: OmniEval contains 2617 question-answer pairs, comprising 1412 open-ended questions and 1205 multiple-choice questions. These questions are divided into 3 major task types and 12 sub-task types to achieve comprehensive evaluation. Among them, we introduce a more granular video localization task named Grounding. Then we conduct experiments on OmniEval with several omni-modality models. We hope that our OmniEval can provide a platform for evaluating the ability to construct and understand coherence from the context of all modalities. Codes and data could be found at https://omnieval.github.io/.
EAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025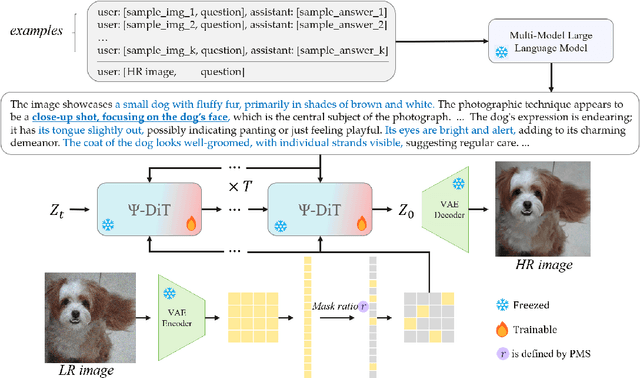
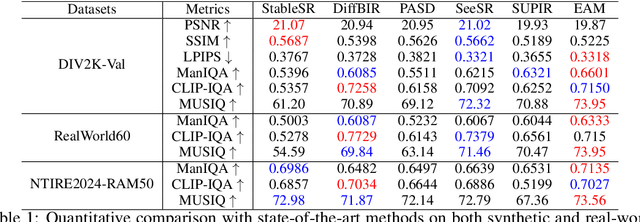
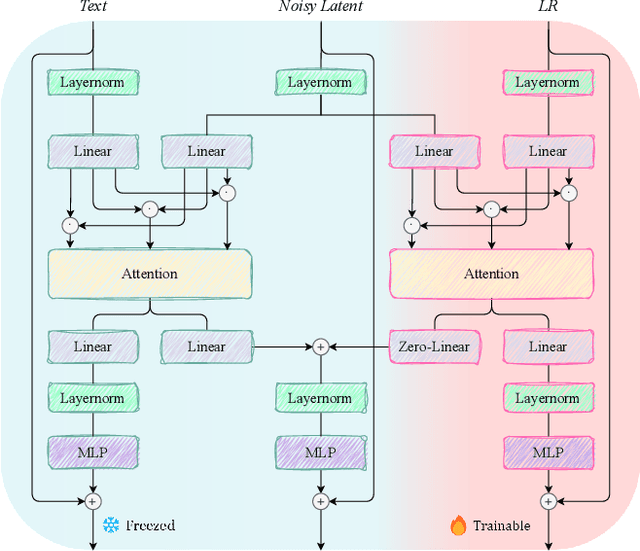

Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
Jan 20, 2025



The rapid advancement of video generation models has made it increasingly challenging to distinguish AI-generated videos from real ones. This issue underscores the urgent need for effective AI-generated video detectors to prevent the dissemination of false information through such videos. However, the development of high-performance generative video detectors is currently impeded by the lack of large-scale, high-quality datasets specifically designed for generative video detection. To this end, we introduce GenVidBench, a challenging AI-generated video detection dataset with several key advantages: 1) Cross Source and Cross Generator: The cross-generation source mitigates the interference of video content on the detection. The cross-generator ensures diversity in video attributes between the training and test sets, preventing them from being overly similar. 2) State-of-the-Art Video Generators: The dataset includes videos from 8 state-of-the-art AI video generators, ensuring that it covers the latest advancements in the field of video generation. 3) Rich Semantics: The videos in GenVidBench are analyzed from multiple dimensions and classified into various semantic categories based on their content. This classification ensures that the dataset is not only large but also diverse, aiding in the development of more generalized and effective detection models. We conduct a comprehensive evaluation of different advanced video generators and present a challenging setting. Additionally, we present rich experimental results including advanced video classification models as baselines. With the GenVidBench, researchers can efficiently develop and evaluate AI-generated video detection models. Datasets and code are available at https://genvidbench.github.io.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024
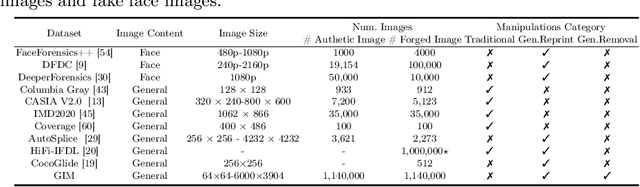
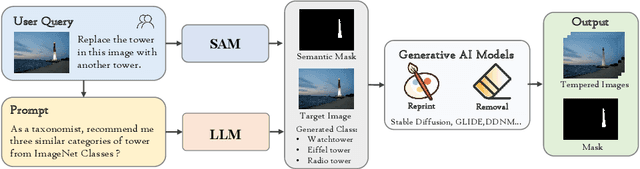
The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Jun 24, 2023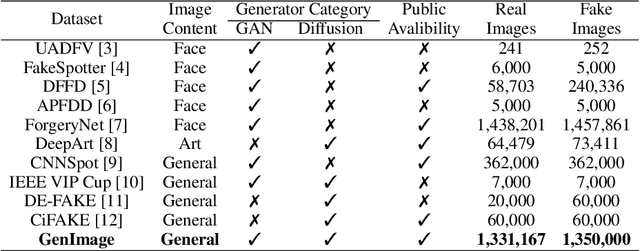

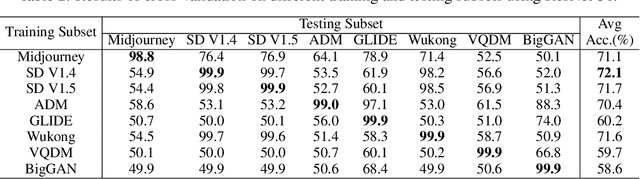
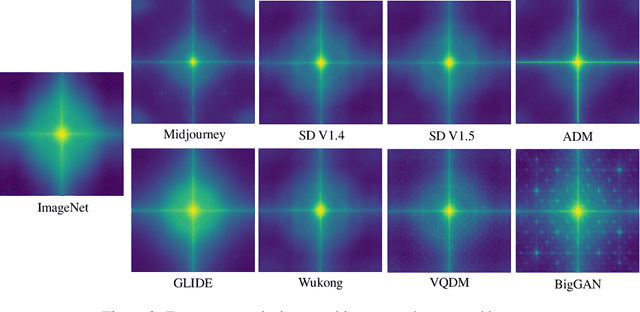
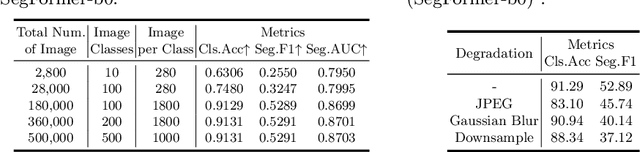
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can effectively expedite the development and evaluation of superior AI-generated image detectors in comparison to prevailing methodologies.