 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025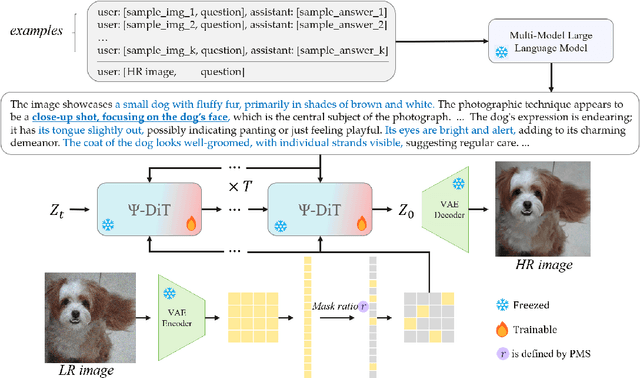
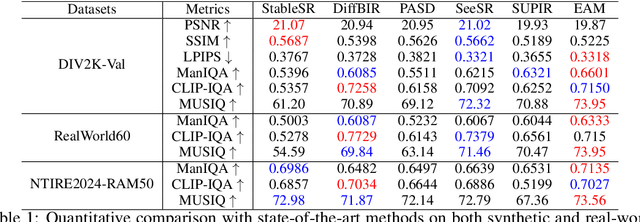
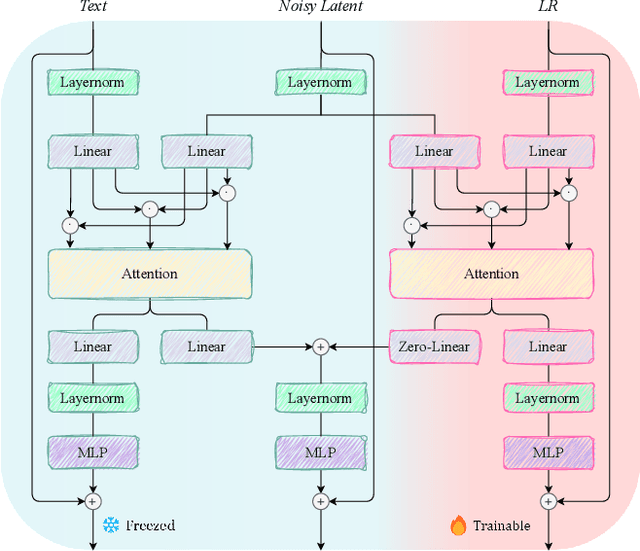

Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
LIPT: Latency-aware Image Processing Transformer
Apr 09, 2024Transformer is leading a trend in the field of image processing. Despite the great success that existing lightweight image processing transformers have achieved, they are tailored to FLOPs or parameters reduction, rather than practical inference acceleration. In this paper, we present a latency-aware image processing transformer, termed LIPT. We devise the low-latency proportion LIPT block that substitutes memory-intensive operators with the combination of self-attention and convolutions to achieve practical speedup. Specifically, we propose a novel non-volatile sparse masking self-attention (NVSM-SA) that utilizes a pre-computing sparse mask to capture contextual information from a larger window with no extra computation overload. Besides, a high-frequency reparameterization module (HRM) is proposed to make LIPT block reparameterization friendly, which improves the model's detail reconstruction capability. Extensive experiments on multiple image processing tasks (e.g., image super-resolution (SR), JPEG artifact reduction, and image denoising) demonstrate the superiority of LIPT on both latency and PSNR. LIPT achieves real-time GPU inference with state-of-the-art performance on multiple image SR benchmarks.