 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025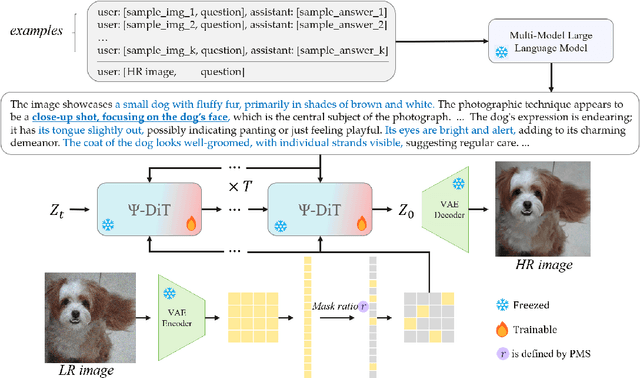
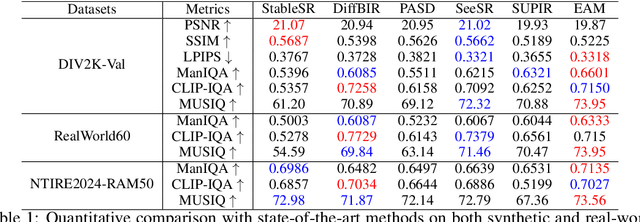
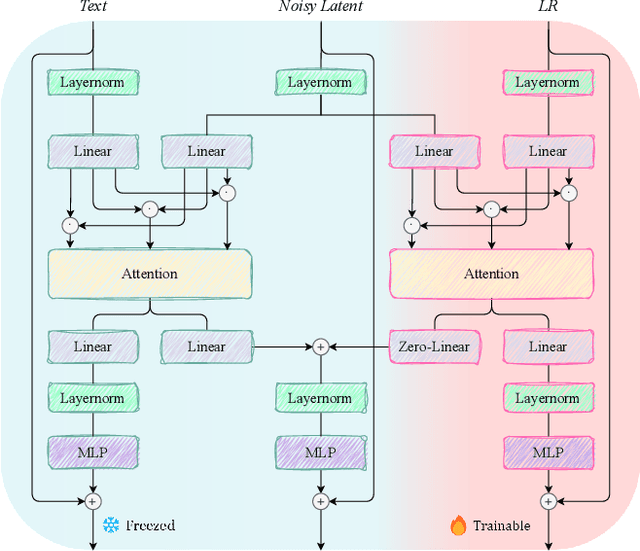

Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
Style-Adaptive Detection Transformer for Single-Source Domain Generalized Object Detection
Apr 29, 2025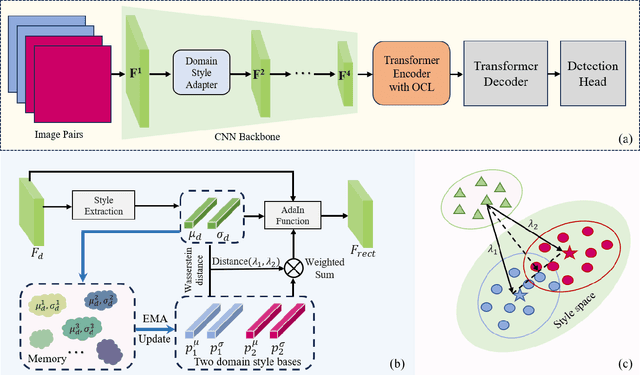
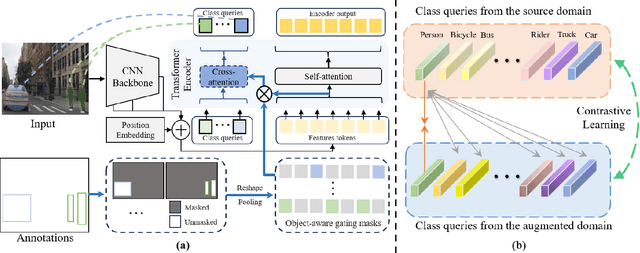
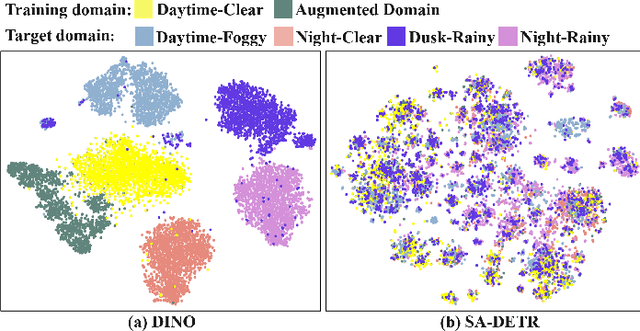
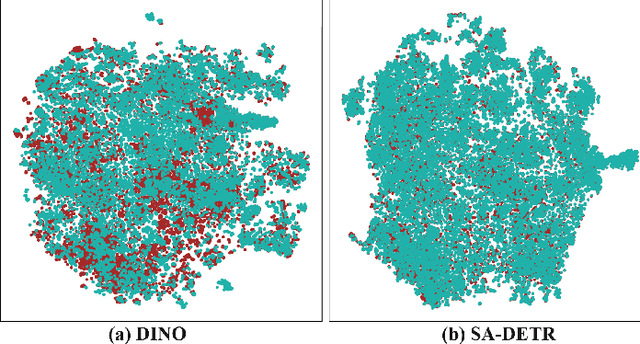
Single-source Domain Generalization (SDG) in object detection aims to develop a detector using only data from a source domain that can exhibit strong generalization capability when applied to unseen target domains. Existing methods are built upon CNN-based detectors and primarily improve robustness by employing carefully designed data augmentation strategies integrated with feature alignment techniques. However, data augmentation methods have inherent drawbacks; they are only effective when the augmented sample distribution approximates or covers the unseen scenarios, thus failing to enhance generalization across all unseen domains. Furthermore, while the recent Detection Transformer (DETR) has demonstrated superior generalization capability in domain adaptation tasks due to its efficient global information extraction, its potential in SDG tasks remains unexplored. To this end, we introduce a strong DETR-based detector named the Style-Adaptive Detection Transformer (SA-DETR) for SDG in object detection. Specifically, we present a domain style adapter that projects the style representation of the unseen target domain into the training domain, enabling dynamic style adaptation. Then, we propose an object-aware contrastive learning module to guide the detector in extracting domain-invariant features through contrastive learning. By using object-aware gating masks to constrain feature aggregation in both spatial and semantic dimensions, this module achieves cross-domain contrast of instance-level features, thereby enhancing generalization. Extensive experiments demonstrate the superior performance and generalization capability of SA-DETR across five different weather scenarios. Code is released at https://github.com/h751410234/SA-DETR.
Neural-Polyptych: Content Controllable Painting Recreation for Diverse Genres
Sep 29, 2024
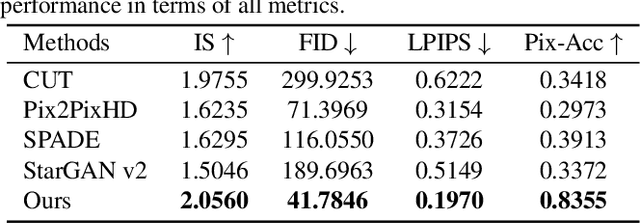
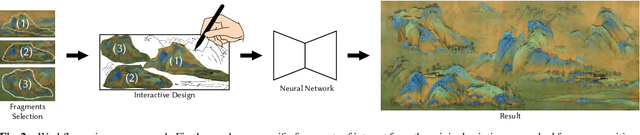
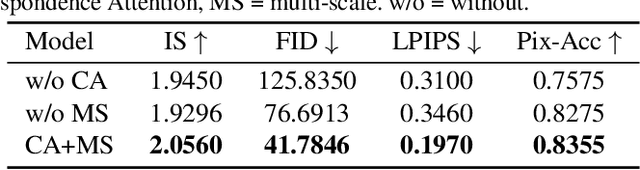
To bridge the gap between artists and non-specialists, we present a unified framework, Neural-Polyptych, to facilitate the creation of expansive, high-resolution paintings by seamlessly incorporating interactive hand-drawn sketches with fragments from original paintings. We have designed a multi-scale GAN-based architecture to decompose the generation process into two parts, each responsible for identifying global and local features. To enhance the fidelity of semantic details generated from users' sketched outlines, we introduce a Correspondence Attention module utilizing our Reference Bank strategy. This ensures the creation of high-quality, intricately detailed elements within the artwork. The final result is achieved by carefully blending these local elements while preserving coherent global consistency. Consequently, this methodology enables the production of digital paintings at megapixel scale, accommodating diverse artistic expressions and enabling users to recreate content in a controlled manner. We validate our approach to diverse genres of both Eastern and Western paintings. Applications such as large painting extension, texture shuffling, genre switching, mural art restoration, and recomposition can be successfully based on our framework.
Instruct-IPT: All-in-One Image Processing Transformer via Weight Modulation
Jun 30, 2024



Due to the unaffordable size and intensive computation costs of low-level vision models, All-in-One models that are designed to address a handful of low-level vision tasks simultaneously have been popular. However, existing All-in-One models are limited in terms of the range of tasks and performance. To overcome these limitations, we propose Instruct-IPT -- an All-in-One Image Processing Transformer that could effectively address manifold image restoration tasks with large inter-task gaps, such as denoising, deblurring, deraining, dehazing, and desnowing. Rather than popular feature adaptation methods, we propose weight modulation that adapts weights to specific tasks. Firstly, we figure out task-sensitive weights via a toy experiment and introduce task-specific biases on top of them. Secondly, we conduct rank analysis for a good compression strategy and perform low-rank decomposition on the biases. Thirdly, we propose synchronous training that updates the task-general backbone model and the task-specific biases simultaneously. In this way, the model is instructed to learn general and task-specific knowledge. Via our simple yet effective method that instructs the IPT to be task experts, Instruct-IPT could better cooperate between tasks with distinct characteristics at humble costs. Further, we propose to maneuver Instruct-IPT with text instructions for better user interfaces. We have conducted experiments on Instruct-IPT to demonstrate the effectiveness of our method on manifold tasks, and we have effectively extended our method to diffusion denoisers as well. The code is available at https://github.com/huawei-noah/Pretrained-IPT.
DATR: Unsupervised Domain Adaptive Detection Transformer with Dataset-Level Adaptation and Prototypical Alignment
May 20, 2024



Object detectors frequently encounter significant performance degradation when confronted with domain gaps between collected data (source domain) and data from real-world applications (target domain). To address this task, numerous unsupervised domain adaptive detectors have been proposed, leveraging carefully designed feature alignment techniques. However, these techniques primarily align instance-level features in a class-agnostic manner, overlooking the differences between extracted features from different categories, which results in only limited improvement. Furthermore, the scope of current alignment modules is often restricted to a limited batch of images, failing to learn the entire dataset-level cues, thereby severely constraining the detector's generalization ability to the target domain. To this end, we introduce a strong DETR-based detector named Domain Adaptive detection TRansformer (DATR) for unsupervised domain adaptation of object detection. Firstly, we propose the Class-wise Prototypes Alignment (CPA) module, which effectively aligns cross-domain features in a class-aware manner by bridging the gap between object detection task and domain adaptation task. Then, the designed Dataset-level Alignment Scheme (DAS) explicitly guides the detector to achieve global representation and enhance inter-class distinguishability of instance-level features across the entire dataset, which spans both domains, by leveraging contrastive learning. Moreover, DATR incorporates a mean-teacher based self-training framework, utilizing pseudo-labels generated by the teacher model to further mitigate domain bias. Extensive experimental results demonstrate superior performance and generalization capabilities of our proposed DATR in multiple domain adaptation scenarios. Code is released at https://github.com/h751410234/DATR.
SparseDet: Towards End-to-End 3D Object Detection
Jun 02, 2022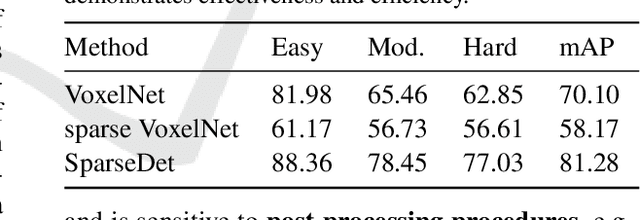
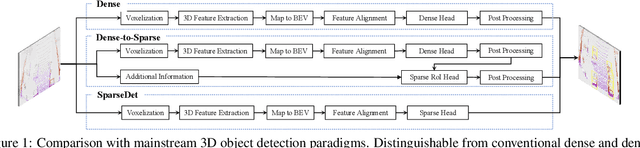
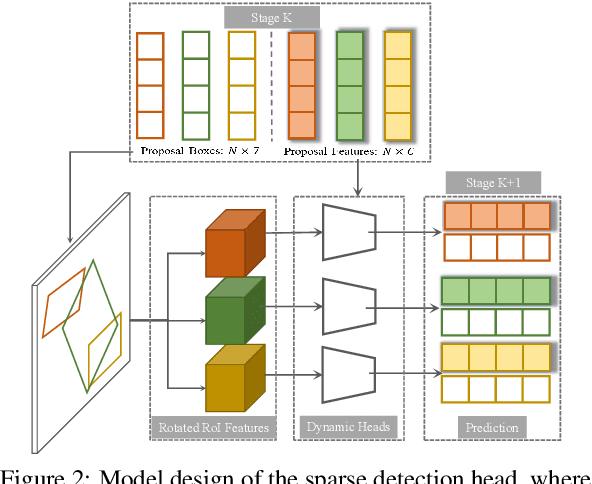
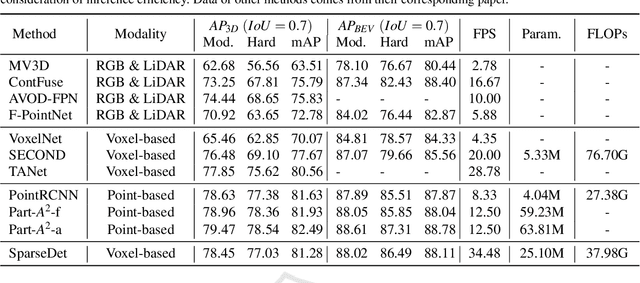
In this paper, we propose SparseDet for end-to-end 3D object detection from point cloud. Existing works on 3D object detection rely on dense object candidates over all locations in a 3D or 2D grid following the mainstream methods for object detection in 2D images. However, this dense paradigm requires expertise in data to fulfill the gap between label and detection. As a new detection paradigm, SparseDet maintains a fixed set of learnable proposals to represent latent candidates and directly perform classification and localization for 3D objects through stacked transformers. It demonstrates that effective 3D object detection can be achieved with none of post-processing such as redundant removal and non-maximum suppression. With a properly designed network, SparseDet achieves highly competitive detection accuracy while running with a more efficient speed of 34.5 FPS. We believe this end-to-end paradigm of SparseDet will inspire new thinking on the sparsity of 3D object detection.