 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseDet: Towards End-to-End 3D Object Detection
Jun 02, 2022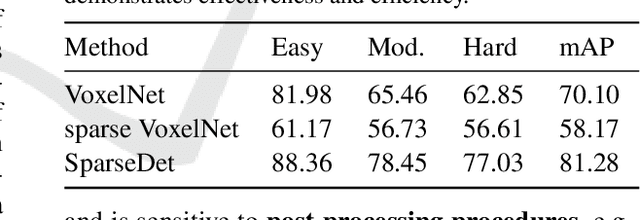
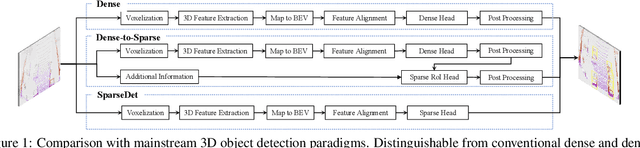
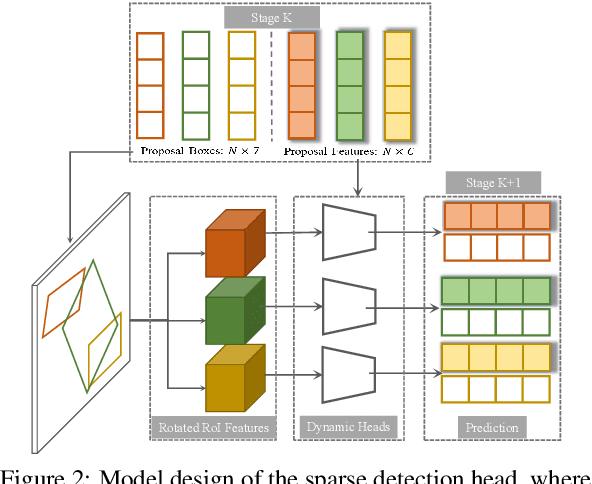
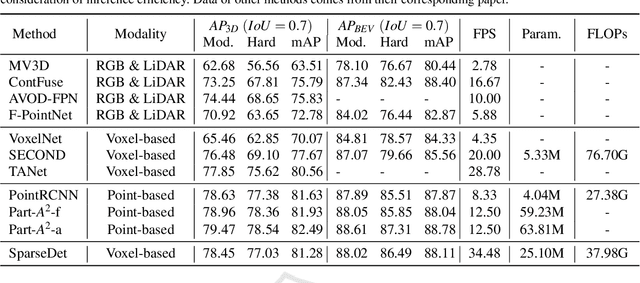
In this paper, we propose SparseDet for end-to-end 3D object detection from point cloud. Existing works on 3D object detection rely on dense object candidates over all locations in a 3D or 2D grid following the mainstream methods for object detection in 2D images. However, this dense paradigm requires expertise in data to fulfill the gap between label and detection. As a new detection paradigm, SparseDet maintains a fixed set of learnable proposals to represent latent candidates and directly perform classification and localization for 3D objects through stacked transformers. It demonstrates that effective 3D object detection can be achieved with none of post-processing such as redundant removal and non-maximum suppression. With a properly designed network, SparseDet achieves highly competitive detection accuracy while running with a more efficient speed of 34.5 FPS. We believe this end-to-end paradigm of SparseDet will inspire new thinking on the sparsity of 3D object detection.
Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
Feb 21, 2022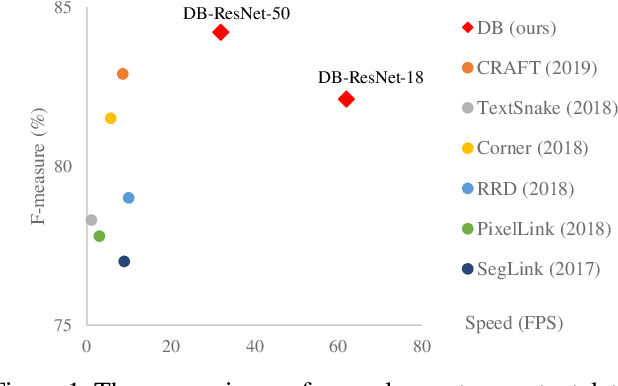
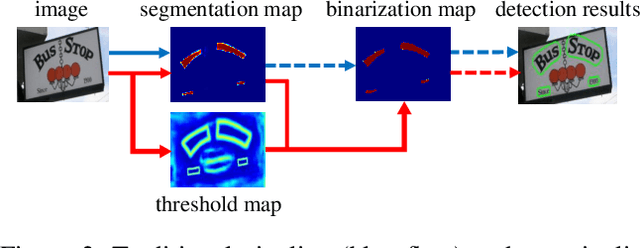
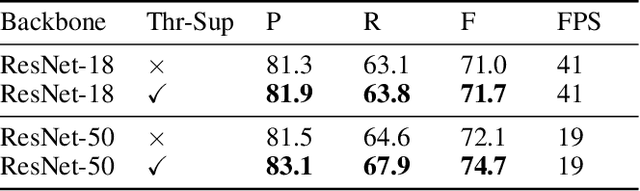
Recently, segmentation-based scene text detection methods have drawn extensive attention in the scene text detection field, because of their superiority in detecting the text instances of arbitrary shapes and extreme aspect ratios, profiting from the pixel-level descriptions. However, the vast majority of the existing segmentation-based approaches are limited to their complex post-processing algorithms and the scale robustness of their segmentation models, where the post-processing algorithms are not only isolated to the model optimization but also time-consuming and the scale robustness is usually strengthened by fusing multi-scale feature maps directly. In this paper, we propose a Differentiable Binarization (DB) module that integrates the binarization process, one of the most important steps in the post-processing procedure, into a segmentation network. Optimized along with the proposed DB module, the segmentation network can produce more accurate results, which enhances the accuracy of text detection with a simple pipeline. Furthermore, an efficient Adaptive Scale Fusion (ASF) module is proposed to improve the scale robustness by fusing features of different scales adaptively. By incorporating the proposed DB and ASF with the segmentation network, our proposed scene text detector consistently achieves state-of-the-art results, in terms of both detection accuracy and speed, on five standard benchmarks.
Facial Attribute Transformers for Precise and Robust Makeup Transfer
Apr 07, 2021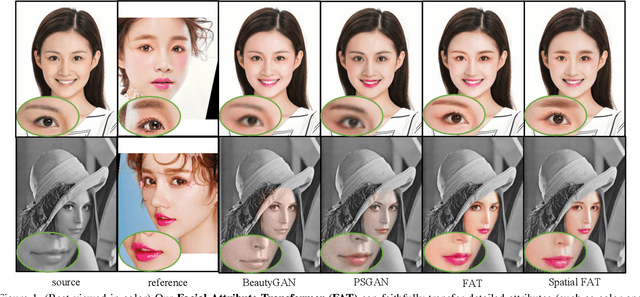

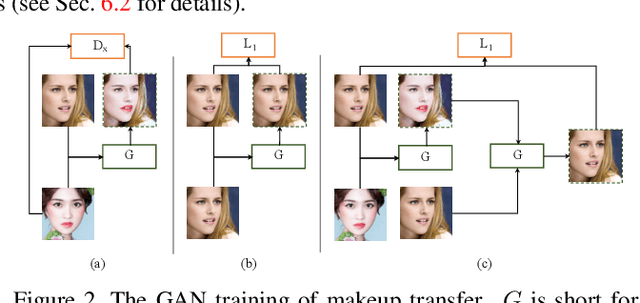
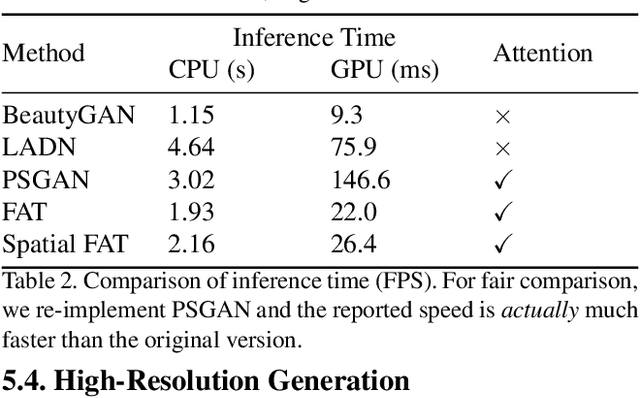
In this paper, we address the problem of makeup transfer, which aims at transplanting the makeup from the reference face to the source face while preserving the identity of the source. Existing makeup transfer methods have made notable progress in generating realistic makeup faces, but do not perform well in terms of color fidelity and spatial transformation. To tackle these issues, we propose a novel Facial Attribute Transformer (FAT) and its variant Spatial FAT for high-quality makeup transfer. Drawing inspirations from the Transformer in NLP, FAT is able to model the semantic correspondences and interactions between the source face and reference face, and then precisely estimate and transfer the facial attributes. To further facilitate shape deformation and transformation of facial parts, we also integrate thin plate splines (TPS) into FAT, thus creating Spatial FAT, which is the first method that can transfer geometric attributes in addition to color and texture. Extensive qualitative and quantitative experiments demonstrate the effectiveness and superiority of our proposed FATs in the following aspects: (1) ensuring high-fidelity color transfer; (2) allowing for geometric transformation of facial parts; (3) handling facial variations (such as poses and shadows) and (4) supporting high-resolution face generation.
Slender Object Detection: Diagnoses and Improvements
Nov 21, 2020


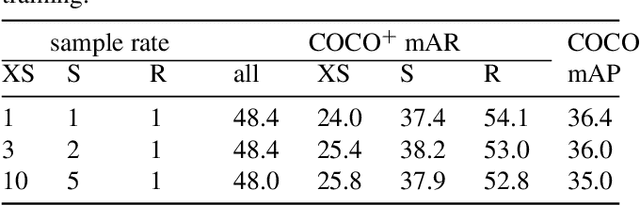
In this paper, we are concerned with the detection of a particular type of objects with extreme aspect ratios, namely slender objects. In real-world scenarios as well as widely-used datasets (such as COCO), slender objects are actually very common. However, this type of object has been largely overlooked by previous object detection algorithms. Upon our investigation, for a classical object detection method, a drastic drop of 18.9% mAP on COCO is observed, if solely evaluated on slender objects. Therefore, We systematically study the problem of slender object detection in this work. Accordingly, an analytical framework with carefully designed benchmark and evaluation protocols is established, in which different algorithms and modules can be inspected and compared. Our key findings include: 1) the essential role of anchors in label assignment; 2) the descriptive capability of the 2-point representation; 3) the crucial strategies for improving the detection of slender objects and regular objects. Our work identifies and extends the insights of existing methods that are previously underexploited. Furthermore, we propose a feature adaption strategy that achieves clear and consistent improvements over current representative object detection methods. In particular, a natural and effective extension of the center prior, which leads to a significant improvement on slender objects, is devised. We believe this work opens up new opportunities and calibrates ablation standards for future research in the field of object detection.
On Vocabulary Reliance in Scene Text Recognition
May 08, 2020
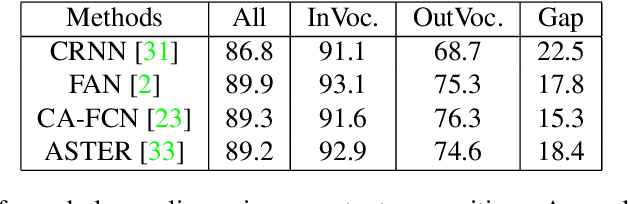
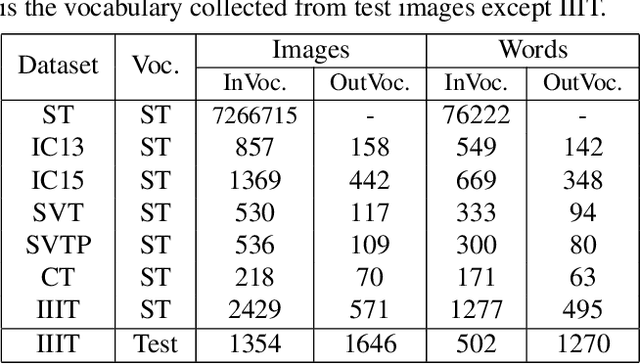

The pursuit of high performance on public benchmarks has been the driving force for research in scene text recognition, and notable progress has been achieved. However, a close investigation reveals a startling fact that the state-of-the-art methods perform well on images with words within vocabulary but generalize poorly to images with words outside vocabulary. We call this phenomenon "vocabulary reliance". In this paper, we establish an analytical framework to conduct an in-depth study on the problem of vocabulary reliance in scene text recognition. Key findings include: (1) Vocabulary reliance is ubiquitous, i.e., all existing algorithms more or less exhibit such characteristic; (2) Attention-based decoders prove weak in generalizing to words outside vocabulary and segmentation-based decoders perform well in utilizing visual features; (3) Context modeling is highly coupled with the prediction layers. These findings provide new insights and can benefit future research in scene text recognition. Furthermore, we propose a simple yet effective mutual learning strategy to allow models of two families (attention-based and segmentation-based) to learn collaboratively. This remedy alleviates the problem of vocabulary reliance and improves the overall scene text recognition performance.
* CVPR'20
TextScanner: Reading Characters in Order for Robust Scene Text Recognition
Jan 01, 2020
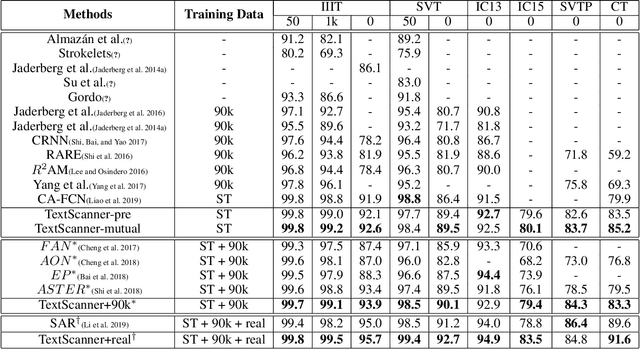
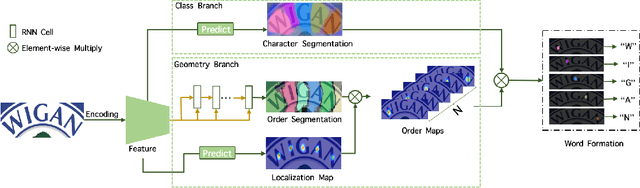
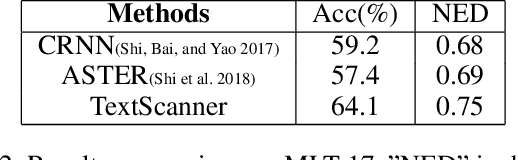
Driven by deep learning and the large volume of data, scene text recognition has evolved rapidly in recent years. Formerly, RNN-attention based methods have dominated this field, but suffer from the problem of \textit{attention drift} in certain situations. Lately, semantic segmentation based algorithms have proven effective at recognizing text of different forms (horizontal, oriented and curved). However, these methods may produce spurious characters or miss genuine characters, as they rely heavily on a thresholding procedure operated on segmentation maps. To tackle these challenges, we propose in this paper an alternative approach, called TextScanner, for scene text recognition. TextScanner bears three characteristics: (1) Basically, it belongs to the semantic segmentation family, as it generates pixel-wise, multi-channel segmentation maps for character class, position and order; (2) Meanwhile, akin to RNN-attention based methods, it also adopts RNN for context modeling; (3) Moreover, it performs paralleled prediction for character position and class, and ensures that characters are transcripted in correct order. The experiments on standard benchmark datasets demonstrate that TextScanner outperforms the state-of-the-art methods. Moreover, TextScanner shows its superiority in recognizing more difficult text such Chinese transcripts and aligning with target characters.
Real-time Scene Text Detection with Differentiable Binarization
Dec 03, 2019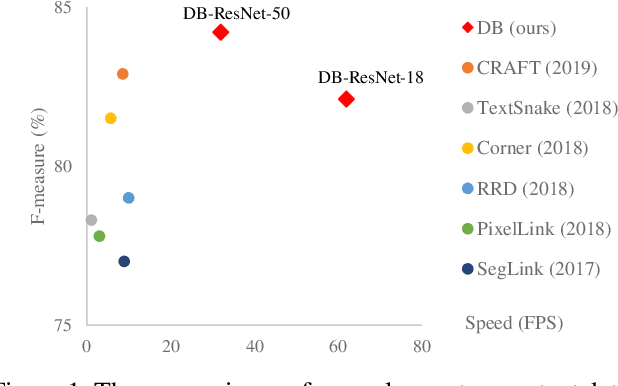
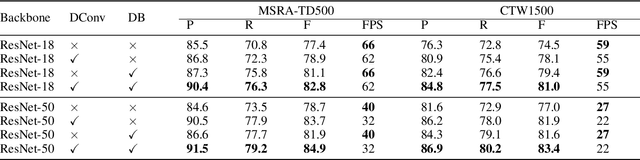
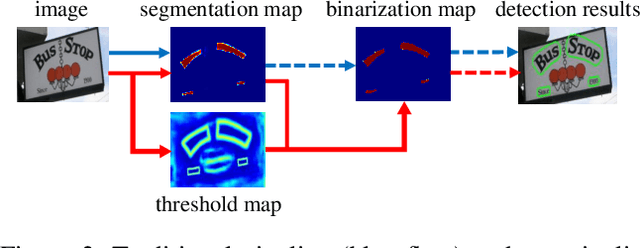
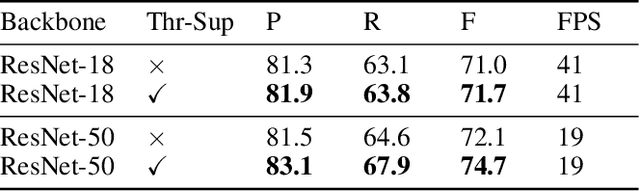
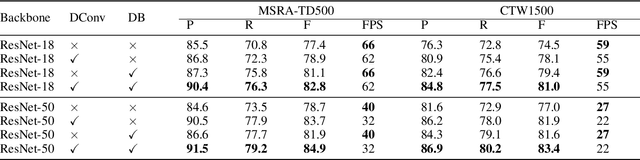
Recently, segmentation-based methods are quite popular in scene text detection, as the segmentation results can more accurately describe scene text of various shapes such as curve text. However, the post-processing of binarization is essential for segmentation-based detection, which converts probability maps produced by a segmentation method into bounding boxes/regions of text. In this paper, we propose a module named Differentiable Binarization (DB), which can perform the binarization process in a segmentation network. Optimized along with a DB module, a segmentation network can adaptively set the thresholds for binarization, which not only simplifies the post-processing but also enhances the performance of text detection. Based on a simple segmentation network, we validate the performance improvements of DB on five benchmark datasets, which consistently achieves state-of-the-art results, in terms of both detection accuracy and speed. In particular, with a light-weight backbone, the performance improvements by DB are significant so that we can look for an ideal tradeoff between detection accuracy and efficiency. Specifically, with a backbone of ResNet-18, our detector achieves an F-measure of 82.8, running at 62 FPS, on the MSRA-TD500 dataset. Code is available at: https://github.com/MhLiao/DB
2D-CTC for Scene Text Recognition
Jul 23, 2019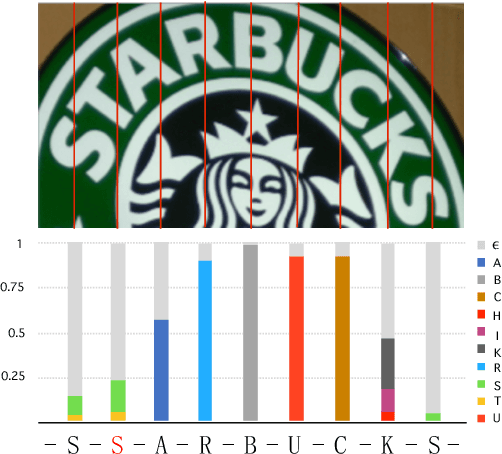
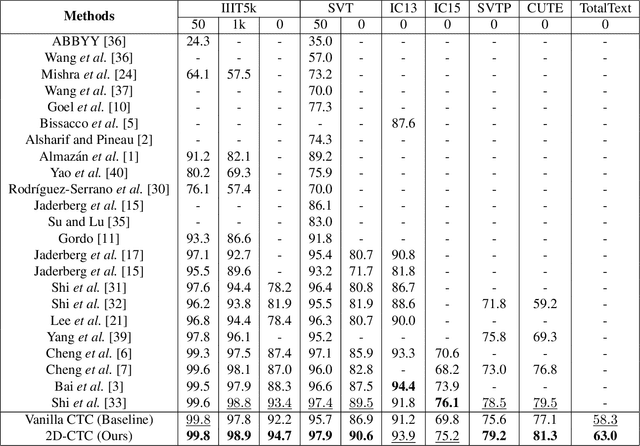
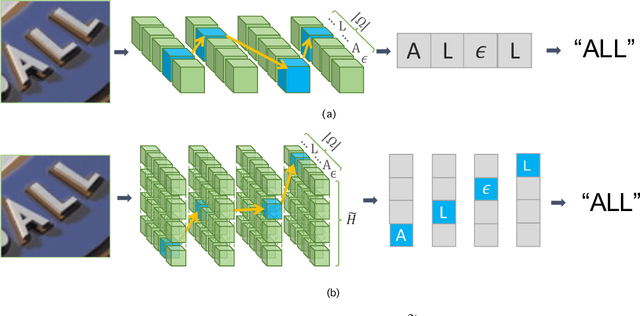

Scene text recognition has been an important, active research topic in computer vision for years. Previous approaches mainly consider text as 1D signals and cast scene text recognition as a sequence prediction problem, by feat of CTC or attention based encoder-decoder framework, which is originally designed for speech recognition. However, different from speech voices, which are 1D signals, text instances are essentially distributed in 2D image spaces. To adhere to and make use of the 2D nature of text for higher recognition accuracy, we extend the vanilla CTC model to a second dimension, thus creating 2D-CTC. 2D-CTC can adaptively concentrate on most relevant features while excluding the impact from clutters and noises in the background; It can also naturally handle text instances with various forms (horizontal, oriented and curved) while giving more interpretable intermediate predictions. The experiments on standard benchmarks for scene text recognition, such as IIIT-5K, ICDAR 2015, SVP-Perspective, and CUTE80, demonstrate that the proposed 2D-CTC model outperforms state-of-the-art methods on the text of both regular and irregular shapes. Moreover, 2D-CTC exhibits its superiority over prior art on training and testing speed. Our implementation and models of 2D-CTC will be made publicly available soon later.
Scene Text Recognition from Two-Dimensional Perspective
Sep 18, 2018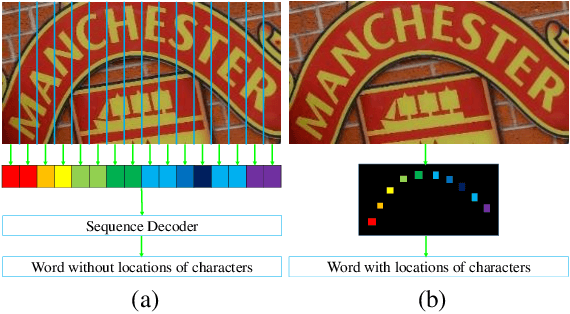
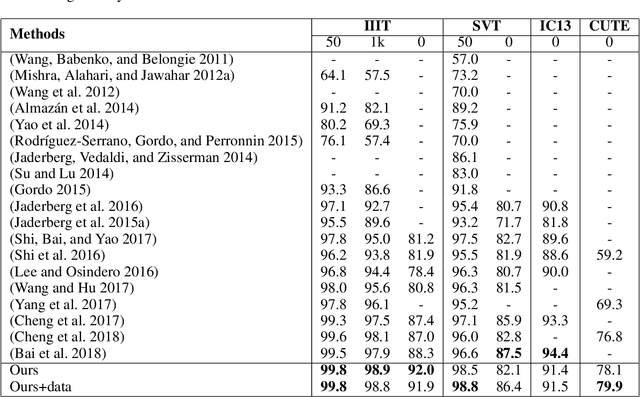
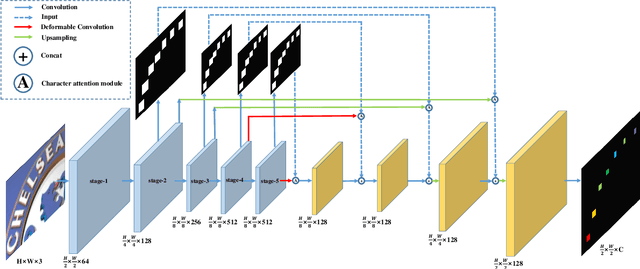

Inspired by speech recognition, recent state-of-the-art algorithms mostly consider scene text recognition as a sequence prediction problem. Though achieving excellent performance, these methods usually neglect an important fact that text in images are actually distributed in two-dimensional space. It is a nature quite different from that of speech, which is essentially a one-dimensional signal. In principle, directly compressing features of text into a one-dimensional form may lose useful information and introduce extra noise. In this paper, we approach scene text recognition from a two-dimensional perspective. A simple yet effective model, called Character Attention Fully Convolutional Network (CA-FCN), is devised for recognizing text of arbitrary shapes. Scene text recognition is realized with a semantic segmentation network, where an attention mechanism for characters is adopted. Combined with a word formation module, CA-FCN can simultaneously recognize the script and predict the position of each character. Experiments demonstrate that the proposed algorithm outperforms previous methods on both regular and irregular text datasets. Moreover, it is proven to be more robust to imprecise localizations in the text detection phase, which are very common in practice.