 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition-Synergistic Scene Text Editing
Mar 11, 2025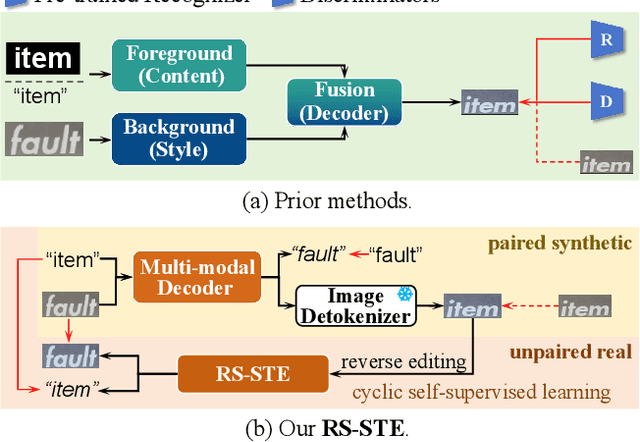
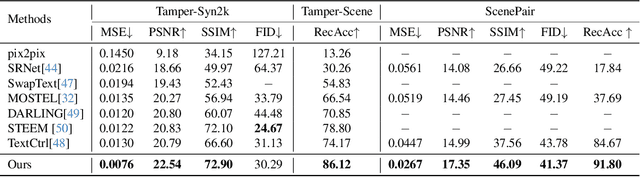
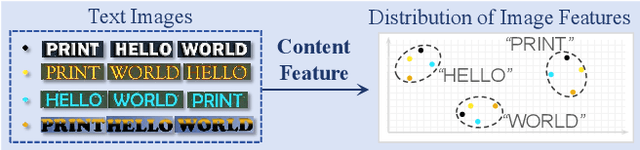
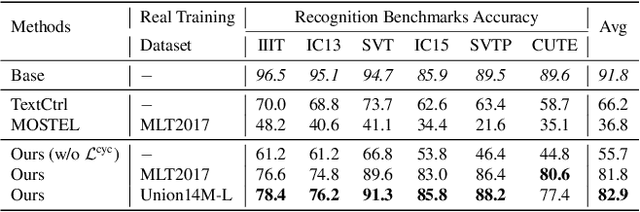
Scene text editing aims to modify text content within scene images while maintaining style consistency. Traditional methods achieve this by explicitly disentangling style and content from the source image and then fusing the style with the target content, while ensuring content consistency using a pre-trained recognition model. Despite notable progress, these methods suffer from complex pipelines, leading to suboptimal performance in complex scenarios. In this work, we introduce Recognition-Synergistic Scene Text Editing (RS-STE), a novel approach that fully exploits the intrinsic synergy of text recognition for editing. Our model seamlessly integrates text recognition with text editing within a unified framework, and leverages the recognition model's ability to implicitly disentangle style and content while ensuring content consistency. Specifically, our approach employs a multi-modal parallel decoder based on transformer architecture, which predicts both text content and stylized images in parallel. Additionally, our cyclic self-supervised fine-tuning strategy enables effective training on unpaired real-world data without ground truth, enhancing style and content consistency through a twice-cyclic generation process. Built on a relatively simple architecture, \mymodel achieves state-of-the-art performance on both synthetic and real-world benchmarks, and further demonstrates the effectiveness of leveraging the generated hard cases to boost the performance of downstream recognition tasks. Code is available at https://github.com/ZhengyaoFang/RS-STE.
R-CoT: Reverse Chain-of-Thought Problem Generation for Geometric Reasoning in Large Multimodal Models
Oct 23, 2024



Existing Large Multimodal Models (LMMs) struggle with mathematical geometric reasoning due to a lack of high-quality image-text paired data. Current geometric data generation approaches, which apply preset templates to generate geometric data or use Large Language Models (LLMs) to rephrase questions and answers (Q&A), unavoidably limit data accuracy and diversity. To synthesize higher-quality data, we propose a two-stage Reverse Chain-of-Thought (R-CoT) geometry problem generation pipeline. First, we introduce GeoChain to produce high-fidelity geometric images and corresponding descriptions highlighting relations among geometric elements. We then design a Reverse A&Q method that reasons step-by-step based on the descriptions and generates questions in reverse from the reasoning results. Experiments demonstrate that the proposed method brings significant and consistent improvements on multiple LMM baselines, achieving new performance records in the 2B, 7B, and 8B settings. Notably, R-CoT-8B significantly outperforms previous state-of-the-art open-source mathematical models by 16.6% on MathVista and 9.2% on GeoQA, while also surpassing the closed-source model GPT-4o by an average of 13% across both datasets. The code is available at https://github.com/dle666/R-CoT.
WeCromCL: Weakly Supervised Cross-Modality Contrastive Learning for Transcription-only Supervised Text Spotting
Jul 28, 2024Transcription-only Supervised Text Spotting aims to learn text spotters relying only on transcriptions but no text boundaries for supervision, thus eliminating expensive boundary annotation. The crux of this task lies in locating each transcription in scene text images without location annotations. In this work, we formulate this challenging problem as a Weakly Supervised Cross-modality Contrastive Learning problem, and design a simple yet effective model dubbed WeCromCL that is able to detect each transcription in a scene image in a weakly supervised manner. Unlike typical methods for cross-modality contrastive learning that focus on modeling the holistic semantic correlation between an entire image and a text description, our WeCromCL conducts atomistic contrastive learning to model the character-wise appearance consistency between a text transcription and its correlated region in a scene image to detect an anchor point for the transcription in a weakly supervised manner. The detected anchor points by WeCromCL are further used as pseudo location labels to guide the learning of text spotting. Extensive experiments on four challenging benchmarks demonstrate the superior performance of our model over other methods. Code will be released.
StrucTexTv3: An Efficient Vision-Language Model for Text-rich Image Perception, Comprehension, and Beyond
Jun 04, 2024Text-rich images have significant and extensive value, deeply integrated into various aspects of human life. Notably, both visual cues and linguistic symbols in text-rich images play crucial roles in information transmission but are accompanied by diverse challenges. Therefore, the efficient and effective understanding of text-rich images is a crucial litmus test for the capability of Vision-Language Models. We have crafted an efficient vision-language model, StrucTexTv3, tailored to tackle various intelligent tasks for text-rich images. The significant design of StrucTexTv3 is presented in the following aspects: Firstly, we adopt a combination of an effective multi-scale reduced visual transformer and a multi-granularity token sampler (MG-Sampler) as a visual token generator, successfully solving the challenges of high-resolution input and complex representation learning for text-rich images. Secondly, we enhance the perception and comprehension abilities of StrucTexTv3 through instruction learning, seamlessly integrating various text-oriented tasks into a unified framework. Thirdly, we have curated a comprehensive collection of high-quality text-rich images, abbreviated as TIM-30M, encompassing diverse scenarios like incidental scenes, office documents, web pages, and screenshots, thereby improving the robustness of our model. Our method achieved SOTA results in text-rich image perception tasks, and significantly improved performance in comprehension tasks. Among multimodal models with LLM decoder of approximately 1.8B parameters, it stands out as a leader, which also makes the deployment of edge devices feasible. In summary, the StrucTexTv3 model, featuring efficient structural design, outstanding performance, and broad adaptability, offers robust support for diverse intelligent application tasks involving text-rich images, thus exhibiting immense potential for widespread application.
Towards Unified Multi-granularity Text Detection with Interactive Attention
May 30, 2024



Existing OCR engines or document image analysis systems typically rely on training separate models for text detection in varying scenarios and granularities, leading to significant computational complexity and resource demands. In this paper, we introduce "Detect Any Text" (DAT), an advanced paradigm that seamlessly unifies scene text detection, layout analysis, and document page detection into a cohesive, end-to-end model. This design enables DAT to efficiently manage text instances at different granularities, including *word*, *line*, *paragraph* and *page*. A pivotal innovation in DAT is the across-granularity interactive attention module, which significantly enhances the representation learning of text instances at varying granularities by correlating structural information across different text queries. As a result, it enables the model to achieve mutually beneficial detection performances across multiple text granularities. Additionally, a prompt-based segmentation module refines detection outcomes for texts of arbitrary curvature and complex layouts, thereby improving DAT's accuracy and expanding its real-world applicability. Experimental results demonstrate that DAT achieves state-of-the-art performances across a variety of text-related benchmarks, including multi-oriented/arbitrarily-shaped scene text detection, document layout analysis and page detection tasks.
GridFormer: Towards Accurate Table Structure Recognition via Grid Prediction
Sep 26, 2023



All tables can be represented as grids. Based on this observation, we propose GridFormer, a novel approach for interpreting unconstrained table structures by predicting the vertex and edge of a grid. First, we propose a flexible table representation in the form of an MXN grid. In this representation, the vertexes and edges of the grid store the localization and adjacency information of the table. Then, we introduce a DETR-style table structure recognizer to efficiently predict this multi-objective information of the grid in a single shot. Specifically, given a set of learned row and column queries, the recognizer directly outputs the vertexes and edges information of the corresponding rows and columns. Extensive experiments on five challenging benchmarks which include wired, wireless, multi-merge-cell, oriented, and distorted tables demonstrate the competitive performance of our model over other methods.
Towards Robust Real-Time Scene Text Detection: From Semantic to Instance Representation Learning
Aug 14, 2023



Due to the flexible representation of arbitrary-shaped scene text and simple pipeline, bottom-up segmentation-based methods begin to be mainstream in real-time scene text detection. Despite great progress, these methods show deficiencies in robustness and still suffer from false positives and instance adhesion. Different from existing methods which integrate multiple-granularity features or multiple outputs, we resort to the perspective of representation learning in which auxiliary tasks are utilized to enable the encoder to jointly learn robust features with the main task of per-pixel classification during optimization. For semantic representation learning, we propose global-dense semantic contrast (GDSC), in which a vector is extracted for global semantic representation, then used to perform element-wise contrast with the dense grid features. To learn instance-aware representation, we propose to combine top-down modeling (TDM) with the bottom-up framework to provide implicit instance-level clues for the encoder. With the proposed GDSC and TDM, the encoder network learns stronger representation without introducing any parameters and computations during inference. Equipped with a very light decoder, the detector can achieve more robust real-time scene text detection. Experimental results on four public datasets show that the proposed method can outperform or be comparable to the state-of-the-art on both accuracy and speed. Specifically, the proposed method achieves 87.2% F-measure with 48.2 FPS on Total-Text and 89.6% F-measure with 36.9 FPS on MSRA-TD500 on a single GeForce RTX 2080 Ti GPU.
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
Decoupling Recognition from Detection: Single Shot Self-Reliant Scene Text Spotter
Jul 18, 2022

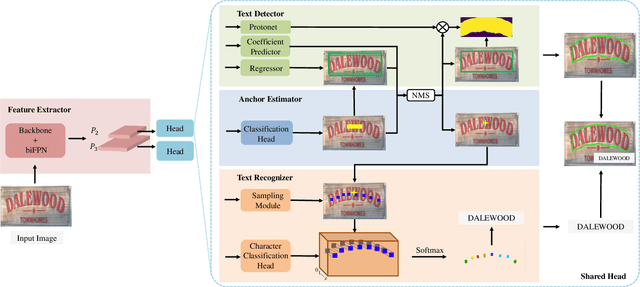

Typical text spotters follow the two-stage spotting strategy: detect the precise boundary for a text instance first and then perform text recognition within the located text region. While such strategy has achieved substantial progress, there are two underlying limitations. 1) The performance of text recognition depends heavily on the precision of text detection, resulting in the potential error propagation from detection to recognition. 2) The RoI cropping which bridges the detection and recognition brings noise from background and leads to information loss when pooling or interpolating from feature maps. In this work we propose the single shot Self-Reliant Scene Text Spotter (SRSTS), which circumvents these limitations by decoupling recognition from detection. Specifically, we conduct text detection and recognition in parallel and bridge them by the shared positive anchor point. Consequently, our method is able to recognize the text instances correctly even though the precise text boundaries are challenging to detect. Additionally, our method reduces the annotation cost for text detection substantially. Extensive experiments on regular-shaped benchmark and arbitrary-shaped benchmark demonstrate that our SRSTS compares favorably to previous state-of-the-art spotters in terms of both accuracy and efficiency.
MaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
Jun 01, 2022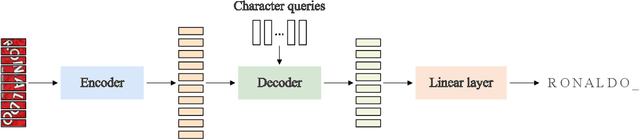

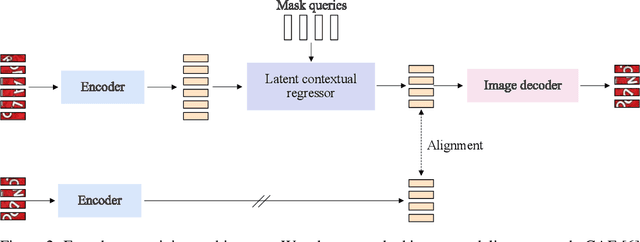

In this paper, we present a model pretraining technique, named MaskOCR, for text recognition. Our text recognition architecture is an encoder-decoder transformer: the encoder extracts the patch-level representations, and the decoder recognizes the text from the representations. Our approach pretrains both the encoder and the decoder in a sequential manner. (i) We pretrain the encoder in a self-supervised manner over a large set of unlabeled real text images. We adopt the masked image modeling approach, which shows the effectiveness for general images, expecting that the representations take on semantics. (ii) We pretrain the decoder over a large set of synthesized text images in a supervised manner and enhance the language modeling capability of the decoder by randomly masking some text image patches occupied by characters input to the encoder and accordingly the representations input to the decoder. Experiments show that the proposed MaskOCR approach achieves superior results on the benchmark datasets, including Chinese and English text images.