 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Natural Language-Based Document Image Retrieval: New Dataset and Benchmark
Dec 23, 2025Document image retrieval (DIR) aims to retrieve document images from a gallery according to a given query. Existing DIR methods are primarily based on image queries that retrieve documents within the same coarse semantic category, e.g., newspapers or receipts. However, these methods struggle to effectively retrieve document images in real-world scenarios where textual queries with fine-grained semantics are usually provided. To bridge this gap, we introduce a new Natural Language-based Document Image Retrieval (NL-DIR) benchmark with corresponding evaluation metrics. In this work, natural language descriptions serve as semantically rich queries for the DIR task. The NL-DIR dataset contains 41K authentic document images, each paired with five high-quality, fine-grained semantic queries generated and evaluated through large language models in conjunction with manual verification. We perform zero-shot and fine-tuning evaluations of existing mainstream contrastive vision-language models and OCR-free visual document understanding (VDU) models. A two-stage retrieval method is further investigated for performance improvement while achieving both time and space efficiency. We hope the proposed NL-DIR benchmark can bring new opportunities and facilitate research for the VDU community. Datasets and codes will be publicly available at huggingface.co/datasets/nianbing/NL-DIR.
Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval
Aug 01, 2024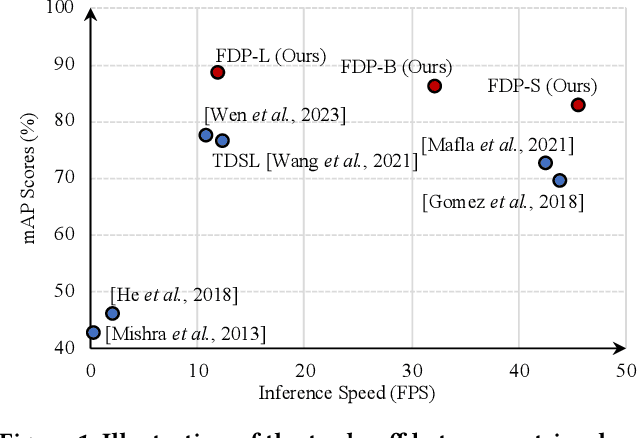
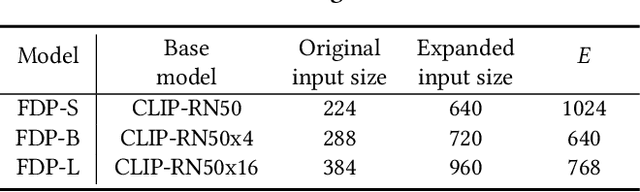


Scene text retrieval aims to find all images containing the query text from an image gallery. Current efforts tend to adopt an Optical Character Recognition (OCR) pipeline, which requires complicated text detection and/or recognition processes, resulting in inefficient and inflexible retrieval. Different from them, in this work we propose to explore the intrinsic potential of Contrastive Language-Image Pre-training (CLIP) for OCR-free scene text retrieval. Through empirical analysis, we observe that the main challenges of CLIP as a text retriever are: 1) limited text perceptual scale, and 2) entangled visual-semantic concepts. To this end, a novel model termed FDP (Focus, Distinguish, and Prompt) is developed. FDP first focuses on scene text via shifting the attention to the text area and probing the hidden text knowledge, and then divides the query text into content word and function word for processing, in which a semantic-aware prompting scheme and a distracted queries assistance module are utilized. Extensive experiments show that FDP significantly enhances the inference speed while achieving better or competitive retrieval accuracy compared to existing methods. Notably, on the IIIT-STR benchmark, FDP surpasses the state-of-the-art model by 4.37% with a 4 times faster speed. Furthermore, additional experiments under phrase-level and attribute-aware scene text retrieval settings validate FDP's particular advantages in handling diverse forms of query text. The source code will be publicly available at https://github.com/Gyann-z/FDP.
Towards Robust Real-Time Scene Text Detection: From Semantic to Instance Representation Learning
Aug 14, 2023



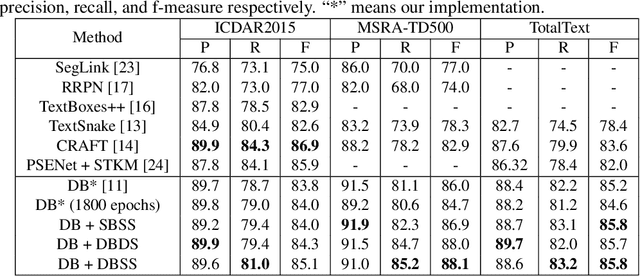
Due to the flexible representation of arbitrary-shaped scene text and simple pipeline, bottom-up segmentation-based methods begin to be mainstream in real-time scene text detection. Despite great progress, these methods show deficiencies in robustness and still suffer from false positives and instance adhesion. Different from existing methods which integrate multiple-granularity features or multiple outputs, we resort to the perspective of representation learning in which auxiliary tasks are utilized to enable the encoder to jointly learn robust features with the main task of per-pixel classification during optimization. For semantic representation learning, we propose global-dense semantic contrast (GDSC), in which a vector is extracted for global semantic representation, then used to perform element-wise contrast with the dense grid features. To learn instance-aware representation, we propose to combine top-down modeling (TDM) with the bottom-up framework to provide implicit instance-level clues for the encoder. With the proposed GDSC and TDM, the encoder network learns stronger representation without introducing any parameters and computations during inference. Equipped with a very light decoder, the detector can achieve more robust real-time scene text detection. Experimental results on four public datasets show that the proposed method can outperform or be comparable to the state-of-the-art on both accuracy and speed. Specifically, the proposed method achieves 87.2% F-measure with 48.2 FPS on Total-Text and 89.6% F-measure with 36.9 FPS on MSRA-TD500 on a single GeForce RTX 2080 Ti GPU.
UNITS: Unsupervised Intermediate Training Stage for Scene Text Detection
May 10, 2022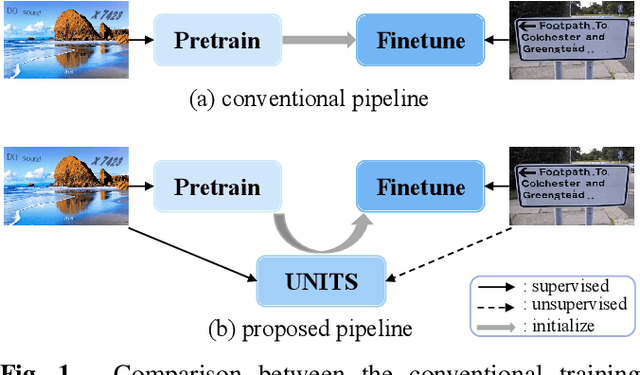


Recent scene text detection methods are almost based on deep learning and data-driven. Synthetic data is commonly adopted for pre-training due to expensive annotation cost. However, there are obvious domain discrepancies between synthetic data and real-world data. It may lead to sub-optimal performance to directly adopt the model initialized by synthetic data in the fine-tuning stage. In this paper, we propose a new training paradigm for scene text detection, which introduces an \textbf{UN}supervised \textbf{I}ntermediate \textbf{T}raining \textbf{S}tage (UNITS) that builds a buffer path to real-world data and can alleviate the gap between the pre-training stage and fine-tuning stage. Three training strategies are further explored to perceive information from real-world data in an unsupervised way. With UNITS, scene text detectors are improved without introducing any parameters and computations during inference. Extensive experimental results show consistent performance improvements on three public datasets.
Which and Where to Focus: A Simple yet Accurate Framework for Arbitrary-Shaped Nearby Text Detection in Scene Images
Sep 08, 2021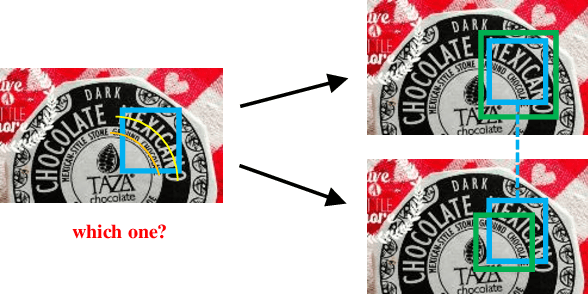

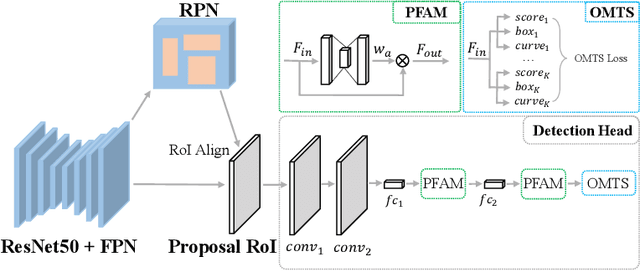
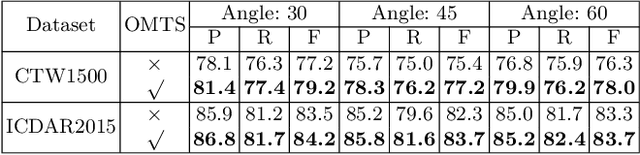
Scene text detection has drawn the close attention of researchers. Though many methods have been proposed for horizontal and oriented texts, previous methods may not perform well when dealing with arbitrary-shaped texts such as curved texts. In particular, confusion problem arises in the case of nearby text instances. In this paper, we propose a simple yet effective method for accurate arbitrary-shaped nearby scene text detection. Firstly, a One-to-Many Training Scheme (OMTS) is designed to eliminate confusion and enable the proposals to learn more appropriate groundtruths in the case of nearby text instances. Secondly, we propose a Proposal Feature Attention Module (PFAM) to exploit more effective features for each proposal, which can better adapt to arbitrary-shaped text instances. Finally, we propose a baseline that is based on Faster R-CNN and outputs the curve representation directly. Equipped with PFAM and OMTS, the detector can achieve state-of-the-art or competitive performance on several challenging benchmarks.
Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection
Sep 08, 2021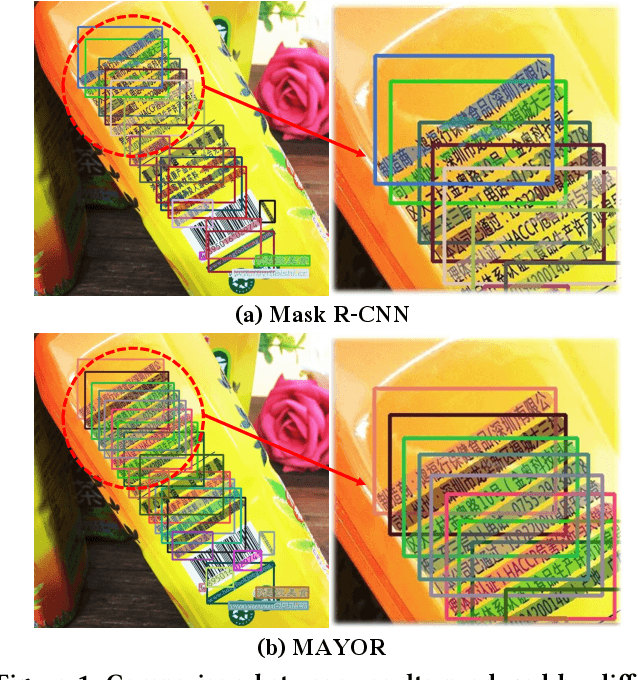
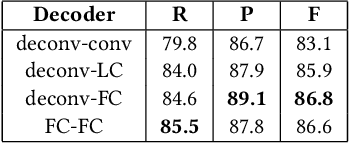
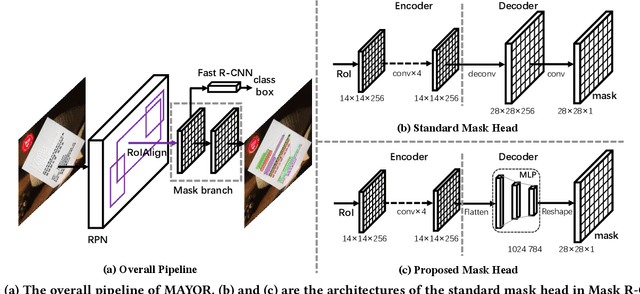
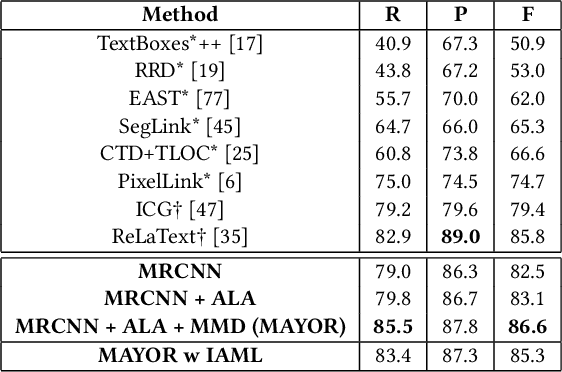
Due to the large success in object detection and instance segmentation, Mask R-CNN attracts great attention and is widely adopted as a strong baseline for arbitrary-shaped scene text detection and spotting. However, two issues remain to be settled. The first is dense text case, which is easy to be neglected but quite practical. There may exist multiple instances in one proposal, which makes it difficult for the mask head to distinguish different instances and degrades the performance. In this work, we argue that the performance degradation results from the learning confusion issue in the mask head. We propose to use an MLP decoder instead of the "deconv-conv" decoder in the mask head, which alleviates the issue and promotes robustness significantly. And we propose instance-aware mask learning in which the mask head learns to predict the shape of the whole instance rather than classify each pixel to text or non-text. With instance-aware mask learning, the mask branch can learn separated and compact masks. The second is that due to large variations in scale and aspect ratio, RPN needs complicated anchor settings, making it hard to maintain and transfer across different datasets. To settle this issue, we propose an adaptive label assignment in which all instances especially those with extreme aspect ratios are guaranteed to be associated with enough anchors. Equipped with these components, the proposed method named MAYOR achieves state-of-the-art performance on five benchmarks including DAST1500, MSRA-TD500, ICDAR2015, CTW1500, and Total-Text.
Gaussian Constrained Attention Network for Scene Text Recognition
Oct 19, 2020
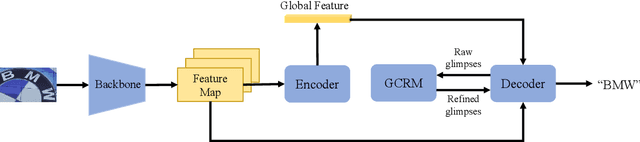


Scene text recognition has been a hot topic in computer vision. Recent methods adopt the attention mechanism for sequence prediction which achieve convincing results. However, we argue that the existing attention mechanism faces the problem of attention diffusion, in which the model may not focus on a certain character area. In this paper, we propose Gaussian Constrained Attention Network to deal with this problem. It is a 2D attention-based method integrated with a novel Gaussian Constrained Refinement Module, which predicts an additional Gaussian mask to refine the attention weights. Different from adopting an additional supervision on the attention weights simply, our proposed method introduces an explicit refinement. In this way, the attention weights will be more concentrated and the attention-based recognition network achieves better performance. The proposed Gaussian Constrained Refinement Module is flexible and can be applied to existing attention-based methods directly. The experiments on several benchmark datasets demonstrate the effectiveness of our proposed method. Our code has been available at https://github.com/Pay20Y/GCAN.
FC2RN: A Fully Convolutional Corner Refinement Network for Accurate Multi-Oriented Scene Text Detection
Jul 10, 2020



Recent scene text detection works mainly focus on curve text detection. However, in real applications, the curve texts are more scarce than the multi-oriented ones. Accurate detection of multi-oriented text with large variations of scales, orientations, and aspect ratios is of great significance. Among the multi-oriented detection methods, direct regression for the geometry of scene text shares a simple yet powerful pipeline and gets popular in academic and industrial communities, but it may produce imperfect detections, especially for long texts due to the limitation of the receptive field. In this work, we aim to improve this while keeping the pipeline simple. A fully convolutional corner refinement network (FC2RN) is proposed for accurate multi-oriented text detection, in which an initial corner prediction and a refined corner prediction are obtained at one pass. With a novel quadrilateral RoI convolution operation tailed for multi-oriented scene text, the initial quadrilateral prediction is encoded into the feature maps which can be further used to predict offset between the initial prediction and the ground-truth as well as output a refined confidence score. Experimental results on four public datasets including MSRA-TD500, ICDAR2017-RCTW, ICDAR2015, and COCO-Text demonstrate that FC2RN can outperform the state-of-the-art methods. The ablation study shows the effectiveness of corner refinement and scoring for accurate text localization.
Curved Text Detection in Natural Scene Images with Semi- and Weakly-Supervised Learning
Aug 27, 2019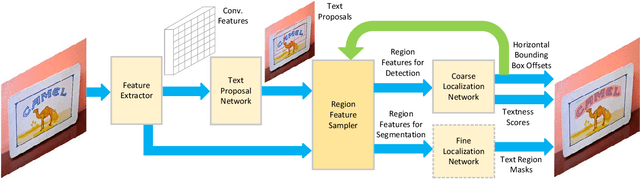
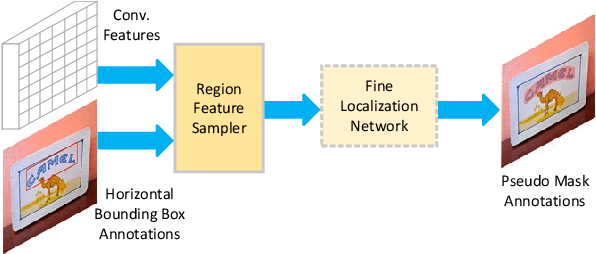


Detecting curved text in the wild is very challenging. Recently, most state-of-the-art methods are segmentation based and require pixel-level annotations. We propose a novel scheme to train an accurate text detector using only a small amount of pixel-level annotated data and a large amount of data annotated with rectangles or even unlabeled data. A baseline model is first obtained by training with the pixel-level annotated data and then used to annotate unlabeled or weakly labeled data. A novel strategy which utilizes ground-truth bounding boxes to generate pseudo mask annotations is proposed in weakly-supervised learning. Experimental results on CTW1500 and Total-Text demonstrate that our method can substantially reduce the requirement of pixel-level annotated data. Our method can also generalize well across two datasets. The performance of the proposed method is comparable with the state-of-the-art methods with only 10% pixel-level annotated data and 90% rectangle-level weakly annotated data.