 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNITS: Unsupervised Intermediate Training Stage for Scene Text Detection
Paper and Code
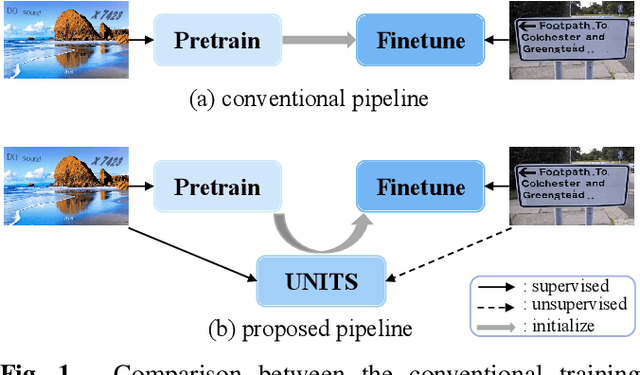
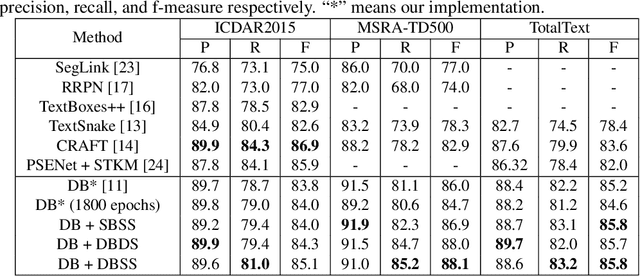


Recent scene text detection methods are almost based on deep learning and data-driven. Synthetic data is commonly adopted for pre-training due to expensive annotation cost. However, there are obvious domain discrepancies between synthetic data and real-world data. It may lead to sub-optimal performance to directly adopt the model initialized by synthetic data in the fine-tuning stage. In this paper, we propose a new training paradigm for scene text detection, which introduces an \textbf{UN}supervised \textbf{I}ntermediate \textbf{T}raining \textbf{S}tage (UNITS) that builds a buffer path to real-world data and can alleviate the gap between the pre-training stage and fine-tuning stage. Three training strategies are further explored to perceive information from real-world data in an unsupervised way. With UNITS, scene text detectors are improved without introducing any parameters and computations during inference. Extensive experimental results show consistent performance improvements on three public datasets.