 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurved Text Detection in Natural Scene Images with Semi- and Weakly-Supervised Learning
Paper and Code
Aug 27, 2019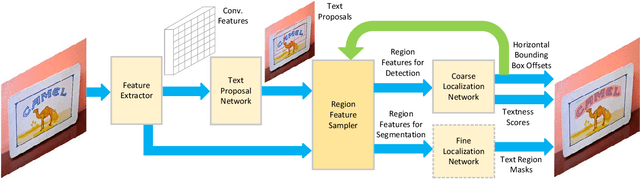
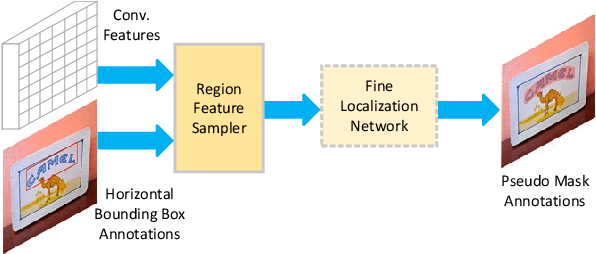


Detecting curved text in the wild is very challenging. Recently, most state-of-the-art methods are segmentation based and require pixel-level annotations. We propose a novel scheme to train an accurate text detector using only a small amount of pixel-level annotated data and a large amount of data annotated with rectangles or even unlabeled data. A baseline model is first obtained by training with the pixel-level annotated data and then used to annotate unlabeled or weakly labeled data. A novel strategy which utilizes ground-truth bounding boxes to generate pseudo mask annotations is proposed in weakly-supervised learning. Experimental results on CTW1500 and Total-Text demonstrate that our method can substantially reduce the requirement of pixel-level annotated data. Our method can also generalize well across two datasets. The performance of the proposed method is comparable with the state-of-the-art methods with only 10% pixel-level annotated data and 90% rectangle-level weakly annotated data.