 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Natural Language-Based Document Image Retrieval: New Dataset and Benchmark
Dec 23, 2025Document image retrieval (DIR) aims to retrieve document images from a gallery according to a given query. Existing DIR methods are primarily based on image queries that retrieve documents within the same coarse semantic category, e.g., newspapers or receipts. However, these methods struggle to effectively retrieve document images in real-world scenarios where textual queries with fine-grained semantics are usually provided. To bridge this gap, we introduce a new Natural Language-based Document Image Retrieval (NL-DIR) benchmark with corresponding evaluation metrics. In this work, natural language descriptions serve as semantically rich queries for the DIR task. The NL-DIR dataset contains 41K authentic document images, each paired with five high-quality, fine-grained semantic queries generated and evaluated through large language models in conjunction with manual verification. We perform zero-shot and fine-tuning evaluations of existing mainstream contrastive vision-language models and OCR-free visual document understanding (VDU) models. A two-stage retrieval method is further investigated for performance improvement while achieving both time and space efficiency. We hope the proposed NL-DIR benchmark can bring new opportunities and facilitate research for the VDU community. Datasets and codes will be publicly available at huggingface.co/datasets/nianbing/NL-DIR.
Towards Robust Real-Time Scene Text Detection: From Semantic to Instance Representation Learning
Aug 14, 2023



Due to the flexible representation of arbitrary-shaped scene text and simple pipeline, bottom-up segmentation-based methods begin to be mainstream in real-time scene text detection. Despite great progress, these methods show deficiencies in robustness and still suffer from false positives and instance adhesion. Different from existing methods which integrate multiple-granularity features or multiple outputs, we resort to the perspective of representation learning in which auxiliary tasks are utilized to enable the encoder to jointly learn robust features with the main task of per-pixel classification during optimization. For semantic representation learning, we propose global-dense semantic contrast (GDSC), in which a vector is extracted for global semantic representation, then used to perform element-wise contrast with the dense grid features. To learn instance-aware representation, we propose to combine top-down modeling (TDM) with the bottom-up framework to provide implicit instance-level clues for the encoder. With the proposed GDSC and TDM, the encoder network learns stronger representation without introducing any parameters and computations during inference. Equipped with a very light decoder, the detector can achieve more robust real-time scene text detection. Experimental results on four public datasets show that the proposed method can outperform or be comparable to the state-of-the-art on both accuracy and speed. Specifically, the proposed method achieves 87.2% F-measure with 48.2 FPS on Total-Text and 89.6% F-measure with 36.9 FPS on MSRA-TD500 on a single GeForce RTX 2080 Ti GPU.
Locally Adaptive Translation for Knowledge Graph Embedding
Dec 04, 2015
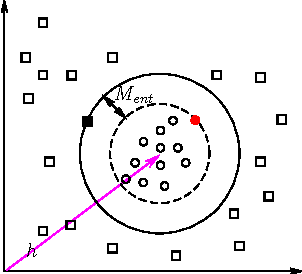

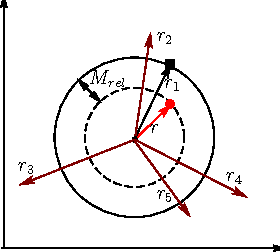
Knowledge graph embedding aims to represent entities and relations in a large-scale knowledge graph as elements in a continuous vector space. Existing methods, e.g., TransE and TransH, learn embedding representation by defining a global margin-based loss function over the data. However, the optimal loss function is determined during experiments whose parameters are examined among a closed set of candidates. Moreover, embeddings over two knowledge graphs with different entities and relations share the same set of candidate loss functions, ignoring the locality of both graphs. This leads to the limited performance of embedding related applications. In this paper, we propose a locally adaptive translation method for knowledge graph embedding, called TransA, to find the optimal loss function by adaptively determining its margin over different knowledge graphs. Experiments on two benchmark data sets demonstrate the superiority of the proposed method, as compared to the-state-of-the-art ones.