 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICLEval: Evaluating In-Context Learning Ability of Large Language Models
Jun 21, 2024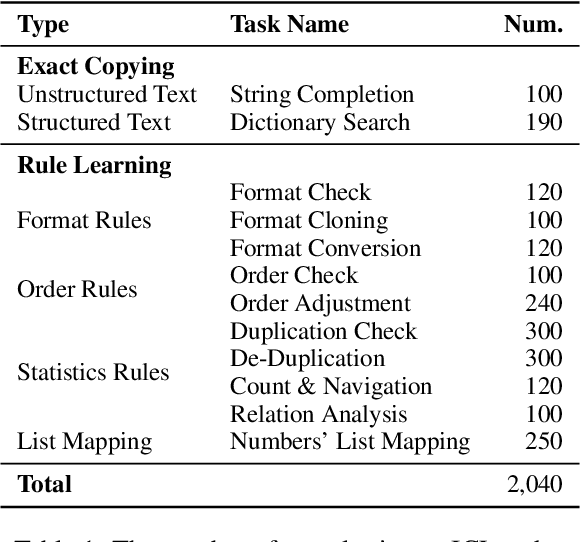
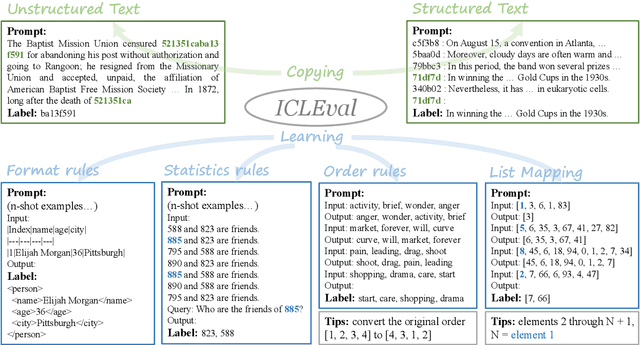
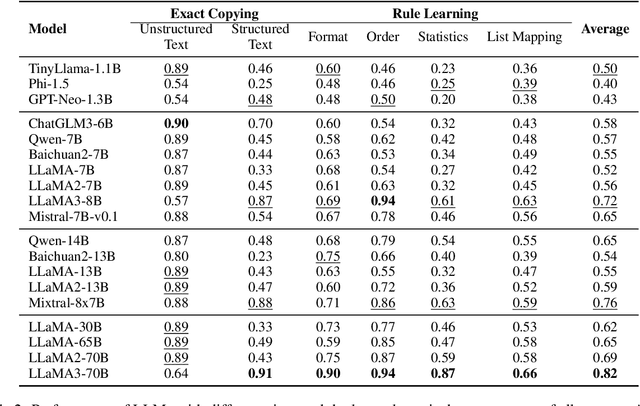
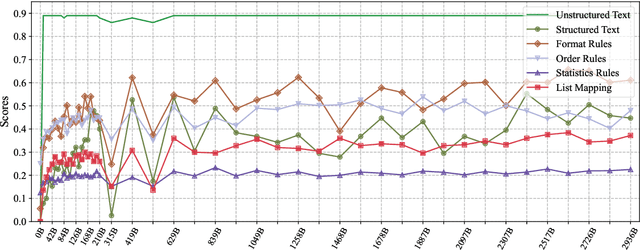
In-Context Learning (ICL) is a critical capability of Large Language Models (LLMs) as it empowers them to comprehend and reason across interconnected inputs. Evaluating the ICL ability of LLMs can enhance their utilization and deepen our understanding of how this ability is acquired at the training stage. However, existing evaluation frameworks primarily focus on language abilities and knowledge, often overlooking the assessment of ICL ability. In this work, we introduce the ICLEval benchmark to evaluate the ICL abilities of LLMs, which encompasses two key sub-abilities: exact copying and rule learning. Through the ICLEval benchmark, we demonstrate that ICL ability is universally present in different LLMs, and model size is not the sole determinant of ICL efficacy. Surprisingly, we observe that ICL abilities, particularly copying, develop early in the pretraining process and stabilize afterward. Our source codes and benchmark are released at https://github.com/yiye3/ICLEval.
Learning Entity Linking Features for Emerging Entities
Aug 08, 2022



Entity linking (EL) is the process of linking entity mentions appearing in text with their corresponding entities in a knowledge base. EL features of entities (e.g., prior probability, relatedness score, and entity embedding) are usually estimated based on Wikipedia. However, for newly emerging entities (EEs) which have just been discovered in news, they may still not be included in Wikipedia yet. As a consequence, it is unable to obtain required EL features for those EEs from Wikipedia and EL models will always fail to link ambiguous mentions with those EEs correctly as the absence of their EL features. To deal with this problem, in this paper we focus on a new task of learning EL features for emerging entities in a general way. We propose a novel approach called STAMO to learn high-quality EL features for EEs automatically, which needs just a small number of labeled documents for each EE collected from the Web, as it could further leverage the knowledge hidden in the unlabeled data. STAMO is mainly based on self-training, which makes it flexibly integrated with any EL feature or EL model, but also makes it easily suffer from the error reinforcement problem caused by the mislabeled data. Instead of some common self-training strategies that try to throw the mislabeled data away explicitly, we regard self-training as a multiple optimization process with respect to the EL features of EEs, and propose both intra-slot and inter-slot optimizations to alleviate the error reinforcement problem implicitly. We construct two EL datasets involving selected EEs to evaluate the quality of obtained EL features for EEs, and the experimental results show that our approach significantly outperforms other baseline methods of learning EL features.
KMIR: A Benchmark for Evaluating Knowledge Memorization, Identification and Reasoning Abilities of Language Models
Feb 28, 2022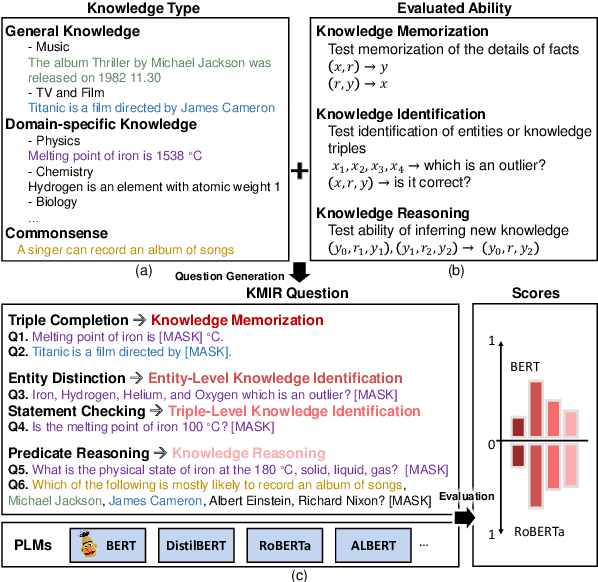



Previous works show the great potential of pre-trained language models (PLMs) for storing a large amount of factual knowledge. However, to figure out whether PLMs can be reliable knowledge sources and used as alternative knowledge bases (KBs), we need to further explore some critical features of PLMs. Firstly, knowledge memorization and identification abilities: traditional KBs can store various types of entities and relationships; do PLMs have a high knowledge capacity to store different types of knowledge? Secondly, reasoning ability: a qualified knowledge source should not only provide a collection of facts, but support a symbolic reasoner. Can PLMs derive new knowledge based on the correlations between facts? To evaluate these features of PLMs, we propose a benchmark, named Knowledge Memorization, Identification, and Reasoning test (KMIR). KMIR covers 3 types of knowledge, including general knowledge, domain-specific knowledge, and commonsense, and provides 184,348 well-designed questions. Preliminary experiments with various representative pre-training language models on KMIR reveal many interesting phenomenons: 1) The memorization ability of PLMs depends more on the number of parameters than training schemes. 2) Current PLMs are struggling to robustly remember the facts. 3) Model compression technology retains the amount of knowledge well, but hurts the identification and reasoning abilities. We hope KMIR can facilitate the design of PLMs as better knowledge sources.
Towards More Effective and Economic Sparsely-Activated Model
Oct 14, 2021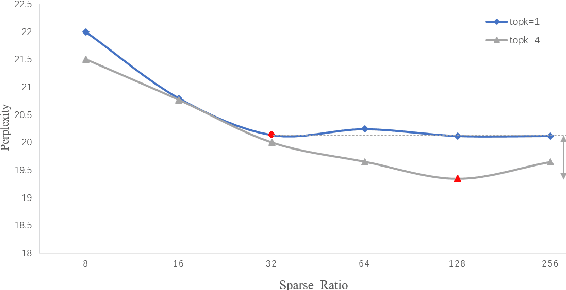
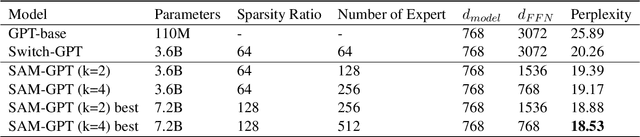
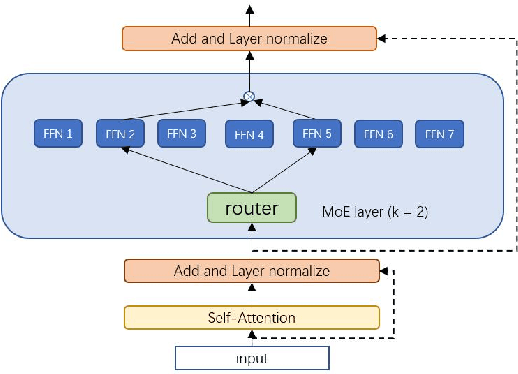
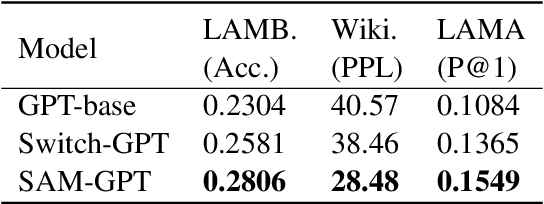
The sparsely-activated models have achieved great success in natural language processing through large-scale parameters and relatively low computational cost, and gradually become a feasible technique for training and implementing extremely large models. Due to the limit of communication cost, activating multiple experts is hardly affordable during training and inference. Therefore, previous work usually activate just one expert at a time to alleviate additional communication cost. Such routing mechanism limits the upper bound of model performance. In this paper, we first investigate a phenomenon that increasing the number of activated experts can boost the model performance with higher sparse ratio. To increase the number of activated experts without an increase in computational cost, we propose SAM (Switch and Mixture) routing, an efficient hierarchical routing mechanism that activates multiple experts in a same device (GPU). Our methods shed light on the training of extremely large sparse models and experiments prove that our models can achieve significant performance gain with great efficiency improvement.
YES SIR!Optimizing Semantic Space of Negatives with Self-Involvement Ranker
Sep 14, 2021
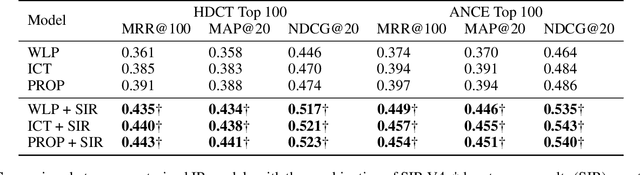
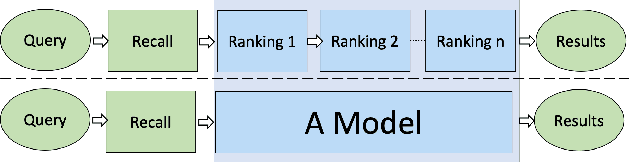
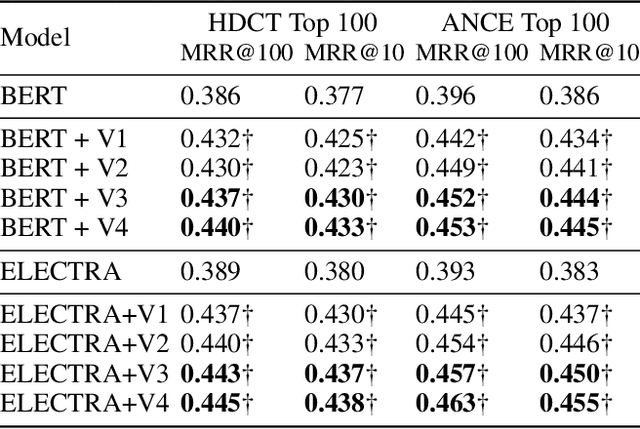
Pre-trained model such as BERT has been proved to be an effective tool for dealing with Information Retrieval (IR) problems. Due to its inspiring performance, it has been widely used to tackle with real-world IR problems such as document ranking. Recently, researchers have found that selecting "hard" rather than "random" negative samples would be beneficial for fine-tuning pre-trained models on ranking tasks. However, it remains elusive how to leverage hard negative samples in a principled way. To address the aforementioned issues, we propose a fine-tuning strategy for document ranking, namely Self-Involvement Ranker (SIR), to dynamically select hard negative samples to construct high-quality semantic space for training a high-quality ranking model. Specifically, SIR consists of sequential compressors implemented with pre-trained models. Front compressor selects hard negative samples for rear compressor. Moreover, SIR leverages supervisory signal to adaptively adjust semantic space of negative samples. Finally, supervisory signal in rear compressor is computed based on condition probability and thus can control sample dynamic and further enhance the model performance. SIR is a lightweight and general framework for pre-trained models, which simplifies the ranking process in industry practice. We test our proposed solution on MS MARCO with document ranking setting, and the results show that SIR can significantly improve the ranking performance of various pre-trained models. Moreover, our method became the new SOTA model anonymously on MS MARCO Document ranking leaderboard in May 2021.
Emotion Eliciting Machine: Emotion Eliciting Conversation Generation based on Dual Generator
May 18, 2021
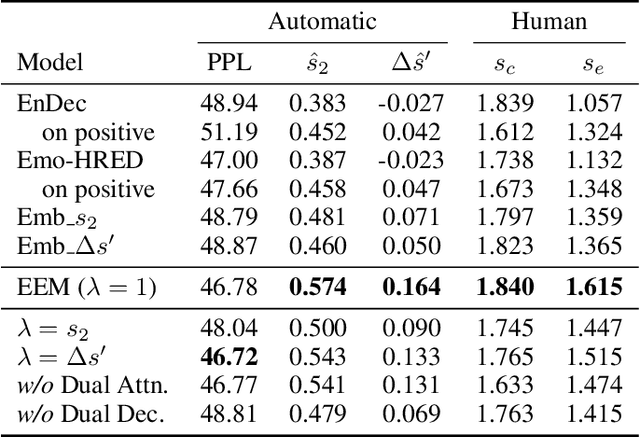
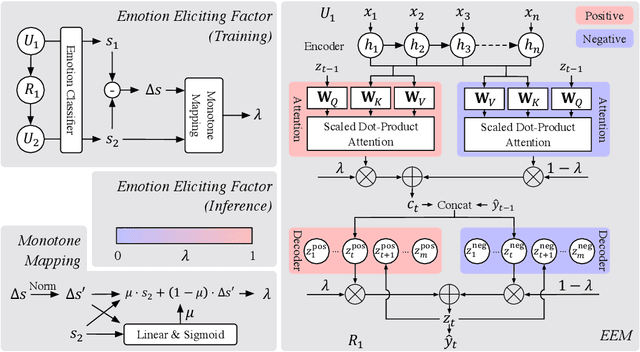

Recent years have witnessed great progress on building emotional chatbots. Tremendous methods have been proposed for chatbots to generate responses with given emotions. However, the emotion changes of the user during the conversation has not been fully explored. In this work, we study the problem of positive emotion elicitation, which aims to generate responses that can elicit positive emotion of the user, in human-machine conversation. We propose a weakly supervised Emotion Eliciting Machine (EEM) to address this problem. Specifically, we first collect weak labels of user emotion status changes in a conversion based on a pre-trained emotion classifier. Then we propose a dual encoder-decoder structure to model the generation of responses in both positive and negative side based on the changes of the user's emotion status in the conversation. An emotion eliciting factor is introduced on top of the dual structure to balance the positive and negative emotional impacts on the generated response during emotion elicitation. The factor also provides a fine-grained controlling manner for emotion elicitation. Experimental results on a large real-world dataset show that EEM outperforms the existing models in generating responses with positive emotion elicitation.
OntoZSL: Ontology-enhanced Zero-shot Learning
Feb 15, 2021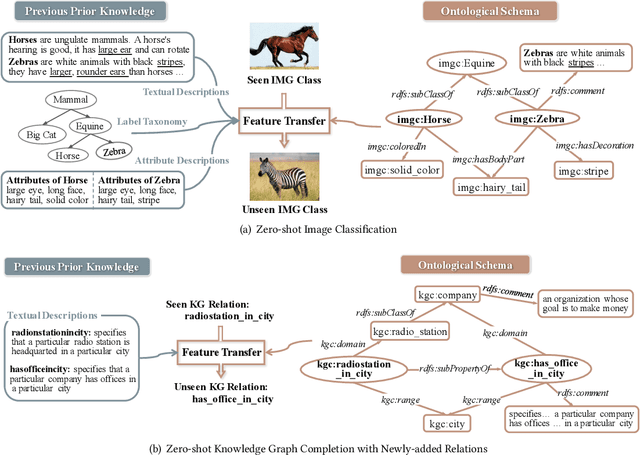

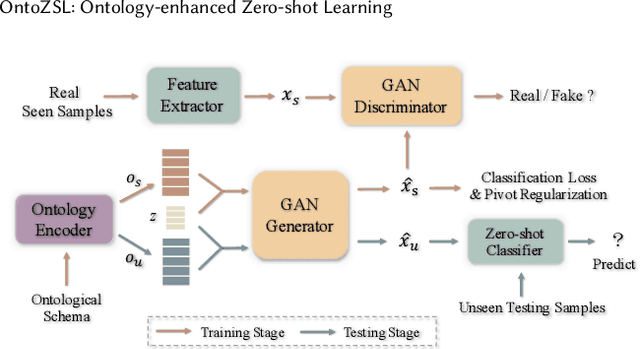
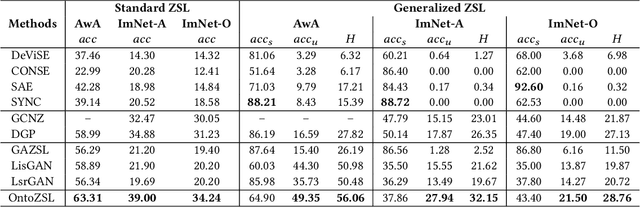
Zero-shot Learning (ZSL), which aims to predict for those classes that have never appeared in the training data, has arisen hot research interests. The key of implementing ZSL is to leverage the prior knowledge of classes which builds the semantic relationship between classes and enables the transfer of the learned models (e.g., features) from training classes (i.e., seen classes) to unseen classes. However, the priors adopted by the existing methods are relatively limited with incomplete semantics. In this paper, we explore richer and more competitive prior knowledge to model the inter-class relationship for ZSL via ontology-based knowledge representation and semantic embedding. Meanwhile, to address the data imbalance between seen classes and unseen classes, we developed a generative ZSL framework with Generative Adversarial Networks (GANs). Our main findings include: (i) an ontology-enhanced ZSL framework that can be applied to different domains, such as image classification (IMGC) and knowledge graph completion (KGC); (ii) a comprehensive evaluation with multiple zero-shot datasets from different domains, where our method often achieves better performance than the state-of-the-art models. In particular, on four representative ZSL baselines of IMGC, the ontology-based class semantics outperform the previous priors e.g., the word embeddings of classes by an average of 12.4 accuracy points in the standard ZSL across two example datasets (see Figure 4).
FedE: Embedding Knowledge Graphs in Federated Setting
Oct 24, 2020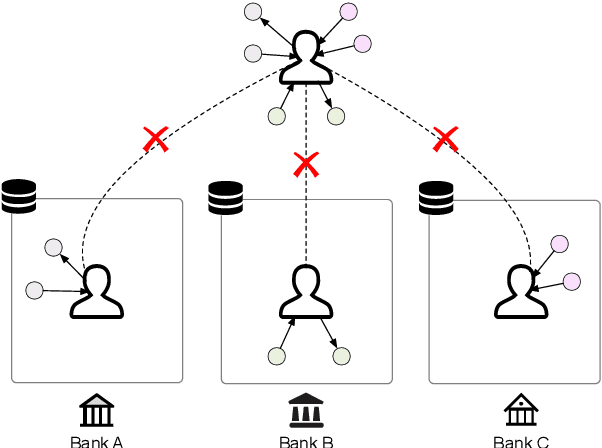

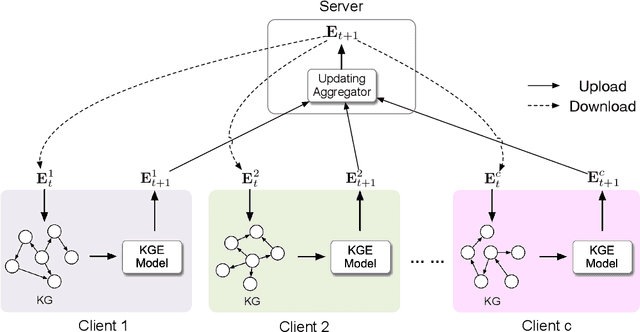
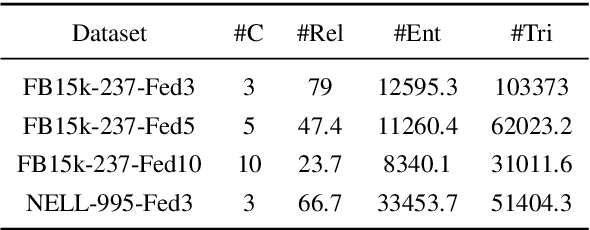
Knowledge graphs (KGs) consisting of triples are always incomplete, so it's important to do Knowledge Graph Completion (KGC) by predicting missing triples. Multi-Source KG is a common situation in real KG applications which can be viewed as a set of related individual KGs where different KGs contains relations of different aspects of entities. It's intuitive that, for each individual KG, its completion could be greatly contributed by the triples defined and labeled in other ones. However, because of the data privacy and sensitivity, a set of relevant knowledge graphs cannot complement each other's KGC by just collecting data from different knowledge graphs together. Therefore, in this paper, we introduce federated setting to keep their privacy without triple transferring between KGs and apply it in embedding knowledge graph, a typical method which have proven effective for KGC in the past decade. We propose a Federated Knowledge Graph Embedding framework FedE, focusing on learning knowledge graph embeddings by aggregating locally-computed updates. Finally, we conduct extensive experiments on datasets derived from KGE benchmark datasets and results show the effectiveness of our proposed FedE.
The Devil is the Classifier: Investigating Long Tail Relation Classification with Decoupling Analysis
Sep 15, 2020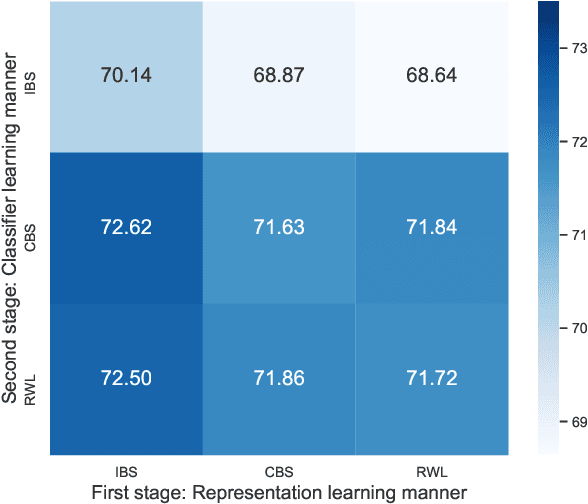
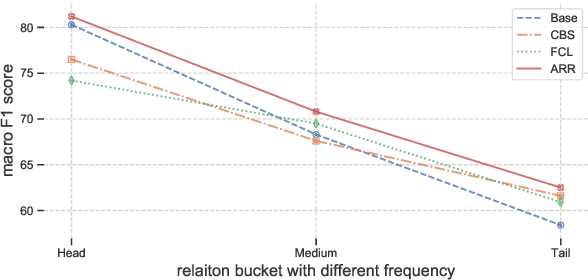
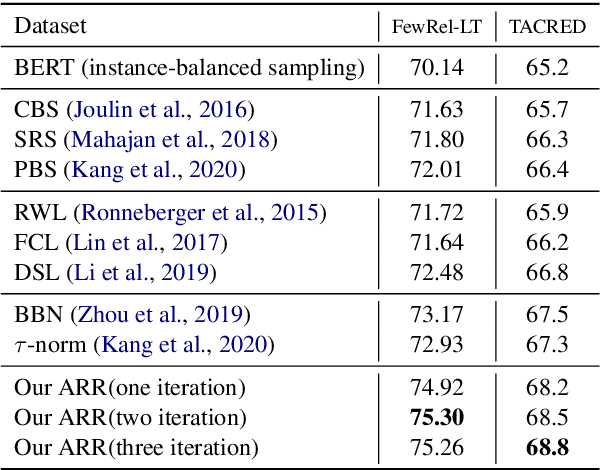
Long-tailed relation classification is a challenging problem as the head classes may dominate the training phase, thereby leading to the deterioration of the tail performance. Existing solutions usually address this issue via class-balancing strategies, e.g., data re-sampling and loss re-weighting, but all these methods adhere to the schema of entangling learning of the representation and classifier. In this study, we conduct an in-depth empirical investigation into the long-tailed problem and found that pre-trained models with instance-balanced sampling already capture the well-learned representations for all classes; moreover, it is possible to achieve better long-tailed classification ability at low cost by only adjusting the classifier. Inspired by this observation, we propose a robust classifier with attentive relation routing, which assigns soft weights by automatically aggregating the relations. Extensive experiments on two datasets demonstrate the effectiveness of our proposed approach. Code and datasets are available in https://github.com/zjunlp/deepke.
Generative Adversarial Zero-shot Learning via Knowledge Graphs
Apr 07, 2020

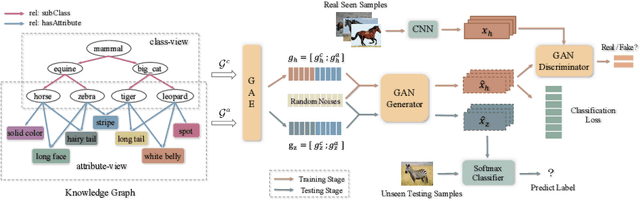
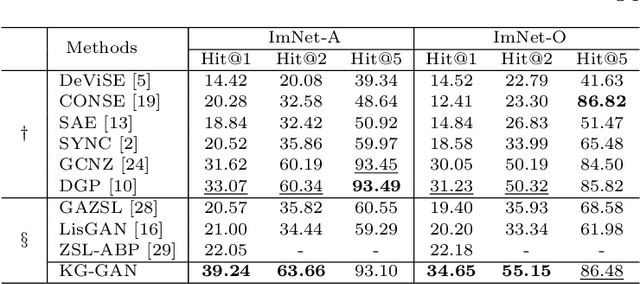
Zero-shot learning (ZSL) is to handle the prediction of those unseen classes that have no labeled training data. Recently, generative methods like Generative Adversarial Networks (GANs) are being widely investigated for ZSL due to their high accuracy, generalization capability and so on. However, the side information of classes used now is limited to text descriptions and attribute annotations, which are in short of semantics of the classes. In this paper, we introduce a new generative ZSL method named KG-GAN by incorporating rich semantics in a knowledge graph (KG) into GANs. Specifically, we build upon Graph Neural Networks and encode KG from two views: class view and attribute view considering the different semantics of KG. With well-learned semantic embeddings for each node (representing a visual category), we leverage GANs to synthesize compelling visual features for unseen classes. According to our evaluation with multiple image classification datasets, KG-GAN can achieve better performance than the state-of-the-art baselines.