 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICLEval: Evaluating In-Context Learning Ability of Large Language Models
Paper and Code
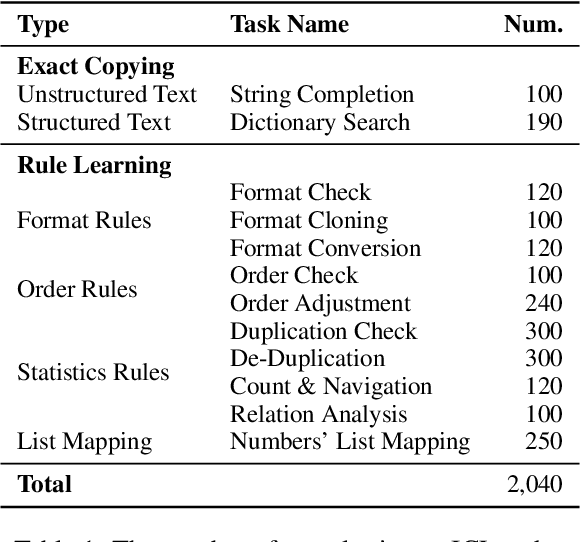
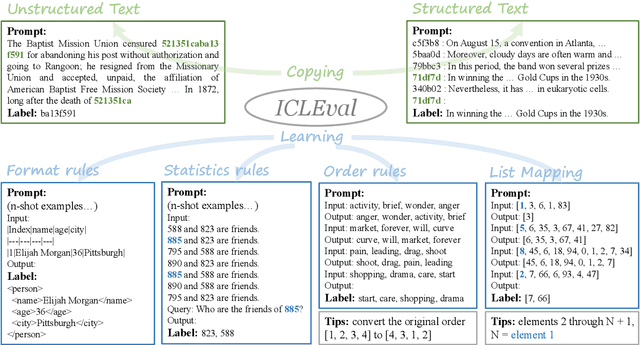
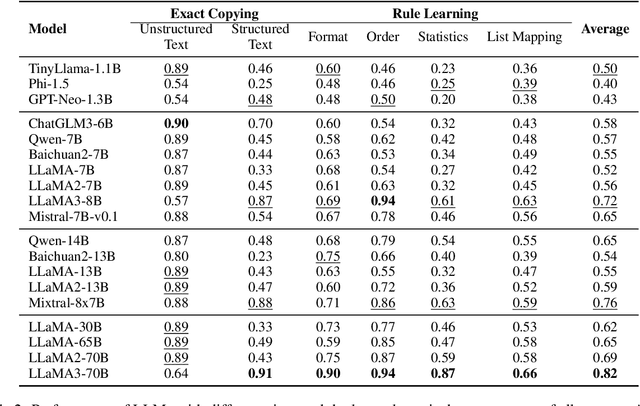
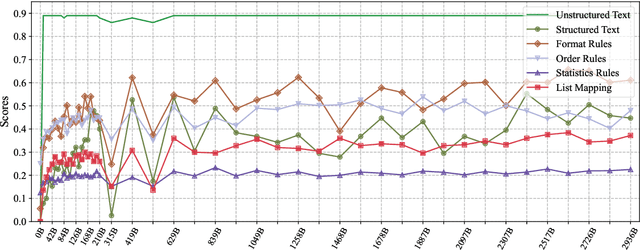
In-Context Learning (ICL) is a critical capability of Large Language Models (LLMs) as it empowers them to comprehend and reason across interconnected inputs. Evaluating the ICL ability of LLMs can enhance their utilization and deepen our understanding of how this ability is acquired at the training stage. However, existing evaluation frameworks primarily focus on language abilities and knowledge, often overlooking the assessment of ICL ability. In this work, we introduce the ICLEval benchmark to evaluate the ICL abilities of LLMs, which encompasses two key sub-abilities: exact copying and rule learning. Through the ICLEval benchmark, we demonstrate that ICL ability is universally present in different LLMs, and model size is not the sole determinant of ICL efficacy. Surprisingly, we observe that ICL abilities, particularly copying, develop early in the pretraining process and stabilize afterward. Our source codes and benchmark are released at https://github.com/yiye3/ICLEval.