 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapTools: Adaptive Tool-based Indirect Prompt Injection Attacks on Agentic LLMs
Feb 24, 2026The integration of external data services (e.g., Model Context Protocol, MCP) has made large language model-based agents increasingly powerful for complex task execution. However, this advancement introduces critical security vulnerabilities, particularly indirect prompt injection (IPI) attacks. Existing attack methods are limited by their reliance on static patterns and evaluation on simple language models, failing to address the fast-evolving nature of modern AI agents. We introduce AdapTools, a novel adaptive IPI attack framework that selects stealthier attack tools and generates adaptive attack prompts to create a rigorous security evaluation environment. Our approach comprises two key components: (1) Adaptive Attack Strategy Construction, which develops transferable adversarial strategies for prompt optimization, and (2) Attack Enhancement, which identifies stealthy tools capable of circumventing task-relevance defenses. Comprehensive experimental evaluation shows that AdapTools achieves a 2.13 times improvement in attack success rate while degrading system utility by a factor of 1.78. Notably, the framework maintains its effectiveness even against state-of-the-art defense mechanisms. Our method advances the understanding of IPI attacks and provides a useful reference for future research.
ICON: Indirect Prompt Injection Defense for Agents based on Inference-Time Correction
Feb 24, 2026Large Language Model (LLM) agents are susceptible to Indirect Prompt Injection (IPI) attacks, where malicious instructions in retrieved content hijack the agent's execution. Existing defenses typically rely on strict filtering or refusal mechanisms, which suffer from a critical limitation: over-refusal, prematurely terminating valid agentic workflows. We propose ICON, a probing-to-mitigation framework that neutralizes attacks while preserving task continuity. Our key insight is that IPI attacks leave distinct over-focusing signatures in the latent space. We introduce a Latent Space Trace Prober to detect attacks based on high intensity scores. Subsequently, a Mitigating Rectifier performs surgical attention steering that selectively manipulate adversarial query key dependencies while amplifying task relevant elements to restore the LLM's functional trajectory. Extensive evaluations on multiple backbones show that ICON achieves a competitive 0.4% ASR, matching commercial grade detectors, while yielding a over 50% task utility gain. Furthermore, ICON demonstrates robust Out of Distribution(OOD) generalization and extends effectively to multi-modal agents, establishing a superior balance between security and efficiency.
AGATE: Stealthy Black-box Watermarking for Multimodal Model Copyright Protection
Apr 28, 2025Recent advancement in large-scale Artificial Intelligence (AI) models offering multimodal services have become foundational in AI systems, making them prime targets for model theft. Existing methods select Out-of-Distribution (OoD) data as backdoor watermarks and retrain the original model for copyright protection. However, existing methods are susceptible to malicious detection and forgery by adversaries, resulting in watermark evasion. In this work, we propose Model-\underline{ag}nostic Black-box Backdoor W\underline{ate}rmarking Framework (AGATE) to address stealthiness and robustness challenges in multimodal model copyright protection. Specifically, we propose an adversarial trigger generation method to generate stealthy adversarial triggers from ordinary dataset, providing visual fidelity while inducing semantic shifts. To alleviate the issue of anomaly detection among model outputs, we propose a post-transform module to correct the model output by narrowing the distance between adversarial trigger image embedding and text embedding. Subsequently, a two-phase watermark verification is proposed to judge whether the current model infringes by comparing the two results with and without the transform module. Consequently, we consistently outperform state-of-the-art methods across five datasets in the downstream tasks of multimodal image-text retrieval and image classification. Additionally, we validated the robustness of AGATE under two adversarial attack scenarios.
Learning Entity Linking Features for Emerging Entities
Aug 08, 2022



Entity linking (EL) is the process of linking entity mentions appearing in text with their corresponding entities in a knowledge base. EL features of entities (e.g., prior probability, relatedness score, and entity embedding) are usually estimated based on Wikipedia. However, for newly emerging entities (EEs) which have just been discovered in news, they may still not be included in Wikipedia yet. As a consequence, it is unable to obtain required EL features for those EEs from Wikipedia and EL models will always fail to link ambiguous mentions with those EEs correctly as the absence of their EL features. To deal with this problem, in this paper we focus on a new task of learning EL features for emerging entities in a general way. We propose a novel approach called STAMO to learn high-quality EL features for EEs automatically, which needs just a small number of labeled documents for each EE collected from the Web, as it could further leverage the knowledge hidden in the unlabeled data. STAMO is mainly based on self-training, which makes it flexibly integrated with any EL feature or EL model, but also makes it easily suffer from the error reinforcement problem caused by the mislabeled data. Instead of some common self-training strategies that try to throw the mislabeled data away explicitly, we regard self-training as a multiple optimization process with respect to the EL features of EEs, and propose both intra-slot and inter-slot optimizations to alleviate the error reinforcement problem implicitly. We construct two EL datasets involving selected EEs to evaluate the quality of obtained EL features for EEs, and the experimental results show that our approach significantly outperforms other baseline methods of learning EL features.
Community Question Answering Entity Linking via Leveraging Auxiliary Data
May 24, 2022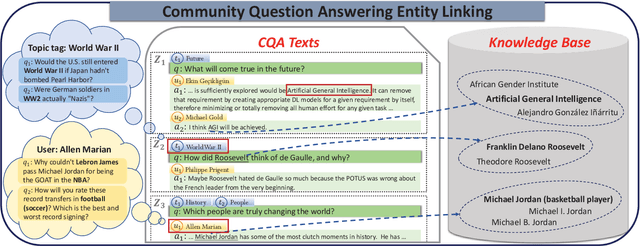
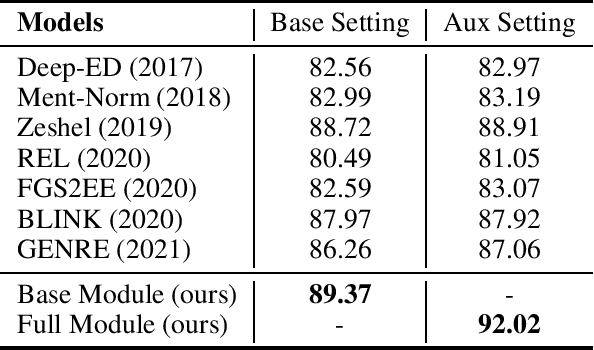

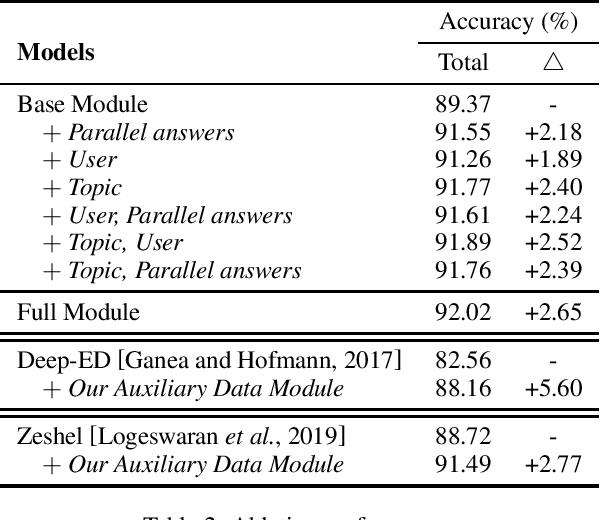
Community Question Answering (CQA) platforms contain plenty of CQA texts (i.e., questions and answers corresponding to the question) where named entities appear ubiquitously. In this paper, we define a new task of CQA entity linking (CQAEL) as linking the textual entity mentions detected from CQA texts with their corresponding entities in a knowledge base. This task can facilitate many downstream applications including expert finding and knowledge base enrichment. Traditional entity linking methods mainly focus on linking entities in news documents, and are suboptimal over this new task of CQAEL since they cannot effectively leverage various informative auxiliary data involved in the CQA platform to aid entity linking, such as parallel answers and two types of meta-data (i.e., topic tags and users). To remedy this crucial issue, we propose a novel transformer-based framework to effectively harness the knowledge delivered by different kinds of auxiliary data to promote the linking performance. We validate the superiority of our framework through extensive experiments over a newly released CQAEL data set against state-of-the-art entity linking methods.
SEdroid: A Robust Android Malware Detector using Selective Ensemble Learning
Sep 06, 2019
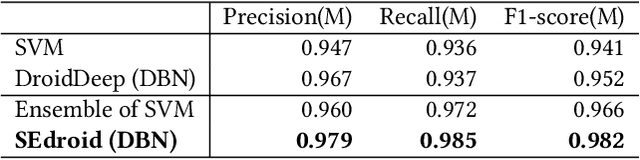

For the dramatic increase of Android malware and low efficiency of manual check process, deep learning methods started to be an auxiliary means for Android malware detection these years. However, these models are highly dependent on the quality of datasets, and perform unsatisfactory results when the quality of training data is not good enough. In the real world, the quality of datasets without manually check cannot be guaranteed, even Google Play may contain malicious applications, which will cause the trained model failure. To address the challenge, we propose a robust Android malware detection approach based on selective ensemble learning, trying to provide an effective solution not that limited to the quality of datasets. The proposed model utilizes genetic algorithm to help find the best combination of the component learners and improve robustness of the model. Our results show that the proposed approach achieves a more robust performance than other approaches in the same area.