 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language Pre-training Model-Guided Approach for Mitigating Backdoor Attacks in Federated Learning
Aug 14, 2025Existing backdoor defense methods in Federated Learning (FL) rely on the assumption of homogeneous client data distributions or the availability of a clean serve dataset, which limits the practicality and effectiveness. Defending against backdoor attacks under heterogeneous client data distributions while preserving model performance remains a significant challenge. In this paper, we propose a FL backdoor defense framework named CLIP-Fed, which leverages the zero-shot learning capabilities of vision-language pre-training models. By integrating both pre-aggregation and post-aggregation defense strategies, CLIP-Fed overcomes the limitations of Non-IID imposed on defense effectiveness. To address privacy concerns and enhance the coverage of the dataset against diverse triggers, we construct and augment the server dataset using the multimodal large language model and frequency analysis without any client samples. To address class prototype deviations caused by backdoor samples and eliminate the correlation between trigger patterns and target labels, CLIP-Fed aligns the knowledge of the global model and CLIP on the augmented dataset using prototype contrastive loss and Kullback-Leibler divergence. Extensive experiments on representative datasets validate the effectiveness of CLIP-Fed. Compared to state-of-the-art methods, CLIP-Fed achieves an average reduction in ASR, i.e., 2.03\% on CIFAR-10 and 1.35\% on CIFAR-10-LT, while improving average MA by 7.92\% and 0.48\%, respectively.
BESA: Boosting Encoder Stealing Attack with Perturbation Recovery
Jun 05, 2025To boost the encoder stealing attack under the perturbation-based defense that hinders the attack performance, we propose a boosting encoder stealing attack with perturbation recovery named BESA. It aims to overcome perturbation-based defenses. The core of BESA consists of two modules: perturbation detection and perturbation recovery, which can be combined with canonical encoder stealing attacks. The perturbation detection module utilizes the feature vectors obtained from the target encoder to infer the defense mechanism employed by the service provider. Once the defense mechanism is detected, the perturbation recovery module leverages the well-designed generative model to restore a clean feature vector from the perturbed one. Through extensive evaluations based on various datasets, we demonstrate that BESA significantly enhances the surrogate encoder accuracy of existing encoder stealing attacks by up to 24.63\% when facing state-of-the-art defenses and combinations of multiple defenses.
Large Language Model-driven Security Assistant for Internet of Things via Chain-of-Thought
May 08, 2025The rapid development of Internet of Things (IoT) technology has transformed people's way of life and has a profound impact on both production and daily activities. However, with the rapid advancement of IoT technology, the security of IoT devices has become an unavoidable issue in both research and applications. Although some efforts have been made to detect or mitigate IoT security vulnerabilities, they often struggle to adapt to the complexity of IoT environments, especially when dealing with dynamic security scenarios. How to automatically, efficiently, and accurately understand these vulnerabilities remains a challenge. To address this, we propose an IoT security assistant driven by Large Language Model (LLM), which enhances the LLM's understanding of IoT security vulnerabilities and related threats. The aim of the ICoT method we propose is to enable the LLM to understand security issues by breaking down the various dimensions of security vulnerabilities and generating responses tailored to the user's specific needs and expertise level. By incorporating ICoT, LLM can gradually analyze and reason through complex security scenarios, resulting in more accurate, in-depth, and personalized security recommendations and solutions. Experimental results show that, compared to methods relying solely on LLM, our proposed LLM-driven IoT security assistant significantly improves the understanding of IoT security issues through the ICoT approach and provides personalized solutions based on the user's identity, demonstrating higher accuracy and reliability.
AGATE: Stealthy Black-box Watermarking for Multimodal Model Copyright Protection
Apr 28, 2025Recent advancement in large-scale Artificial Intelligence (AI) models offering multimodal services have become foundational in AI systems, making them prime targets for model theft. Existing methods select Out-of-Distribution (OoD) data as backdoor watermarks and retrain the original model for copyright protection. However, existing methods are susceptible to malicious detection and forgery by adversaries, resulting in watermark evasion. In this work, we propose Model-\underline{ag}nostic Black-box Backdoor W\underline{ate}rmarking Framework (AGATE) to address stealthiness and robustness challenges in multimodal model copyright protection. Specifically, we propose an adversarial trigger generation method to generate stealthy adversarial triggers from ordinary dataset, providing visual fidelity while inducing semantic shifts. To alleviate the issue of anomaly detection among model outputs, we propose a post-transform module to correct the model output by narrowing the distance between adversarial trigger image embedding and text embedding. Subsequently, a two-phase watermark verification is proposed to judge whether the current model infringes by comparing the two results with and without the transform module. Consequently, we consistently outperform state-of-the-art methods across five datasets in the downstream tasks of multimodal image-text retrieval and image classification. Additionally, we validated the robustness of AGATE under two adversarial attack scenarios.
PCDiff: Proactive Control for Ownership Protection in Diffusion Models with Watermark Compatibility
Apr 16, 2025With the growing demand for protecting the intellectual property (IP) of text-to-image diffusion models, we propose PCDiff -- a proactive access control framework that redefines model authorization by regulating generation quality. At its core, PCDIFF integrates a trainable fuser module and hierarchical authentication layers into the decoder architecture, ensuring that only users with valid encrypted credentials can generate high-fidelity images. In the absence of valid keys, the system deliberately degrades output quality, effectively preventing unauthorized exploitation.Importantly, while the primary mechanism enforces active access control through architectural intervention, its decoupled design retains compatibility with existing watermarking techniques. This satisfies the need of model owners to actively control model ownership while preserving the traceability capabilities provided by traditional watermarking approaches.Extensive experimental evaluations confirm a strong dependency between credential verification and image quality across various attack scenarios. Moreover, when combined with typical post-processing operations, PCDIFF demonstrates powerful performance alongside conventional watermarking methods. This work shifts the paradigm from passive detection to proactive enforcement of authorization, laying the groundwork for IP management of diffusion models.
Secure and Efficient Watermarking for Latent Diffusion Models in Model Distribution Scenarios
Feb 18, 2025



Latent diffusion models have exhibited considerable potential in generative tasks. Watermarking is considered to be an alternative to safeguard the copyright of generative models and prevent their misuse. However, in the context of model distribution scenarios, the accessibility of models to large scale of model users brings new challenges to the security, efficiency and robustness of existing watermark solutions. To address these issues, we propose a secure and efficient watermarking solution. A new security mechanism is designed to prevent watermark leakage and watermark escape, which considers watermark randomness and watermark-model association as two constraints for mandatory watermark injection. To reduce the time cost of training the security module, watermark injection and the security mechanism are decoupled, ensuring that fine-tuning VAE only accomplishes the security mechanism without the burden of learning watermark patterns. A watermark distribution-based verification strategy is proposed to enhance the robustness against diverse attacks in the model distribution scenarios. Experimental results prove that our watermarking consistently outperforms existing six baselines on effectiveness and robustness against ten image processing attacks and adversarial attacks, while enhancing security in the distribution scenarios.
Vertical Federated Continual Learning via Evolving Prototype Knowledge
Feb 13, 2025



Vertical Federated Learning (VFL) has garnered significant attention as a privacy-preserving machine learning framework for sample-aligned feature federation. However, traditional VFL approaches do not address the challenges of class and feature continual learning, resulting in catastrophic forgetting of knowledge from previous tasks. To address the above challenge, we propose a novel vertical federated continual learning method, named Vertical Federated Continual Learning via Evolving Prototype Knowledge (V-LETO), which primarily facilitates the transfer of knowledge from previous tasks through the evolution of prototypes. Specifically, we propose an evolving prototype knowledge method, enabling the global model to retain both previous and current task knowledge. Furthermore, we introduce a model optimization technique that mitigates the forgetting of previous task knowledge by restricting updates to specific parameters of the local model, thereby enhancing overall performance. Extensive experiments conducted in both CIL and FIL settings demonstrate that our method, V-LETO, outperforms the other state-of-the-art methods. For example, our method outperforms the state-of-the-art method by 10.39% and 35.15% for CIL and FIL tasks, respectively. Our code is available at https://anonymous.4open.science/r/V-LETO-0108/README.md.
Preventing Non-intrusive Load Monitoring Privacy Invasion: A Precise Adversarial Attack Scheme for Networked Smart Meters
Dec 22, 2024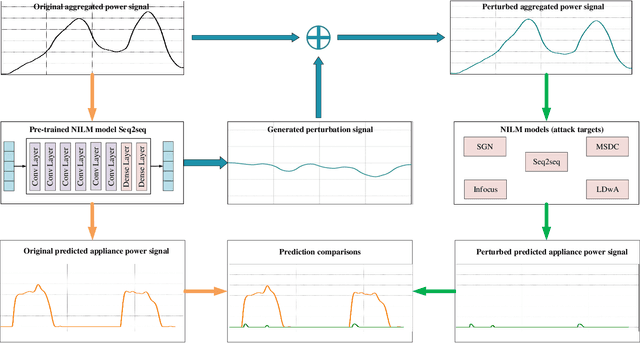

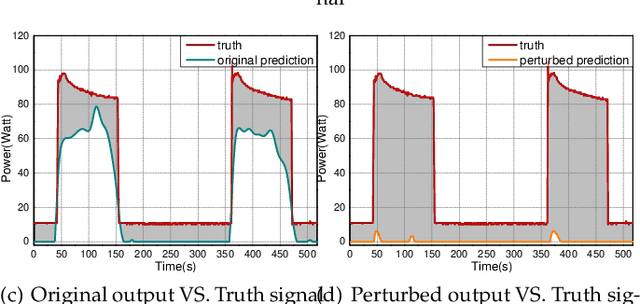
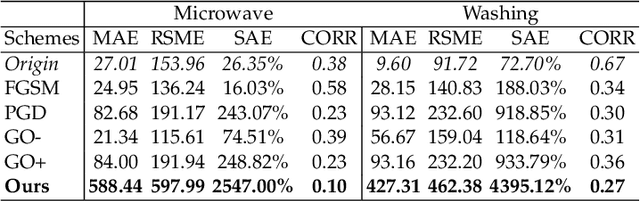
Smart grid, through networked smart meters employing the non-intrusive load monitoring (NILM) technique, can considerably discern the usage patterns of residential appliances. However, this technique also incurs privacy leakage. To address this issue, we propose an innovative scheme based on adversarial attack in this paper. The scheme effectively prevents NILM models from violating appliance-level privacy, while also ensuring accurate billing calculation for users. To achieve this objective, we overcome two primary challenges. First, as NILM models fall under the category of time-series regression models, direct application of traditional adversarial attacks designed for classification tasks is not feasible. To tackle this issue, we formulate a novel adversarial attack problem tailored specifically for NILM and providing a theoretical foundation for utilizing the Jacobian of the NILM model to generate imperceptible perturbations. Leveraging the Jacobian, our scheme can produce perturbations, which effectively misleads the signal prediction of NILM models to safeguard users' appliance-level privacy. The second challenge pertains to fundamental utility requirements, where existing adversarial attack schemes struggle to achieve accurate billing calculation for users. To handle this problem, we introduce an additional constraint, mandating that the sum of added perturbations within a billing period must be precisely zero. Experimental validation on real-world power datasets REDD and UK-DALE demonstrates the efficacy of our proposed solutions, which can significantly amplify the discrepancy between the output of the targeted NILM model and the actual power signal of appliances, and enable accurate billing at the same time. Additionally, our solutions exhibit transferability, making the generated perturbation signal from one target model applicable to other diverse NILM models.
Towards Effective, Efficient and Unsupervised Social Event Detection in the Hyperbolic Space
Dec 14, 2024



The vast, complex, and dynamic nature of social message data has posed challenges to social event detection (SED). Despite considerable effort, these challenges persist, often resulting in inadequately expressive message representations (ineffective) and prolonged learning durations (inefficient). In response to the challenges, this work introduces an unsupervised framework, HyperSED (Hyperbolic SED). Specifically, the proposed framework first models social messages into semantic-based message anchors, and then leverages the structure of the anchor graph and the expressiveness of the hyperbolic space to acquire structure- and geometry-aware anchor representations. Finally, HyperSED builds the partitioning tree of the anchor message graph by incorporating differentiable structural information as the reflection of the detected events. Extensive experiments on public datasets demonstrate HyperSED's competitive performance, along with a substantial improvement in efficiency compared to the current state-of-the-art unsupervised paradigm. Statistically, HyperSED boosts incremental SED by an average of 2%, 2%, and 25% in NMI, AMI, and ARI, respectively; enhancing efficiency by up to 37.41 times and at least 12.10 times, illustrating the advancement of the proposed framework. Our code is publicly available at https://github.com/XiaoyanWork/HyperSED.
Facial Features Matter: a Dynamic Watermark based Proactive Deepfake Detection Approach
Nov 22, 2024


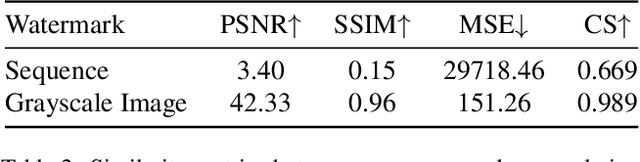
Current passive deepfake face-swapping detection methods encounter significance bottlenecks in model generalization capabilities. Meanwhile, proactive detection methods often use fixed watermarks which lack a close relationship with the content they protect and are vulnerable to security risks. Dynamic watermarks based on facial features offer a promising solution, as these features provide unique identifiers. Therefore, this paper proposes a Facial Feature-based Proactive deepfake detection method (FaceProtect), which utilizes changes in facial characteristics during deepfake manipulation as a novel detection mechanism. We introduce a GAN-based One-way Dynamic Watermark Generating Mechanism (GODWGM) that uses 128-dimensional facial feature vectors as inputs. This method creates irreversible mappings from facial features to watermarks, enhancing protection against various reverse inference attacks. Additionally, we propose a Watermark-based Verification Strategy (WVS) that combines steganography with GODWGM, allowing simultaneous transmission of the benchmark watermark representing facial features within the image. Experimental results demonstrate that our proposed method maintains exceptional detection performance and exhibits high practicality on images altered by various deepfake techniques.