 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomophily Enhanced Graph Domain Adaptation
May 26, 2025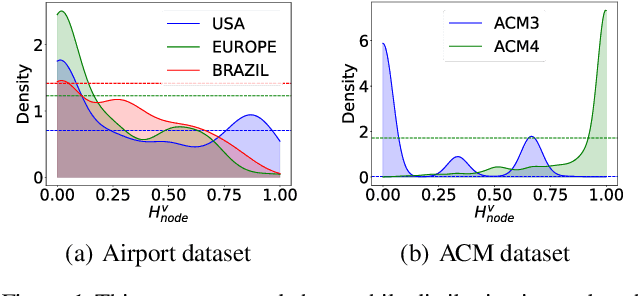



Graph Domain Adaptation (GDA) transfers knowledge from labeled source graphs to unlabeled target graphs, addressing the challenge of label scarcity. In this paper, we highlight the significance of graph homophily, a pivotal factor for graph domain alignment, which, however, has long been overlooked in existing approaches. Specifically, our analysis first reveals that homophily discrepancies exist in benchmarks. Moreover, we also show that homophily discrepancies degrade GDA performance from both empirical and theoretical aspects, which further underscores the importance of homophily alignment in GDA. Inspired by this finding, we propose a novel homophily alignment algorithm that employs mixed filters to smooth graph signals, thereby effectively capturing and mitigating homophily discrepancies between graphs. Experimental results on a variety of benchmarks verify the effectiveness of our method.
Leveraging Group Classification with Descending Soft Labeling for Deep Imbalanced Regression
Dec 16, 2024



Deep imbalanced regression (DIR), where the target values have a highly skewed distribution and are also continuous, is an intriguing yet under-explored problem in machine learning. While recent works have already shown that incorporating various classification-based regularizers can produce enhanced outcomes, the role of classification remains elusive in DIR. Moreover, such regularizers (e.g., contrastive penalties) merely focus on learning discriminative features of data, which inevitably results in ignorance of either continuity or similarity across the data. To address these issues, we first bridge the connection between the objectives of DIR and classification from a Bayesian perspective. Consequently, this motivates us to decompose the objective of DIR into a combination of classification and regression tasks, which naturally guides us toward a divide-and-conquer manner to solve the DIR problem. Specifically, by aggregating the data at nearby labels into the same groups, we introduce an ordinal group-aware contrastive learning loss along with a multi-experts regressor to tackle the different groups of data thereby maintaining the data continuity. Meanwhile, considering the similarity between the groups, we also propose a symmetric descending soft labeling strategy to exploit the intrinsic similarity across the data, which allows classification to facilitate regression more effectively. Extensive experiments on real-world datasets also validate the effectiveness of our method.
Generalizing across Temporal Domains with Koopman Operators
Feb 15, 2024



In the field of domain generalization, the task of constructing a predictive model capable of generalizing to a target domain without access to target data remains challenging. This problem becomes further complicated when considering evolving dynamics between domains. While various approaches have been proposed to address this issue, a comprehensive understanding of the underlying generalization theory is still lacking. In this study, we contribute novel theoretic results that aligning conditional distribution leads to the reduction of generalization bounds. Our analysis serves as a key motivation for solving the Temporal Domain Generalization (TDG) problem through the application of Koopman Neural Operators, resulting in Temporal Koopman Networks (TKNets). By employing Koopman Operators, we effectively address the time-evolving distributions encountered in TDG using the principles of Koopman theory, where measurement functions are sought to establish linear transition relations between evolving domains. Through empirical evaluations conducted on synthetic and real-world datasets, we validate the effectiveness of our proposed approach.
When Source-Free Domain Adaptation Meets Learning with Noisy Labels
Jan 31, 2023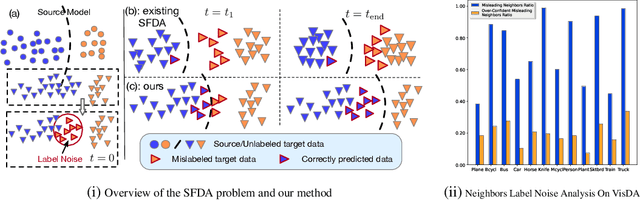
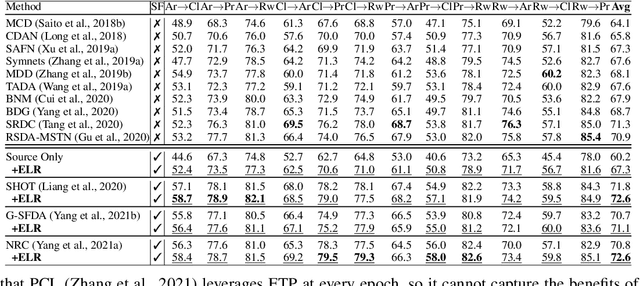
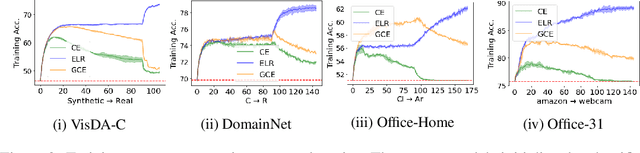
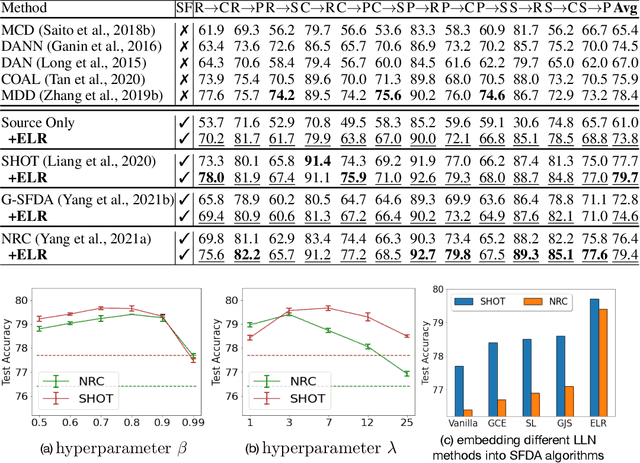
Recent state-of-the-art source-free domain adaptation (SFDA) methods have focused on learning meaningful cluster structures in the feature space, which have succeeded in adapting the knowledge from source domain to unlabeled target domain without accessing the private source data. However, existing methods rely on the pseudo-labels generated by source models that can be noisy due to domain shift. In this paper, we study SFDA from the perspective of learning with label noise (LLN). Unlike the label noise in the conventional LLN scenario, we prove that the label noise in SFDA follows a different distribution assumption. We also prove that such a difference makes existing LLN methods that rely on their distribution assumptions unable to address the label noise in SFDA. Empirical evidence suggests that only marginal improvements are achieved when applying the existing LLN methods to solve the SFDA problem. On the other hand, although there exists a fundamental difference between the label noise in the two scenarios, we demonstrate theoretically that the early-time training phenomenon (ETP), which has been previously observed in conventional label noise settings, can also be observed in the SFDA problem. Extensive experiments demonstrate significant improvements to existing SFDA algorithms by leveraging ETP to address the label noise in SFDA.
Evolving Domain Generalization
Jun 07, 2022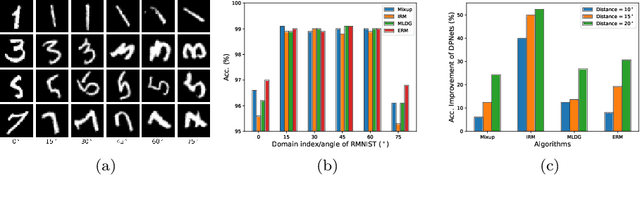
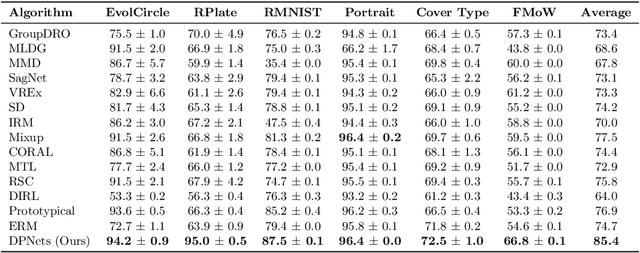


Domain generalization aims to learn a predictive model from multiple different but related source tasks that can generalize well to a target task without the need of accessing any target data. Existing domain generalization methods ignore the relationship between tasks, implicitly assuming that all the tasks are sampled from a stationary environment. Therefore, they can fail when deployed in an evolving environment. To this end, we formulate and study the \emph{evolving domain generalization} (EDG) scenario, which exploits not only the source data but also their evolving pattern to generate a model for the unseen task. Our theoretical result reveals the benefits of modeling the relation between two consecutive tasks by learning a globally consistent directional mapping function. In practice, our analysis also suggests solving the DDG problem in a meta-learning manner, which leads to \emph{directional prototypical network}, the first method for the DDG problem. Empirical evaluation of both synthetic and real-world data sets validates the effectiveness of our approach.
YES SIR!Optimizing Semantic Space of Negatives with Self-Involvement Ranker
Sep 14, 2021
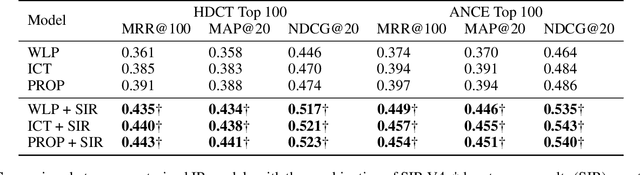
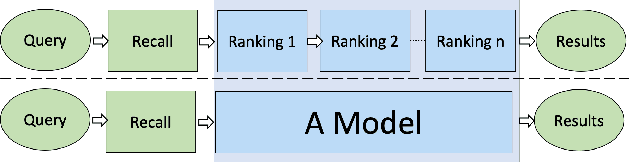
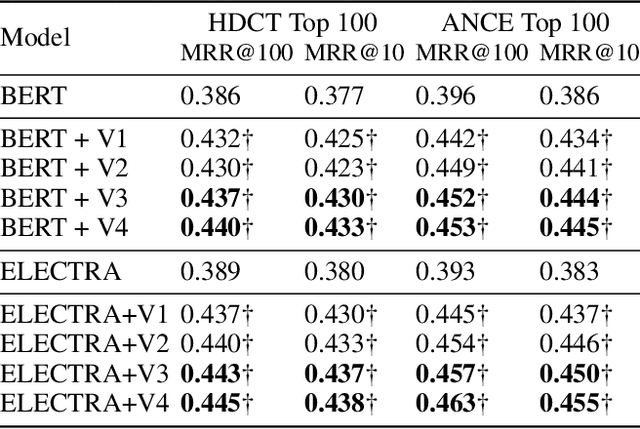
Pre-trained model such as BERT has been proved to be an effective tool for dealing with Information Retrieval (IR) problems. Due to its inspiring performance, it has been widely used to tackle with real-world IR problems such as document ranking. Recently, researchers have found that selecting "hard" rather than "random" negative samples would be beneficial for fine-tuning pre-trained models on ranking tasks. However, it remains elusive how to leverage hard negative samples in a principled way. To address the aforementioned issues, we propose a fine-tuning strategy for document ranking, namely Self-Involvement Ranker (SIR), to dynamically select hard negative samples to construct high-quality semantic space for training a high-quality ranking model. Specifically, SIR consists of sequential compressors implemented with pre-trained models. Front compressor selects hard negative samples for rear compressor. Moreover, SIR leverages supervisory signal to adaptively adjust semantic space of negative samples. Finally, supervisory signal in rear compressor is computed based on condition probability and thus can control sample dynamic and further enhance the model performance. SIR is a lightweight and general framework for pre-trained models, which simplifies the ranking process in industry practice. We test our proposed solution on MS MARCO with document ranking setting, and the results show that SIR can significantly improve the ranking performance of various pre-trained models. Moreover, our method became the new SOTA model anonymously on MS MARCO Document ranking leaderboard in May 2021.