 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Group Classification with Descending Soft Labeling for Deep Imbalanced Regression
Dec 16, 2024



Deep imbalanced regression (DIR), where the target values have a highly skewed distribution and are also continuous, is an intriguing yet under-explored problem in machine learning. While recent works have already shown that incorporating various classification-based regularizers can produce enhanced outcomes, the role of classification remains elusive in DIR. Moreover, such regularizers (e.g., contrastive penalties) merely focus on learning discriminative features of data, which inevitably results in ignorance of either continuity or similarity across the data. To address these issues, we first bridge the connection between the objectives of DIR and classification from a Bayesian perspective. Consequently, this motivates us to decompose the objective of DIR into a combination of classification and regression tasks, which naturally guides us toward a divide-and-conquer manner to solve the DIR problem. Specifically, by aggregating the data at nearby labels into the same groups, we introduce an ordinal group-aware contrastive learning loss along with a multi-experts regressor to tackle the different groups of data thereby maintaining the data continuity. Meanwhile, considering the similarity between the groups, we also propose a symmetric descending soft labeling strategy to exploit the intrinsic similarity across the data, which allows classification to facilitate regression more effectively. Extensive experiments on real-world datasets also validate the effectiveness of our method.
Physics-Informed Neural Networks: Minimizing Residual Loss with Wide Networks and Effective Activations
May 02, 2024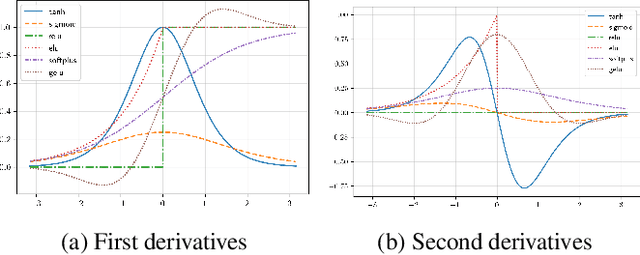
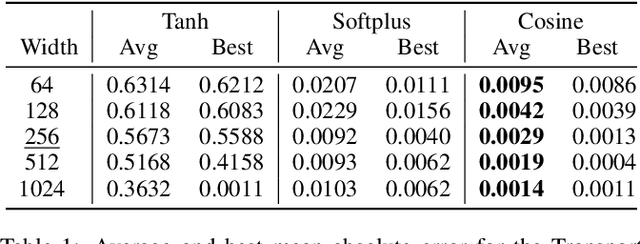
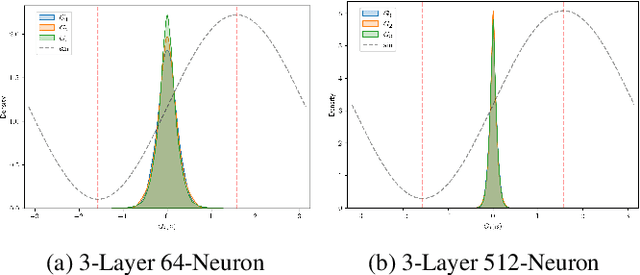
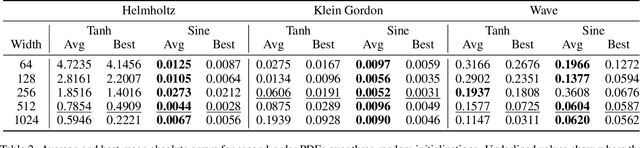
The residual loss in Physics-Informed Neural Networks (PINNs) alters the simple recursive relation of layers in a feed-forward neural network by applying a differential operator, resulting in a loss landscape that is inherently different from those of common supervised problems. Therefore, relying on the existing theory leads to unjustified design choices and suboptimal performance. In this work, we analyze the residual loss by studying its characteristics at critical points to find the conditions that result in effective training of PINNs. Specifically, we first show that under certain conditions, the residual loss of PINNs can be globally minimized by a wide neural network. Furthermore, our analysis also reveals that an activation function with well-behaved high-order derivatives plays a crucial role in minimizing the residual loss. In particular, to solve a $k$-th order PDE, the $k$-th derivative of the activation function should be bijective. The established theory paves the way for designing and choosing effective activation functions for PINNs and explains why periodic activations have shown promising performance in certain cases. Finally, we verify our findings by conducting a set of experiments on several PDEs. Our code is publicly available at https://github.com/nimahsn/pinns_tf2.
Generalizing across Temporal Domains with Koopman Operators
Feb 15, 2024



In the field of domain generalization, the task of constructing a predictive model capable of generalizing to a target domain without access to target data remains challenging. This problem becomes further complicated when considering evolving dynamics between domains. While various approaches have been proposed to address this issue, a comprehensive understanding of the underlying generalization theory is still lacking. In this study, we contribute novel theoretic results that aligning conditional distribution leads to the reduction of generalization bounds. Our analysis serves as a key motivation for solving the Temporal Domain Generalization (TDG) problem through the application of Koopman Neural Operators, resulting in Temporal Koopman Networks (TKNets). By employing Koopman Operators, we effectively address the time-evolving distributions encountered in TDG using the principles of Koopman theory, where measurement functions are sought to establish linear transition relations between evolving domains. Through empirical evaluations conducted on synthetic and real-world datasets, we validate the effectiveness of our proposed approach.
Hessian Aware Low-Rank Weight Perturbation for Continual Learning
Nov 26, 2023Continual learning aims to learn a series of tasks sequentially without forgetting the knowledge acquired from the previous ones. In this work, we propose the Hessian Aware Low-Rank Perturbation algorithm for continual learning. By modeling the parameter transitions along the sequential tasks with the weight matrix transformation, we propose to apply the low-rank approximation on the task-adaptive parameters in each layer of the neural networks. Specifically, we theoretically demonstrate the quantitative relationship between the Hessian and the proposed low-rank approximation. The approximation ranks are then globally determined according to the marginal increment of the empirical loss estimated by the layer-specific gradient and low-rank approximation error. Furthermore, we control the model capacity by pruning less important parameters to diminish the parameter growth. We conduct extensive experiments on various benchmarks, including a dataset with large-scale tasks, and compare our method against some recent state-of-the-art methods to demonstrate the effectiveness and scalability of our proposed method. Empirical results show that our method performs better on different benchmarks, especially in achieving task order robustness and handling the forgetting issue. A demo code can be found at https://github.com/lijiaqi/HALRP.
Hone as You Read: A Practical Type of Interactive Summarization
May 06, 2021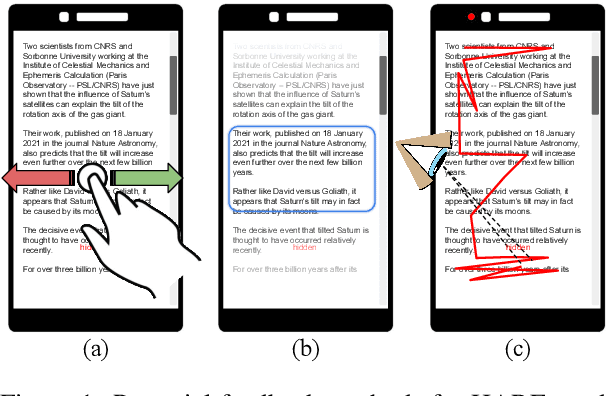
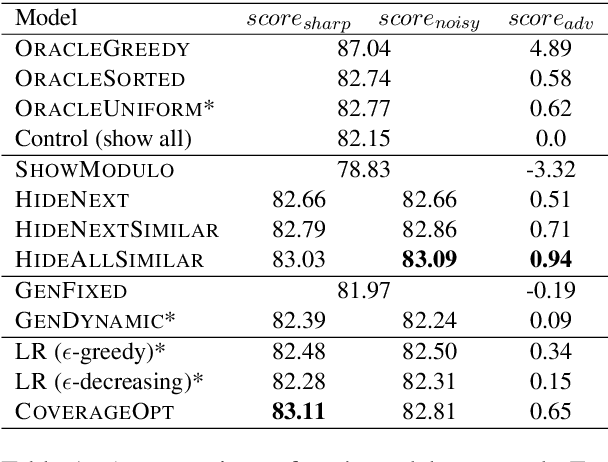
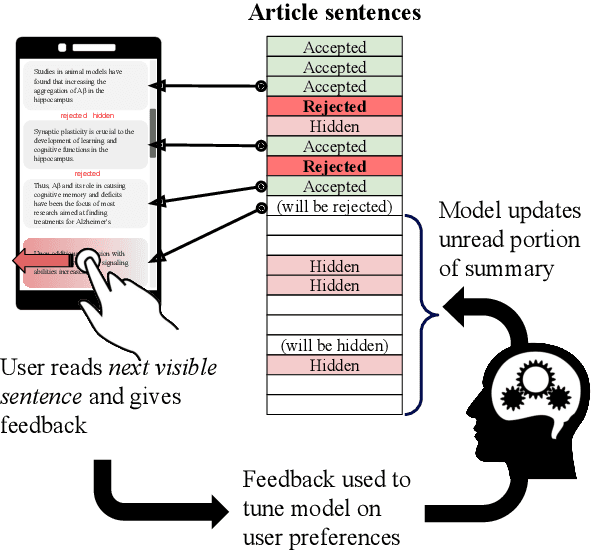

We present HARE, a new task where reader feedback is used to optimize document summaries for personal interest during the normal flow of reading. This task is related to interactive summarization, where personalized summaries are produced following a long feedback stage where users may read the same sentences many times. However, this process severely interrupts the flow of reading, making it impractical for leisurely reading. We propose to gather minimally-invasive feedback during the reading process to adapt to user interests and augment the document in real-time. Building off of recent advances in unsupervised summarization evaluation, we propose a suitable metric for this task and use it to evaluate a variety of approaches. Our approaches range from simple heuristics to preference-learning and their analysis provides insight into this important task. Human evaluation additionally supports the practicality of HARE. The code to reproduce this work is available at https://github.com/tannerbohn/HoneAsYouRead.
A Deep Learning Framework for Lifelong Machine Learning
May 01, 2021
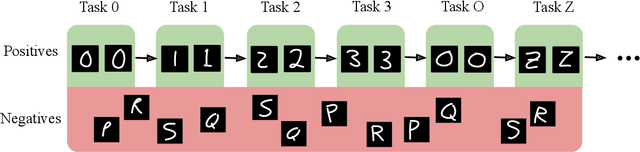


Humans can learn a variety of concepts and skills incrementally over the course of their lives while exhibiting many desirable properties, such as continual learning without forgetting, forward transfer and backward transfer of knowledge, and learning a new concept or task with only a few examples. Several lines of machine learning research, such as lifelong machine learning, few-shot learning, and transfer learning attempt to capture these properties. However, most previous approaches can only demonstrate subsets of these properties, often by different complex mechanisms. In this work, we propose a simple yet powerful unified deep learning framework that supports almost all of these properties and approaches through one central mechanism. Experiments on toy examples support our claims. We also draw connections between many peculiarities of human learning (such as memory loss and "rain man") and our framework. As academics, we often lack resources required to build and train, deep neural networks with billions of parameters on hundreds of TPUs. Thus, while our framework is still conceptual, and our experiment results are surely not SOTA, we hope that this unified lifelong learning framework inspires new work towards large-scale experiments and understanding human learning in general. This paper is summarized in two short YouTube videos: https://youtu.be/gCuUyGETbTU (part 1) and https://youtu.be/XsaGI01b-1o (part 2).
Catching Attention with Automatic Pull Quote Selection
May 27, 2020
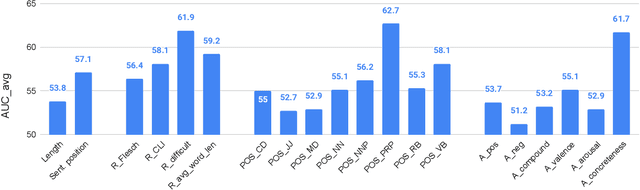

Pull quotes are an effective component of a captivating news article. These spans of text are selected from an article and provided with more salient presentation, with the aim of attracting readers with intriguing phrases and making the article more visually interesting. In this paper, we introduce the novel task of automatic pull quote selection, construct a dataset, and benchmark the performance of a number of approaches ranging from hand-crafted features to state-of-the-art sentence embeddings to cross-task models. We show that pre-trained Sentence-BERT embeddings outperform all other approaches, however the benefit over n-gram models is marginal. By closely examining the results of simple models, we also uncover many unexpected properties of pull quotes that should serve as inspiration for future approaches. We believe the benefits of exploring this problem further are clear: pull quotes have been found to increase enjoyment and readability, shape reader perceptions, and facilitate learning.
A Unified Framework for Lifelong Learning in Deep Neural Networks
Nov 28, 2019

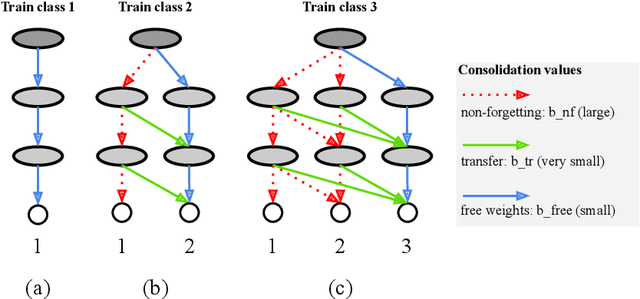
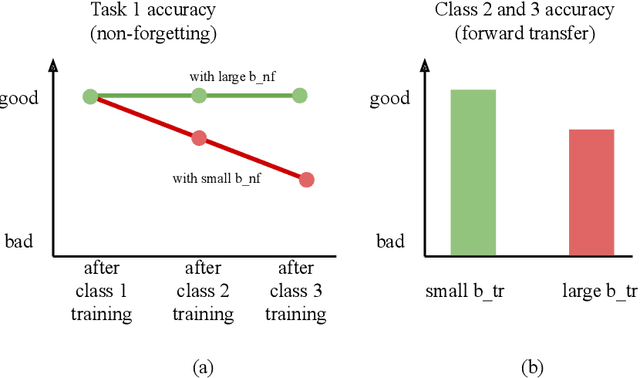
Humans can learn a variety of concepts and skills incrementally over the course of their lives while exhibiting an array of desirable properties, such as non-forgetting, concept rehearsal, forward transfer and backward transfer of knowledge, few-shot learning, and selective forgetting. Previous approaches to lifelong machine learning can only demonstrate subsets of these properties, often by combining multiple complex mechanisms. In this Perspective, we propose a powerful unified framework that can demonstrate all of the properties by utilizing a small number of weight consolidation parameters in deep neural networks. In addition, we are able to draw many parallels between the behaviours and mechanisms of our proposed framework and those surrounding human learning, such as memory loss or sleep deprivation. This Perspective serves as a conduit for two-way inspiration to further understand lifelong learning in machines and humans.
Few-Shot Abstract Visual Reasoning With Spectral Features
Oct 04, 2019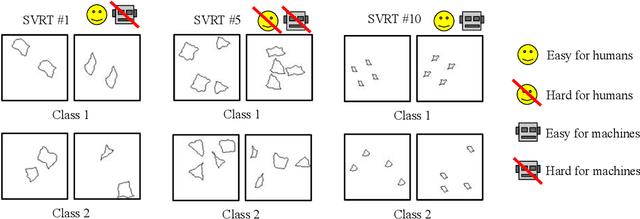
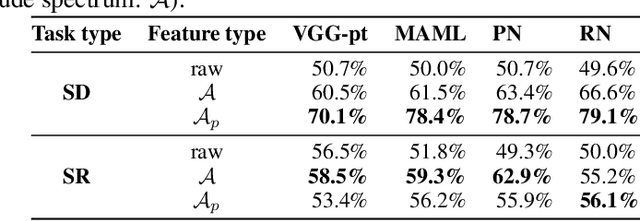

We present an image preprocessing technique capable of improving the performance of few-shot classifiers on abstract visual reasoning tasks. Many visual reasoning tasks with abstract features are easy for humans to learn with few examples but very difficult for computer vision approaches with the same number of samples, despite the ability for deep learning models to learn abstract features. Same-different (SD) problems represent a type of visual reasoning task requiring knowledge of pattern repetition within individual images, and modern computer vision approaches have largely faltered on these classification problems, even when provided with vast amounts of training data. We propose a simple method for solving these problems based on the insight that removing peaks from the amplitude spectrum of an image is capable of emphasizing the unique parts of the image. When combined with several classifiers, our method performs well on the SD SVRT tasks with few-shot learning, improving upon the best comparable results on all tasks, with average absolute accuracy increases nearly 40% for some classifiers. In particular, we find that combining Relational Networks with this image preprocessing approach improves their performance from chance-level to over 90% accuracy on several SD tasks.
Neural Sentence Location Prediction for Summarization
Apr 22, 2018
A competitive baseline in sentence-level extractive summarization of news articles is the Lead-3 heuristic, where only the first 3 sentences are extracted. The success of this method is due to the tendency for writers to implement progressive elaboration in their work by writing the most important content at the beginning. In this paper, we introduce the Lead-like Recognizer (LeadR) to show how the Lead heuristic can be extended to summarize multi-section documents where it would not usually work well. This is done by introducing a neural model which produces a probability distribution over positions for sentences, so that we can locate sentences with introduction-like qualities. To evaluate the performance of our model, we use the task of summarizing multi-section documents. LeadR outperforms several baselines on this task, including a simple extension of the Lead heuristic designed for the task. Our work suggests that predicted position is a strong feature to use when extracting summaries.