 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Detecting Money Laundering Activities on the Bitcoin Network
Dec 27, 2019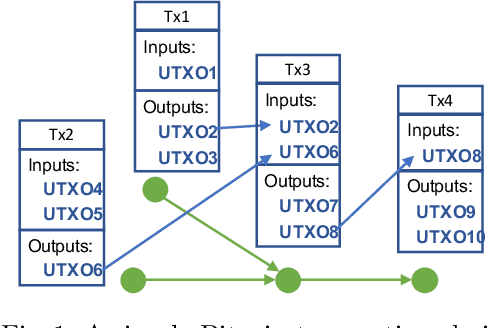

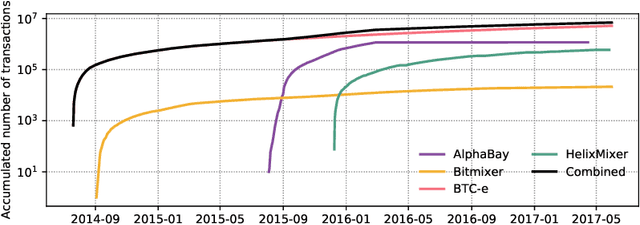
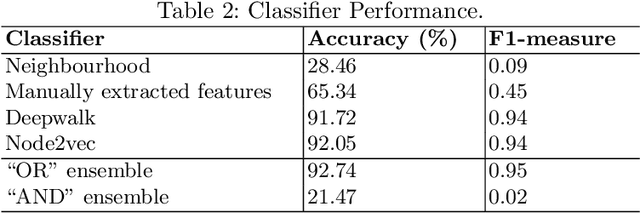
Bitcoin is by far the most popular crypto-currency solution enabling peer-to-peer payments. Despite some studies highlighting the network does not provide full anonymity, it is still being heavily used for a wide variety of dubious financial activities such as money laundering, ponzi schemes, and ransom-ware payments. In this paper, we explore the landscape of potential money laundering activities occurring across the Bitcoin network. Using data collected over three years, we create transaction graphs and provide an in-depth analysis on various graph characteristics to differentiate money laundering transactions from regular transactions. We found that the main difference between laundering and regular transactions lies in their output values and neighbourhood information. Then, we propose and evaluate a set of classifiers based on four types of graph features: immediate neighbours, curated features, deepwalk embeddings, and node2vec embeddings to classify money laundering and regular transactions. Results show that the node2vec-based classifier outperforms other classifiers in binary classification reaching an average accuracy of 92.29% and an F1-measure of 0.93 and high robustness over a 2.5-year time span. Finally, we demonstrate how effective our classifiers are in discovering unknown laundering services. The classifier performance dropped compared to binary classification, however, the prediction can be improved with simple ensemble techniques for some services.
Few-Shot Abstract Visual Reasoning With Spectral Features
Oct 04, 2019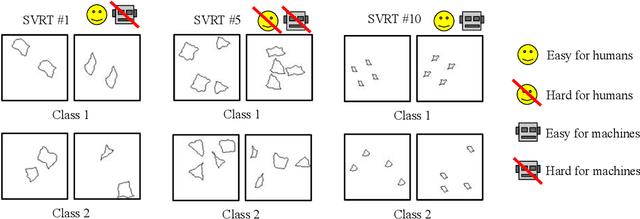
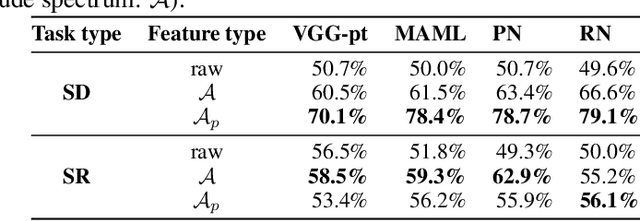
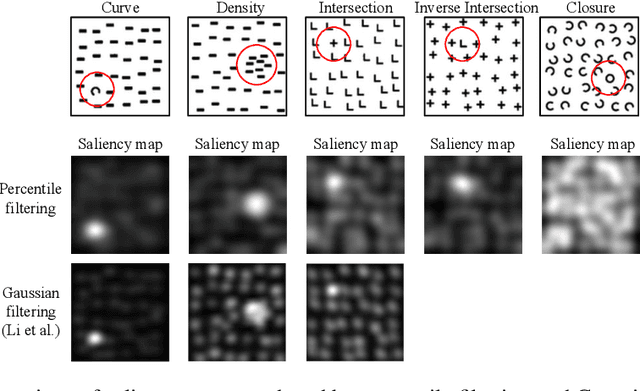

We present an image preprocessing technique capable of improving the performance of few-shot classifiers on abstract visual reasoning tasks. Many visual reasoning tasks with abstract features are easy for humans to learn with few examples but very difficult for computer vision approaches with the same number of samples, despite the ability for deep learning models to learn abstract features. Same-different (SD) problems represent a type of visual reasoning task requiring knowledge of pattern repetition within individual images, and modern computer vision approaches have largely faltered on these classification problems, even when provided with vast amounts of training data. We propose a simple method for solving these problems based on the insight that removing peaks from the amplitude spectrum of an image is capable of emphasizing the unique parts of the image. When combined with several classifiers, our method performs well on the SD SVRT tasks with few-shot learning, improving upon the best comparable results on all tasks, with average absolute accuracy increases nearly 40% for some classifiers. In particular, we find that combining Relational Networks with this image preprocessing approach improves their performance from chance-level to over 90% accuracy on several SD tasks.
BreathRNNet: Breathing Based Authentication on Resource-Constrained IoT Devices using RNNs
Sep 22, 2017
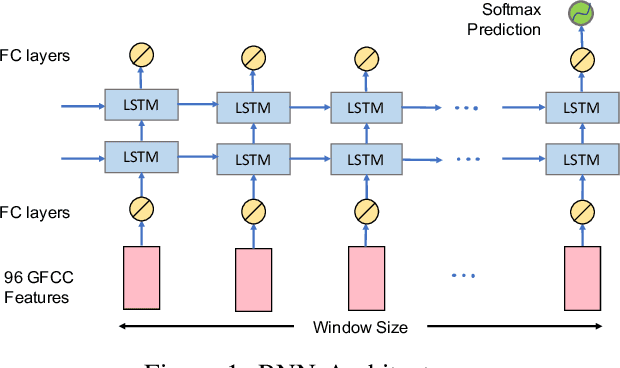
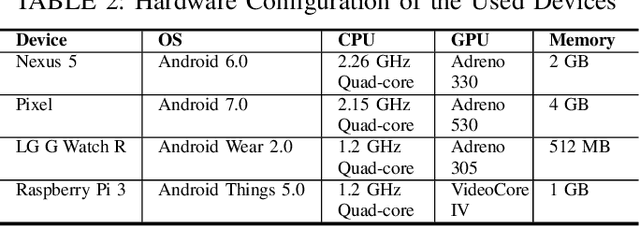
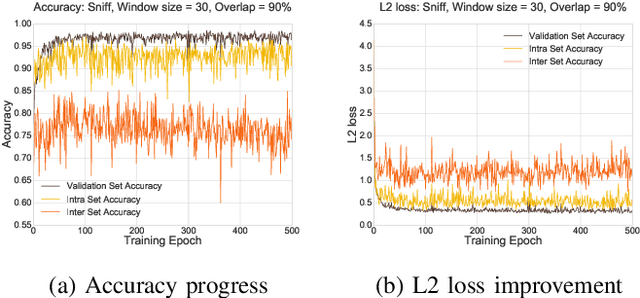
Recurrent neural networks (RNNs) have shown promising results in audio and speech processing applications due to their strong capabilities in modelling sequential data. In many applications, RNNs tend to outperform conventional models based on GMM/UBMs and i-vectors. Increasing popularity of IoT devices makes a strong case for implementing RNN based inferences for applications such as acoustics based authentication, voice commands, and edge analytics for smart homes. Nonetheless, the feasibility and performance of RNN based inferences on resources-constrained IoT devices remain largely unexplored. In this paper, we investigate the feasibility of using RNNs for an end-to-end authentication system based on breathing acoustics. We evaluate the performance of RNN models on three types of devices; smartphone, smartwatch, and Raspberry Pi and show that unlike CNN models, RNN models can be easily ported onto resource-constrained devices without a significant loss in accuracy.