 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallax: Runtime Parallelization for Operator Fallbacks in Heterogeneous Edge Systems
Dec 12, 2025
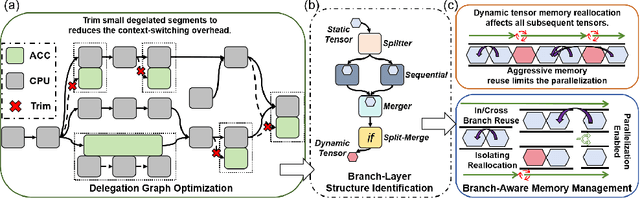


The growing demand for real-time DNN applications on edge devices necessitates faster inference of increasingly complex models. Although many devices include specialized accelerators (e.g., mobile GPUs), dynamic control-flow operators and unsupported kernels often fall back to CPU execution. Existing frameworks handle these fallbacks poorly, leaving CPU cores idle and causing high latency and memory spikes. We introduce Parallax, a framework that accelerates mobile DNN inference without model refactoring or custom operator implementations. Parallax first partitions the computation DAG to expose parallelism, then employs branch-aware memory management with dedicated arenas and buffer reuse to reduce runtime footprint. An adaptive scheduler executes branches according to device memory constraints, meanwhile, fine-grained subgraph control enables heterogeneous inference of dynamic models. By evaluating on five representative DNNs across three different mobile devices, Parallax achieves up to 46% latency reduction, maintains controlled memory overhead (26.5% on average), and delivers up to 30% energy savings compared with state-of-the-art frameworks, offering improvements aligned with the responsiveness demands of real-time mobile inference.
ViRN: Variational Inference and Distribution Trilateration for Long-Tailed Continual Representation Learning
Jul 23, 2025


Continual learning (CL) with long-tailed data distributions remains a critical challenge for real-world AI systems, where models must sequentially adapt to new classes while retaining knowledge of old ones, despite severe class imbalance. Existing methods struggle to balance stability and plasticity, often collapsing under extreme sample scarcity. To address this, we propose ViRN, a novel CL framework that integrates variational inference (VI) with distributional trilateration for robust long-tailed learning. First, we model class-conditional distributions via a Variational Autoencoder to mitigate bias toward head classes. Second, we reconstruct tail-class distributions via Wasserstein distance-based neighborhood retrieval and geometric fusion, enabling sample-efficient alignment of tail-class representations. Evaluated on six long-tailed classification benchmarks, including speech (e.g., rare acoustic events, accents) and image tasks, ViRN achieves a 10.24% average accuracy gain over state-of-the-art methods.
Continual Generalized Category Discovery: Learning and Forgetting from a Bayesian Perspective
Jul 23, 2025Continual Generalized Category Discovery (C-GCD) faces a critical challenge: incrementally learning new classes from unlabeled data streams while preserving knowledge of old classes. Existing methods struggle with catastrophic forgetting, especially when unlabeled data mixes known and novel categories. We address this by analyzing C-GCD's forgetting dynamics through a Bayesian lens, revealing that covariance misalignment between old and new classes drives performance degradation. Building on this insight, we propose Variational Bayes C-GCD (VB-CGCD), a novel framework that integrates variational inference with covariance-aware nearest-class-mean classification. VB-CGCD adaptively aligns class distributions while suppressing pseudo-label noise via stochastic variational updates. Experiments show VB-CGCD surpasses prior art by +15.21% with the overall accuracy in the final session on standard benchmarks. We also introduce a new challenging benchmark with only 10% labeled data and extended online phases, VB-CGCD achieves a 67.86% final accuracy, significantly higher than state-of-the-art (38.55%), demonstrating its robust applicability across diverse scenarios. Code is available at: https://github.com/daihao42/VB-CGCD
The Starlink Robot: A Platform and Dataset for Mobile Satellite Communication
Jun 24, 2025The integration of satellite communication into mobile devices represents a paradigm shift in connectivity, yet the performance characteristics under motion and environmental occlusion remain poorly understood. We present the Starlink Robot, the first mobile robotic platform equipped with Starlink satellite internet, comprehensive sensor suite including upward-facing camera, LiDAR, and IMU, designed to systematically study satellite communication performance during movement. Our multi-modal dataset captures synchronized communication metrics, motion dynamics, sky visibility, and 3D environmental context across diverse scenarios including steady-state motion, variable speeds, and different occlusion conditions. This platform and dataset enable researchers to develop motion-aware communication protocols, predict connectivity disruptions, and optimize satellite communication for emerging mobile applications from smartphones to autonomous vehicles. The project is available at https://github.com/StarlinkRobot.
Towards Open Respiratory Acoustic Foundation Models: Pretraining and Benchmarking
Jun 23, 2024



Respiratory audio, such as coughing and breathing sounds, has predictive power for a wide range of healthcare applications, yet is currently under-explored. The main problem for those applications arises from the difficulty in collecting large labeled task-specific data for model development. Generalizable respiratory acoustic foundation models pretrained with unlabeled data would offer appealing advantages and possibly unlock this impasse. However, given the safety-critical nature of healthcare applications, it is pivotal to also ensure openness and replicability for any proposed foundation model solution. To this end, we introduce OPERA, an OPEn Respiratory Acoustic foundation model pretraining and benchmarking system, as the first approach answering this need. We curate large-scale respiratory audio datasets (~136K samples, 440 hours), pretrain three pioneering foundation models, and build a benchmark consisting of 19 downstream respiratory health tasks for evaluation. Our pretrained models demonstrate superior performance (against existing acoustic models pretrained with general audio on 16 out of 19 tasks) and generalizability (to unseen datasets and new respiratory audio modalities). This highlights the great promise of respiratory acoustic foundation models and encourages more studies using OPERA as an open resource to accelerate research on respiratory audio for health. The system is accessible from https://github.com/evelyn0414/OPERA.
LifeLearner: Hardware-Aware Meta Continual Learning System for Embedded Computing Platforms
Nov 19, 2023Continual Learning (CL) allows applications such as user personalization and household robots to learn on the fly and adapt to context. This is an important feature when context, actions, and users change. However, enabling CL on resource-constrained embedded systems is challenging due to the limited labeled data, memory, and computing capacity. In this paper, we propose LifeLearner, a hardware-aware meta continual learning system that drastically optimizes system resources (lower memory, latency, energy consumption) while ensuring high accuracy. Specifically, we (1) exploit meta-learning and rehearsal strategies to explicitly cope with data scarcity issues and ensure high accuracy, (2) effectively combine lossless and lossy compression to significantly reduce the resource requirements of CL and rehearsal samples, and (3) developed hardware-aware system on embedded and IoT platforms considering the hardware characteristics. As a result, LifeLearner achieves near-optimal CL performance, falling short by only 2.8% on accuracy compared to an Oracle baseline. With respect to the state-of-the-art (SOTA) Meta CL method, LifeLearner drastically reduces the memory footprint (by 178.7x), end-to-end latency by 80.8-94.2%, and energy consumption by 80.9-94.2%. In addition, we successfully deployed LifeLearner on two edge devices and a microcontroller unit, thereby enabling efficient CL on resource-constrained platforms where it would be impractical to run SOTA methods and the far-reaching deployment of adaptable CL in a ubiquitous manner. Code is available at https://github.com/theyoungkwon/LifeLearner.
TinyTrain: Deep Neural Network Training at the Extreme Edge
Jul 19, 2023
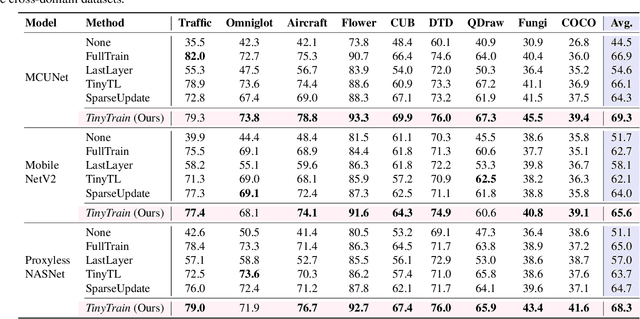
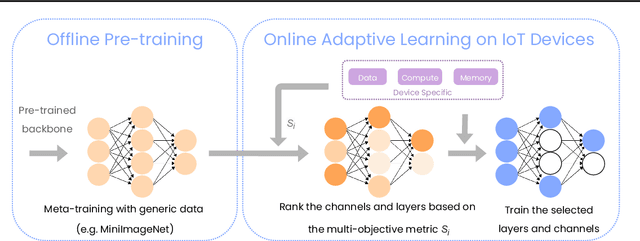
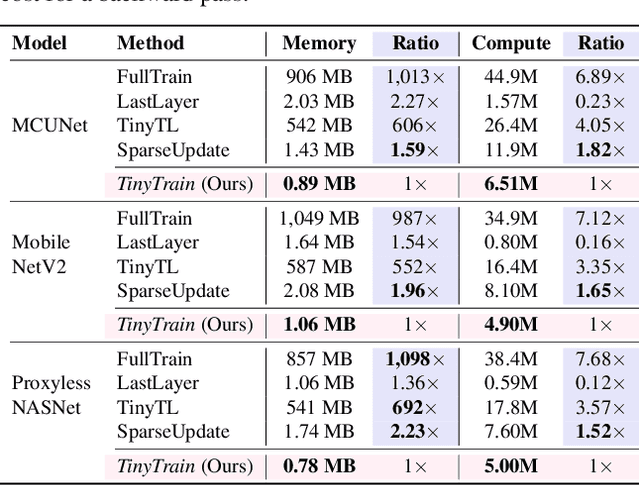
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCU), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss ($\geq$10\%). We propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0\% in accuracy, while reducing the backward-pass memory and computation cost by up to 2,286$\times$ and 7.68$\times$, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5$\times$ faster and 3.5$\times$ more energy-efficient training over status-quo approaches, and 2.8$\times$ smaller memory footprint than SOTA approaches, while remaining within the 1 MB memory envelope of MCU-grade platforms.
who is snoring? snore based user recognition
Jan 28, 2023Snoring is one of the most prominent symptoms of Obstructive Sleep Apnea-Hypopnea Syndrome (OSAH), a highly prevalent disease that causes repetitive collapse and cessation of the upper airway. Thus, accurate snore sound monitoring and analysis is crucial. However, the traditional monitoring method polysomnography (PSG) requires the patients to stay at a sleep clinic for the whole night and be connected to many pieces of equipment. An alternative and less invasive way is passive monitoring using a smartphone at home or in the clinical settings. But, there is a challenge: the environment may be shared by people such that the raw audio may contain the snore activities of the bed partner or other person. False capturing of the snoring activity could lead to critical false alarms and misdiagnosis of the patients. To address this limitation, we propose a hypothesis that snore sound contains unique identity information which can be used for user recognition. We analyzed various machine learning models: Gaussian Mixture Model (GMM), GMM-UBM (Universial Background Model), and a Deep Neural Network (DNN) on MPSSC - an open source snoring dataset to evaluate the validity of our hypothesis. Our results are promising as we achieved around 90% accuracy in identification and verification tasks. This work marks the first step towards understanding the practicality of snore based user monitoring to enable multiple healthcare applicaitons.
YONO: Modeling Multiple Heterogeneous Neural Networks on Microcontrollers
Mar 08, 2022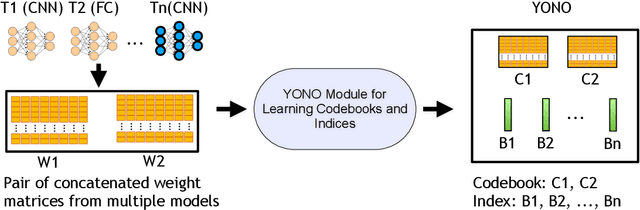
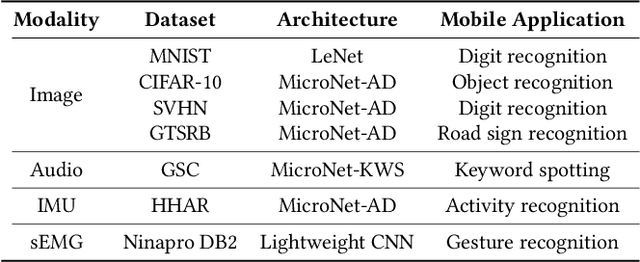
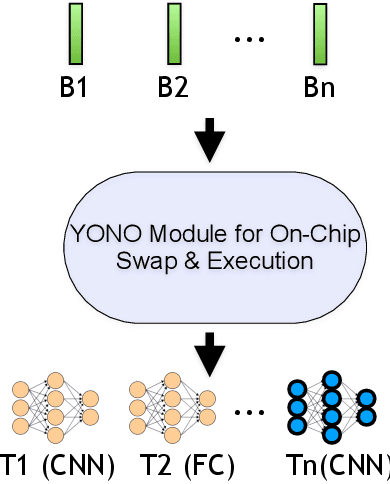

With the advancement of Deep Neural Networks (DNN) and large amounts of sensor data from Internet of Things (IoT) systems, the research community has worked to reduce the computational and resource demands of DNN to compute on low-resourced microcontrollers (MCUs). However, most of the current work in embedded deep learning focuses on solving a single task efficiently, while the multi-tasking nature and applications of IoT devices demand systems that can handle a diverse range of tasks (activity, voice, and context recognition) with input from a variety of sensors, simultaneously. In this paper, we propose YONO, a product quantization (PQ) based approach that compresses multiple heterogeneous models and enables in-memory model execution and switching for dissimilar multi-task learning on MCUs. We first adopt PQ to learn codebooks that store weights of different models. Also, we propose a novel network optimization and heuristics to maximize the compression rate and minimize the accuracy loss. Then, we develop an online component of YONO for efficient model execution and switching between multiple tasks on an MCU at run time without relying on an external storage device. YONO shows remarkable performance as it can compress multiple heterogeneous models with negligible or no loss of accuracy up to 12.37$\times$. Besides, YONO's online component enables an efficient execution (latency of 16-159 ms per operation) and reduces model loading/switching latency and energy consumption by 93.3-94.5% and 93.9-95.0%, respectively, compared to external storage access. Interestingly, YONO can compress various architectures trained with datasets that were not shown during YONO's offline codebook learning phase showing the generalizability of our method. To summarize, YONO shows great potential and opens further doors to enable multi-task learning systems on extremely resource-constrained devices.
Enabling On-Device Smartphone GPU based Training: Lessons Learned
Feb 21, 2022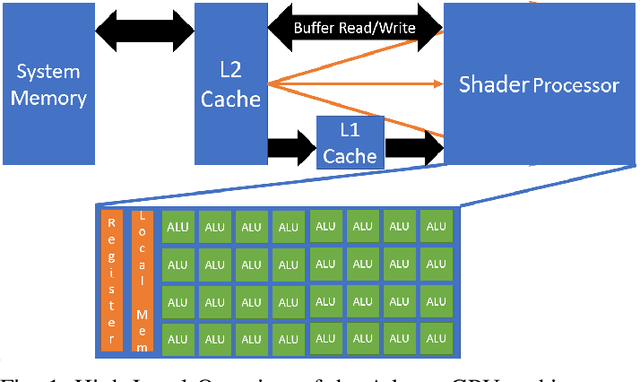
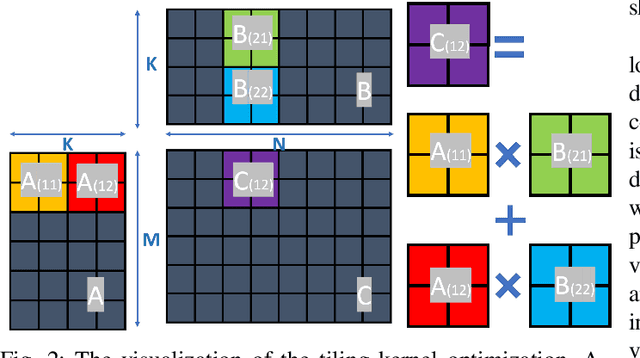
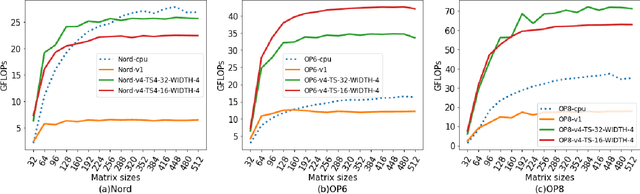
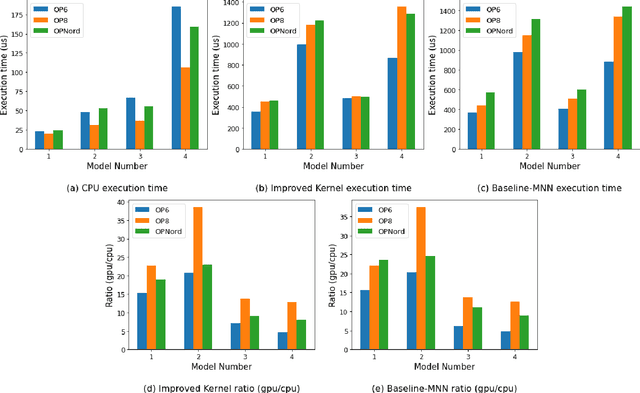
Deep Learning (DL) has shown impressive performance in many mobile applications. Most existing works have focused on reducing the computational and resource overheads of running Deep Neural Networks (DNN) inference on resource-constrained mobile devices. However, the other aspect of DNN operations, i.e. training (forward and backward passes) on smartphone GPUs, has received little attention thus far. To this end, we conduct an initial analysis to examine the feasibility of on-device training on smartphones using mobile GPUs. We first employ the open-source mobile DL framework (MNN) and its OpenCL backend for running compute kernels on GPUs. Next, we observed that training on CPUs is much faster than on GPUs and identified two possible bottlenecks related to this observation: (i) computation and (ii) memory bottlenecks. To solve the computation bottleneck, we optimize the OpenCL backend's kernels, showing 2x improvements (40-70 GFLOPs) over CPUs (15-30 GFLOPs) on the Snapdragon 8 series processors. However, we find that the full DNN training is still much slower on GPUs than on CPUs, indicating that memory bottleneck plays a significant role in the lower performance of GPU over CPU. The data movement takes almost 91% of training time due to the low bandwidth. Lastly, based on the findings and failures during our investigation, we present limitations and practical guidelines for future directions.