 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Dialect Bird Species Recognition with Dialect-Calibrated Augmentation
Sep 26, 2025Dialect variation hampers automatic recognition of bird calls collected by passive acoustic monitoring. We address the problem on DB3V, a three-region, ten-species corpus of 8-s clips, and propose a deployable framework built on Time-Delay Neural Networks (TDNNs). Frequency-sensitive normalisation (Instance Frequency Normalisation and a gated Relaxed-IFN) is paired with gradient-reversal adversarial training to learn region-invariant embeddings. A multi-level augmentation scheme combines waveform perturbations, Mixup for rare classes, and CycleGAN transfer that synthesises Region 2 (Interior Plains)-style audio, , with Dialect-Calibrated Augmentation (DCA) softly down-weighting synthetic samples to limit artifacts. The complete system lifts cross-dialect accuracy by up to twenty percentage points over baseline TDNNs while preserving in-region performance. Grad-CAM and LIME analyses show that robust models concentrate on stable harmonic bands, providing ecologically meaningful explanations. The study demonstrates that lightweight, transparent, and dialect-resilient bird-sound recognition is attainable.
Audio-based Kinship Verification Using Age Domain Conversion
Oct 14, 2024


Audio-based kinship verification (AKV) is important in many domains, such as home security monitoring, forensic identification, and social network analysis. A key challenge in the task arises from differences in age across samples from different individuals, which can be interpreted as a domain bias in a cross-domain verification task. To address this issue, we design the notion of an "age-standardised domain" wherein we utilise the optimised CycleGAN-VC3 network to perform age-audio conversion to generate the in-domain audio. The generated audio dataset is employed to extract a range of features, which are then fed into a metric learning architecture to verify kinship. Experiments are conducted on the KAN_AV audio dataset, which contains age and kinship labels. The results demonstrate that the method markedly enhances the accuracy of kinship verification, while also offering novel insights for future kinship verification research.
Audio Explanation Synthesis with Generative Foundation Models
Oct 10, 2024



The increasing success of audio foundation models across various tasks has led to a growing need for improved interpretability to understand their intricate decision-making processes better. Existing methods primarily focus on explaining these models by attributing importance to elements within the input space based on their influence on the final decision. In this paper, we introduce a novel audio explanation method that capitalises on the generative capacity of audio foundation models. Our method leverages the intrinsic representational power of the embedding space within these models by integrating established feature attribution techniques to identify significant features in this space. The method then generates listenable audio explanations by prioritising the most important features. Through rigorous benchmarking against standard datasets, including keyword spotting and speech emotion recognition, our model demonstrates its efficacy in producing audio explanations.
Climate Change & Computer Audition: A Call to Action and Overview on Audio Intelligence to Help Save the Planet
Mar 10, 2022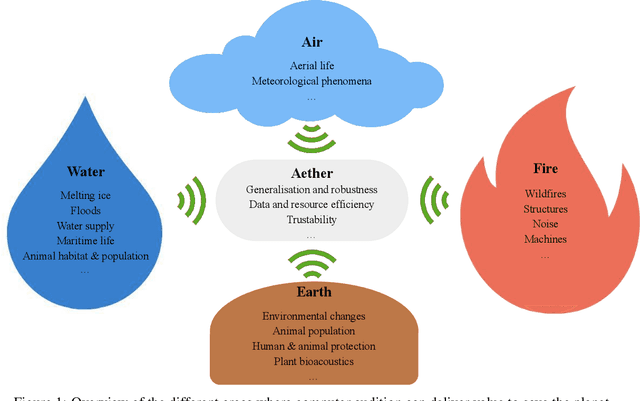
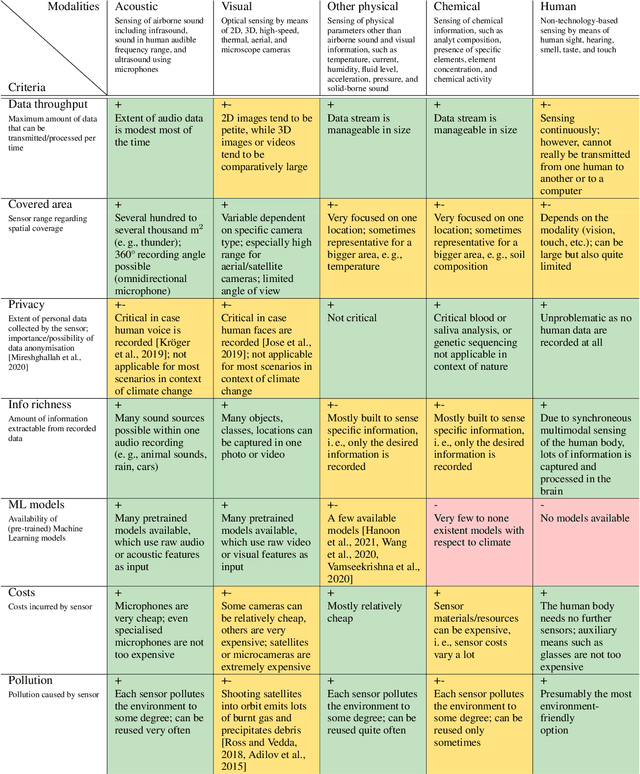
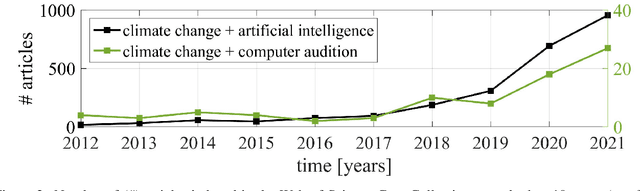
Among the seventeen Sustainable Development Goals (SDGs) proposed within the 2030 Agenda and adopted by all the United Nations member states, the 13$^{th}$ SDG is a call for action to combat climate change for a better world. In this work, we provide an overview of areas in which audio intelligence -- a powerful but in this context so far hardly considered technology -- can contribute to overcome climate-related challenges. We categorise potential computer audition applications according to the five elements of earth, water, air, fire, and aether, proposed by the ancient Greeks in their five element theory; this categorisation serves as a framework to discuss computer audition in relation to different ecological aspects. Earth and water are concerned with the early detection of environmental changes and, thus, with the protection of humans and animals, as well as the monitoring of land and aquatic organisms. Aerial audio is used to monitor and obtain information about bird and insect populations. Furthermore, acoustic measures can deliver relevant information for the monitoring and forecasting of weather and other meteorological phenomena. The fourth considered element is fire. Due to the burning of fossil fuels, the resulting increase in CO$_2$ emissions and the associated rise in temperature, fire is used as a symbol for man-made climate change and in this context includes the monitoring of noise pollution, machines, as well as the early detection of wildfires. In all these areas, computer audition can help counteract climate change. Aether then corresponds to the technology itself that makes this possible. This work explores these areas and discusses potential applications, while positioning computer audition in relation to methodological alternatives.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022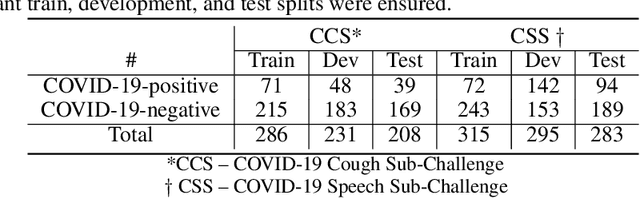
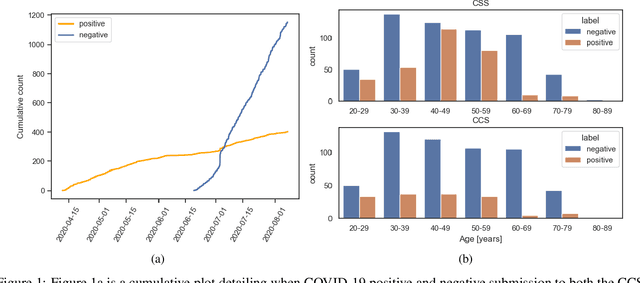
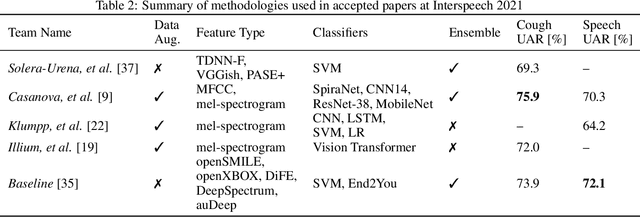
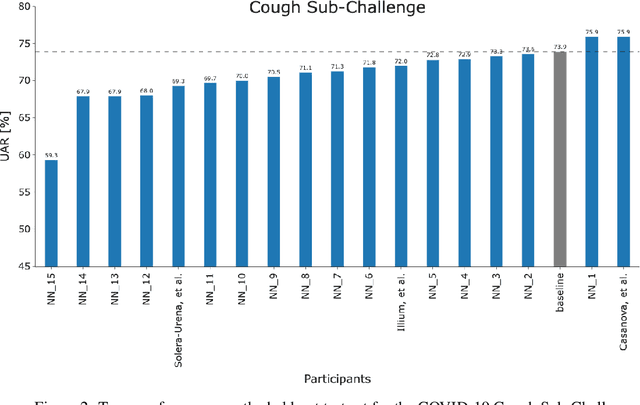
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
Evaluating the COVID-19 Identification ResNet (CIdeR) on the INTERSPEECH COVID-19 from Audio Challenges
Jul 30, 2021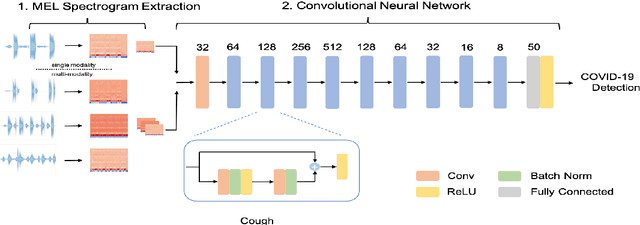
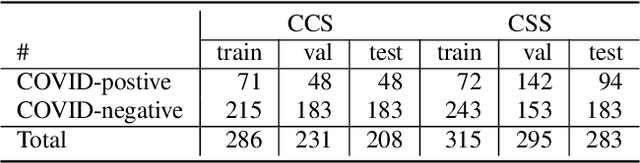
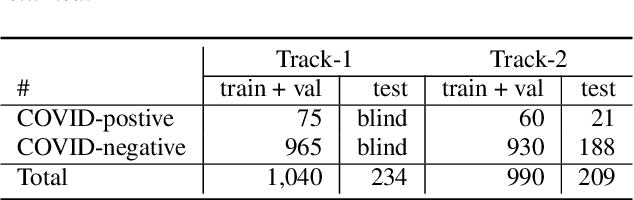
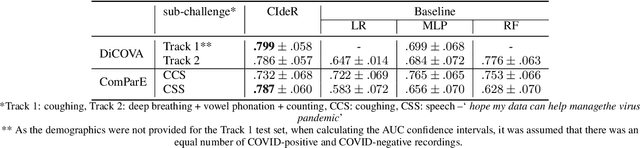
We report on cross-running the recent COVID-19 Identification ResNet (CIdeR) on the two Interspeech 2021 COVID-19 diagnosis from cough and speech audio challenges: ComParE and DiCOVA. CIdeR is an end-to-end deep learning neural network originally designed to classify whether an individual is COVID-positive or COVID-negative based on coughing and breathing audio recordings from a published crowdsourced dataset. In the current study, we demonstrate the potential of CIdeR at binary COVID-19 diagnosis from both the COVID-19 Cough and Speech Sub-Challenges of INTERSPEECH 2021, ComParE and DiCOVA. CIdeR achieves significant improvements over several baselines.