 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal Latent Representations for the Analysis of Acoustic Scenes in-the-wild
Dec 10, 2024In the field of acoustic scene analysis, this paper presents a novel approach to find spatio-temporal latent representations from in-the-wild audio data. By using WE-LIVE, an in-house collected dataset that includes audio recordings in diverse real-world environments together with sparse GPS coordinates, self-annotated emotional and situational labels, we tackle the challenging task of associating each audio segment with its corresponding location as a pretext task, with the final aim of acoustically detecting violent (anomalous) contexts, left as further work. By generating acoustic embeddings and using the self-supervised learning paradigm, we aim to use the model-generated latent space to acoustically characterize the spatio-temporal context. We use YAMNet, an acoustic events classifier trained in AudioSet to temporally locate and identify acoustic events in WE-LIVE. In order to transform the discrete acoustic events into embeddings, we compare the information-retrieval-based TF-IDF algorithm and Node2Vec as an analogy to Natural Language Processing techniques. A VAE is then trained to provide a further adapted latent space. The analysis was carried out by measuring the cosine distance and visualizing data distribution via t-Distributed Stochastic Neighbor Embedding, revealing distinct acoustic scenes. Specifically, we discern variations between indoor and subway environments. Notably, these distinctions emerge within the latent space of the VAE, a stark contrast to the random distribution of data points before encoding. In summary, our research contributes a pioneering approach for extracting spatio-temporal latent representations from in-the-wild audio data.
Fatigue Prediction in Outdoor Running Conditions using Audio Data
May 09, 2022
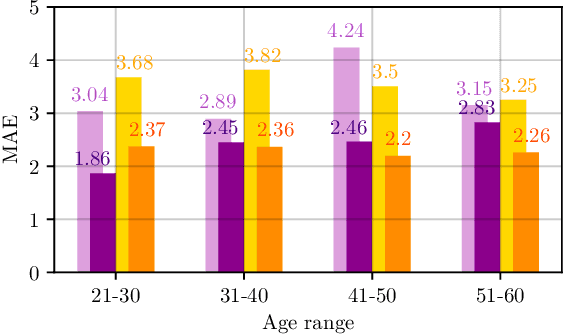
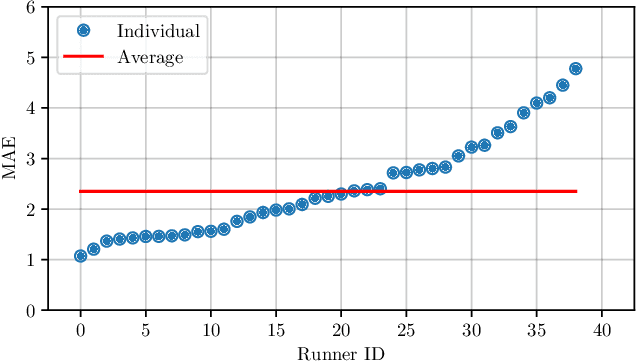

Although running is a common leisure activity and a core training regiment for several athletes, between $29\%$ and $79\%$ of runners sustain an overuse injury each year. These injuries are linked to excessive fatigue, which alters how someone runs. In this work, we explore the feasibility of modelling the Borg received perception of exertion (RPE) scale (range: $[6-20]$), a well-validated subjective measure of fatigue, using audio data captured in realistic outdoor environments via smartphones attached to the runners' arms. Using convolutional neural networks (CNNs) on log-Mel spectrograms, we obtain a mean absolute error of $2.35$ in subject-dependent experiments, demonstrating that audio can be effectively used to model fatigue, while being more easily and non-invasively acquired than by signals from other sensors.
Climate Change & Computer Audition: A Call to Action and Overview on Audio Intelligence to Help Save the Planet
Mar 10, 2022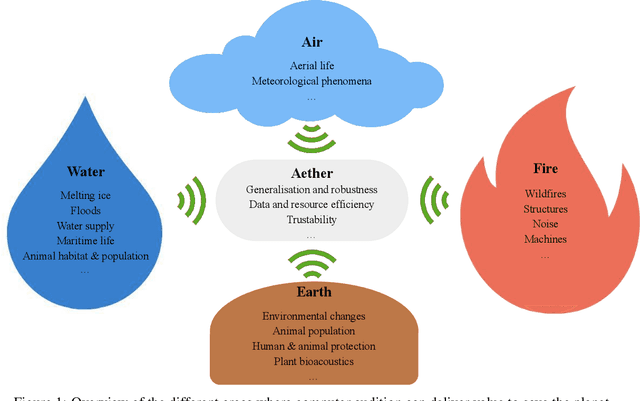
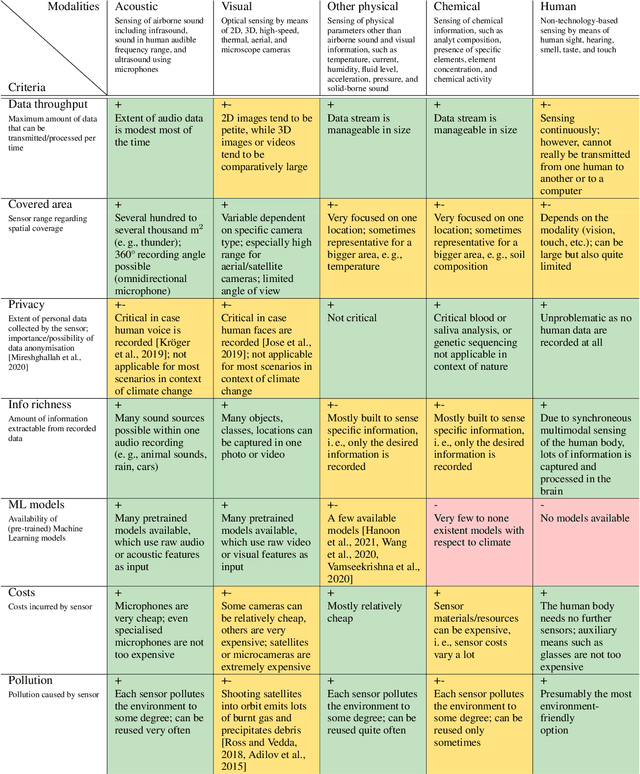
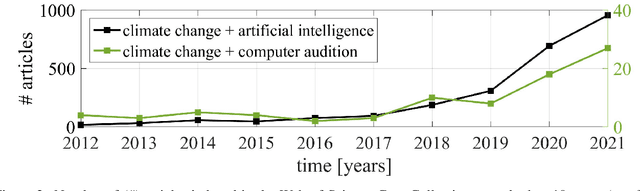
Among the seventeen Sustainable Development Goals (SDGs) proposed within the 2030 Agenda and adopted by all the United Nations member states, the 13$^{th}$ SDG is a call for action to combat climate change for a better world. In this work, we provide an overview of areas in which audio intelligence -- a powerful but in this context so far hardly considered technology -- can contribute to overcome climate-related challenges. We categorise potential computer audition applications according to the five elements of earth, water, air, fire, and aether, proposed by the ancient Greeks in their five element theory; this categorisation serves as a framework to discuss computer audition in relation to different ecological aspects. Earth and water are concerned with the early detection of environmental changes and, thus, with the protection of humans and animals, as well as the monitoring of land and aquatic organisms. Aerial audio is used to monitor and obtain information about bird and insect populations. Furthermore, acoustic measures can deliver relevant information for the monitoring and forecasting of weather and other meteorological phenomena. The fourth considered element is fire. Due to the burning of fossil fuels, the resulting increase in CO$_2$ emissions and the associated rise in temperature, fire is used as a symbol for man-made climate change and in this context includes the monitoring of noise pollution, machines, as well as the early detection of wildfires. In all these areas, computer audition can help counteract climate change. Aether then corresponds to the technology itself that makes this possible. This work explores these areas and discusses potential applications, while positioning computer audition in relation to methodological alternatives.
WEMAC: Women and Emotion Multi-modal Affective Computing dataset
Mar 01, 2022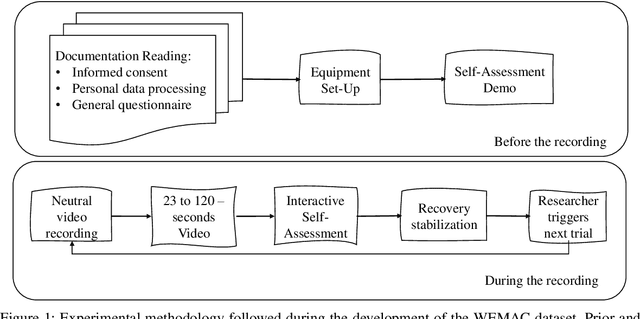

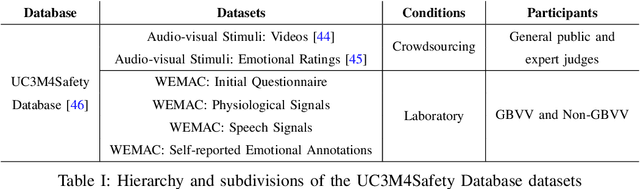

Among the seventeen Sustainable Development Goals (SDGs) proposed within the 2030 Agenda and adopted by all the United Nations member states, the Fifth SDG is a call for action to turn Gender Equality into a fundamental human right and an essential foundation for a better world. It includes the eradication of all types of violence against women. Within this context, the UC3M4Safety research team aims to develop Bindi. This is a cyber-physical system which includes embedded Artificial Intelligence algorithms, for user real-time monitoring towards the detection of affective states, with the ultimate goal of achieving the early detection of risk situations for women. On this basis, we make use of wearable affective computing including smart sensors, data encryption for secure and accurate collection of presumed crime evidence, as well as the remote connection to protecting agents. Towards the development of such system, the recordings of different laboratory and into-the-wild datasets are in process. These are contained within the UC3M4Safety Database. Thus, this paper presents and details the first release of WEMAC, a novel multi-modal dataset, which comprises a laboratory-based experiment for 47 women volunteers that were exposed to validated audio-visual stimuli to induce real emotions by using a virtual reality headset while physiological, speech signals and self-reports were acquired and collected. We believe this dataset will serve and assist research on multi-modal affective computing using physiological and speech information.