 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023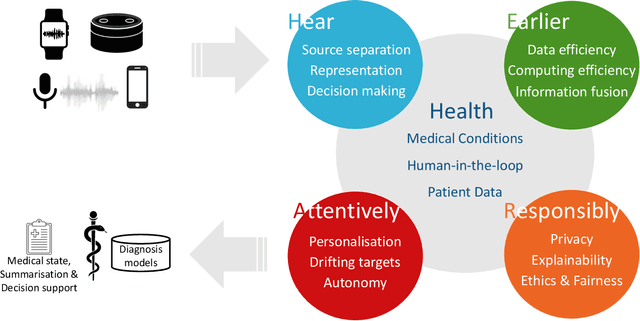

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
Fatigue Prediction in Outdoor Running Conditions using Audio Data
May 09, 2022
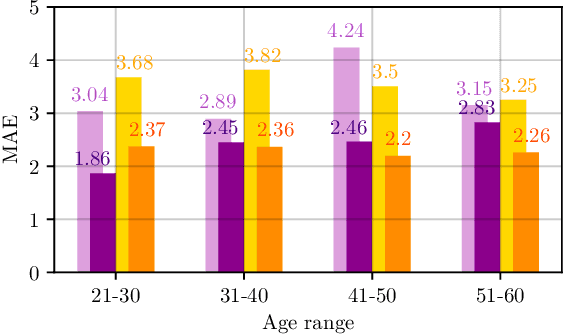
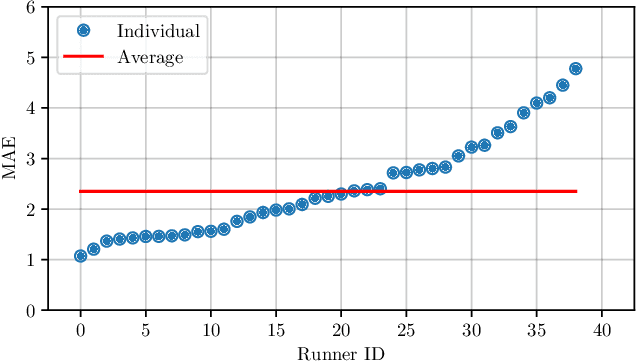

Although running is a common leisure activity and a core training regiment for several athletes, between $29\%$ and $79\%$ of runners sustain an overuse injury each year. These injuries are linked to excessive fatigue, which alters how someone runs. In this work, we explore the feasibility of modelling the Borg received perception of exertion (RPE) scale (range: $[6-20]$), a well-validated subjective measure of fatigue, using audio data captured in realistic outdoor environments via smartphones attached to the runners' arms. Using convolutional neural networks (CNNs) on log-Mel spectrograms, we obtain a mean absolute error of $2.35$ in subject-dependent experiments, demonstrating that audio can be effectively used to model fatigue, while being more easily and non-invasively acquired than by signals from other sensors.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022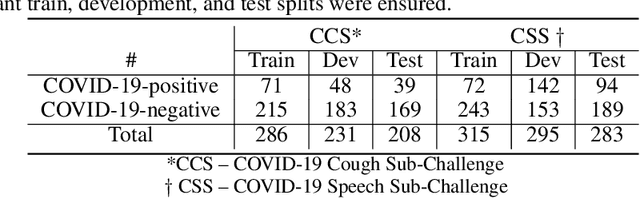
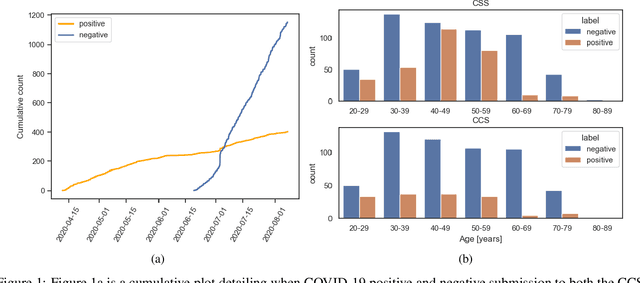
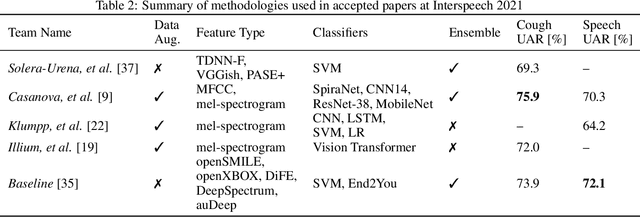
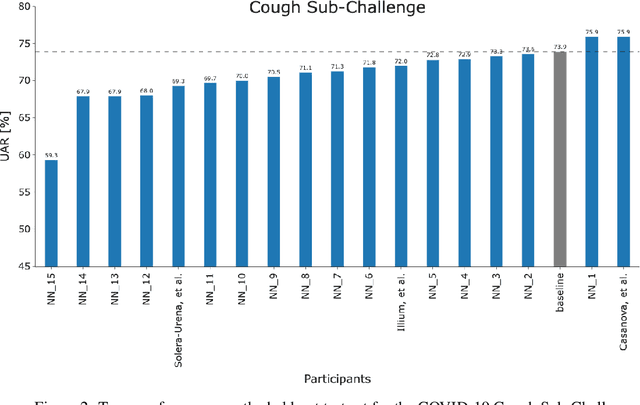
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
A Machine Learning Framework for Automatic Prediction of Human Semen Motility
Sep 17, 2021



In this paper, human semen samples from the visem dataset collected by the Simula Research Laboratory are automatically assessed with machine learning methods for their quality in respect to sperm motility. Several regression models are trained to automatically predict the percentage (0 to 100) of progressive, non-progressive, and immotile spermatozoa in a given sample. The video samples are adopted for three different feature extraction methods, in particular custom movement statistics, displacement features, and motility specific statistics have been utilised. Furthermore, four machine learning models, including linear Support Vector Regressor (SVR), Multilayer Perceptron (MLP), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN), have been trained on the extracted features for the task of automatic motility prediction. Best results for predicting motility are achieved by using the Crocker-Grier algorithm to track sperm cells in an unsupervised way and extracting individual mean squared displacement features for each detected track. These features are then aggregated into a histogram representation applying a Bag-of-Words approach. Finally, a linear SVR is trained on this feature representation. Compared to the best submission of the Medico Multimedia for Medicine challenge, which used the same dataset and splits, the Mean Absolute Error (MAE) could be reduced from 8.83 to 7.31. For the sake of reproducibility, we provide the source code for our experiments on GitHub.
DeepSpectrumLite: A Power-Efficient Transfer Learning Framework for Embedded Speech and Audio Processing from Decentralised Data
Apr 23, 2021



Deep neural speech and audio processing systems have a large number of trainable parameters, a relatively complex architecture, and require a vast amount of training data and computational power. These constraints make it more challenging to integrate such systems into embedded devices and utilise them for real-time, real-world applications. We tackle these limitations by introducing DeepSpectrumLite, an open-source, lightweight transfer learning framework for on-device speech and audio recognition using pre-trained image convolutional neural networks (CNNs). The framework creates and augments Mel-spectrogram plots on-the-fly from raw audio signals which are then used to finetune specific pre-trained CNNs for the target classification task. Subsequently, the whole pipeline can be run in real-time with a mean inference lag of 242.0 ms when a DenseNet121 model is used on a consumer-grade Motorola moto e7 plus smartphone. DeepSpectrumLite operates decentralised, eliminating the need for data upload for further processing. By obtaining state-of-the-art results on a set of paralinguistics tasks, we demonstrate the suitability of the proposed transfer learning approach for embedded audio signal processing, even when data is scarce. We provide an extensive command-line interface for users and developers which is comprehensively documented and publicly available at https://github.com/DeepSpectrum/DeepSpectrumLite.
On the Impact of Word Error Rate on Acoustic-Linguistic Speech Emotion Recognition: An Update for the Deep Learning Era
Apr 20, 2021
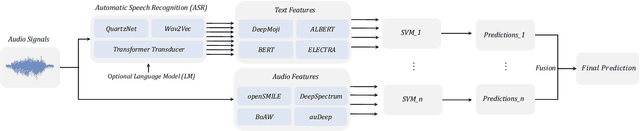
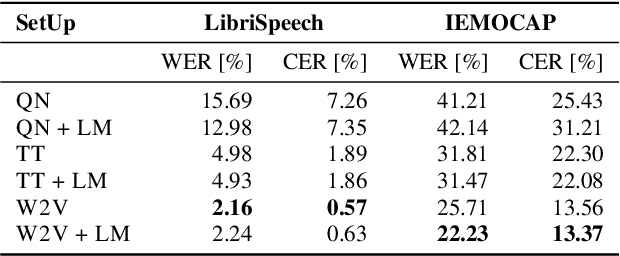

Text encodings from automatic speech recognition (ASR) transcripts and audio representations have shown promise in speech emotion recognition (SER) ever since. Yet, it is challenging to explain the effect of each information stream on the SER systems. Further, more clarification is required for analysing the impact of ASR's word error rate (WER) on linguistic emotion recognition per se and in the context of fusion with acoustic information exploitation in the age of deep ASR systems. In order to tackle the above issues, we create transcripts from the original speech by applying three modern ASR systems, including an end-to-end model trained with recurrent neural network-transducer loss, a model with connectionist temporal classification loss, and a wav2vec framework for self-supervised learning. Afterwards, we use pre-trained textual models to extract text representations from the ASR outputs and the gold standard. For extraction and learning of acoustic speech features, we utilise openSMILE, openXBoW, DeepSpectrum, and auDeep. Finally, we conduct decision-level fusion on both information streams -- acoustics and linguistics. Using the best development configuration, we achieve state-of-the-art unweighted average recall values of $73.6\,\%$ and $73.8\,\%$ on the speaker-independent development and test partitions of IEMOCAP, respectively.
EmoNet: A Transfer Learning Framework for Multi-Corpus Speech Emotion Recognition
Mar 10, 2021



In this manuscript, the topic of multi-corpus Speech Emotion Recognition (SER) is approached from a deep transfer learning perspective. A large corpus of emotional speech data, EmoSet, is assembled from a number of existing SER corpora. In total, EmoSet contains 84181 audio recordings from 26 SER corpora with a total duration of over 65 hours. The corpus is then utilised to create a novel framework for multi-corpus speech emotion recognition, namely EmoNet. A combination of a deep ResNet architecture and residual adapters is transferred from the field of multi-domain visual recognition to multi-corpus SER on EmoSet. Compared against two suitable baselines and more traditional training and transfer settings for the ResNet, the residual adapter approach enables parameter efficient training of a multi-domain SER model on all 26 corpora. A shared model with only $3.5$ times the number of parameters of a model trained on a single database leads to increased performance for 21 of the 26 corpora in EmoSet. Measured by McNemar's test, these improvements are further significant for ten datasets at $p<0.05$ while there are just two corpora that see only significant decreases across the residual adapter transfer experiments. Finally, we make our EmoNet framework publicly available for users and developers at https://github.com/EIHW/EmoNet. EmoNet provides an extensive command line interface which is comprehensively documented and can be used in a variety of multi-corpus transfer learning settings.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021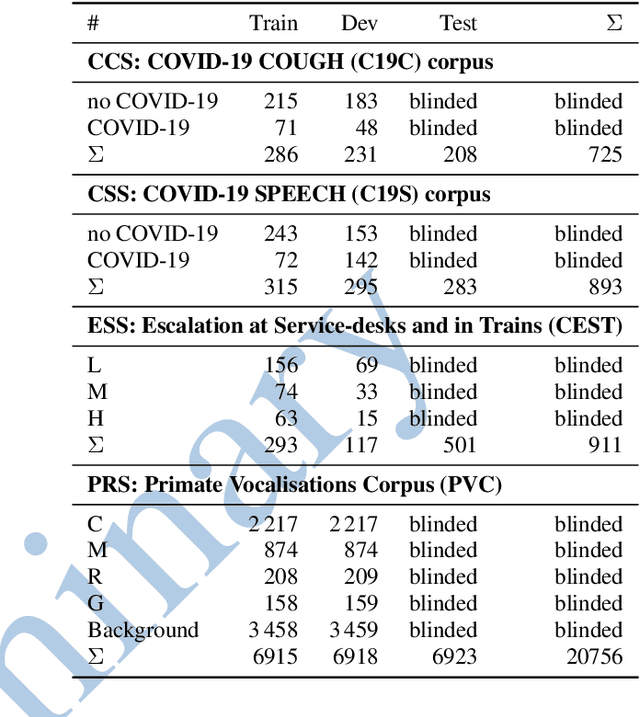
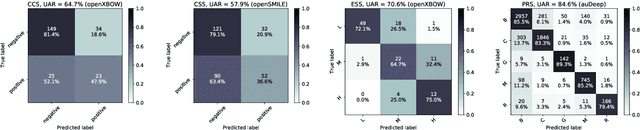
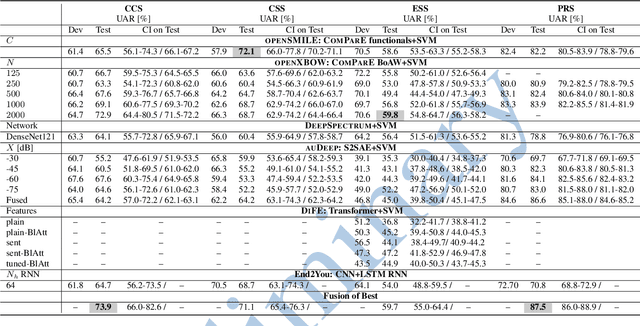
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
A Novel Fusion of Attention and Sequence to Sequence Autoencoders to Predict Sleepiness From Speech
May 19, 2020
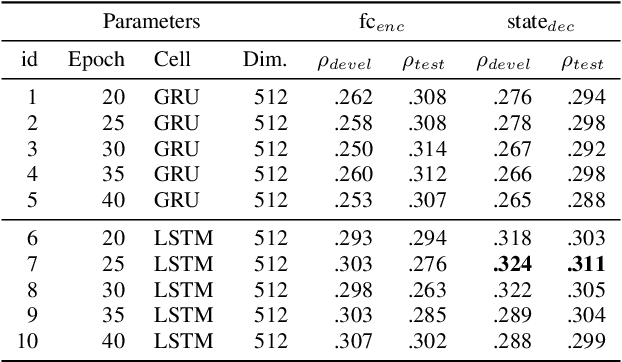
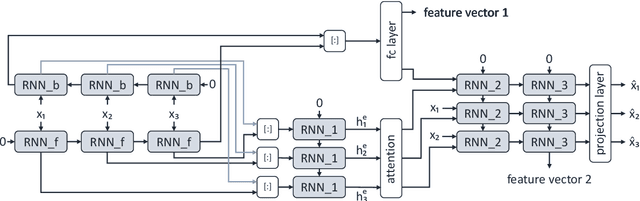
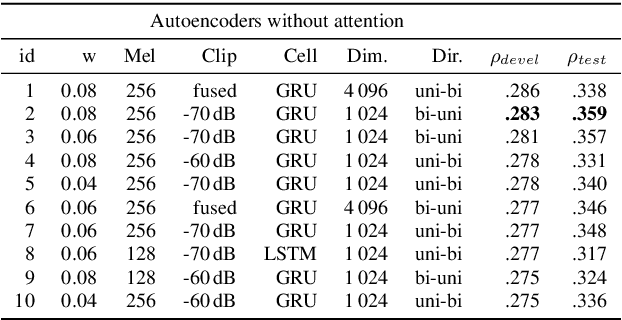
Motivated by the attention mechanism of the human visual system and recent developments in the field of machine translation, we introduce our attention-based and recurrent sequence to sequence autoencoders for fully unsupervised representation learning from audio files. In particular, we test the efficacy of our novel approach on the task of speech-based sleepiness recognition. We evaluate the learnt representations from both autoencoders, and then conduct an early fusion to ascertain possible complementarity between them. In our frameworks, we first extract Mel-spectrograms from raw audio files. Second, we train recurrent autoencoders on these spectrograms which are considered as time-dependent frequency vectors. Afterwards, we extract the activations of specific fully connected layers of the autoencoders which represent the learnt features of spectrograms for the corresponding audio instances. Finally, we train support vector regressors on these representations to obtain the predictions. On the development partition of the data, we achieve Spearman's correlation coefficients of .324, .283, and .320 with the targets on the Karolinska Sleepiness Scale by utilising attention and non-attention autoencoders, and the fusion of both autoencoders' representations, respectively. In the same order, we achieve .311, .359, and .367 Spearman's correlation coefficients on the test data, indicating the suitability of our proposed fusion strategy.