 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Fusion of Attention and Sequence to Sequence Autoencoders to Predict Sleepiness From Speech
May 19, 2020
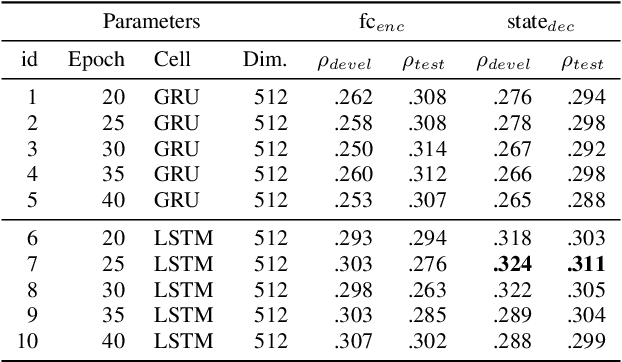
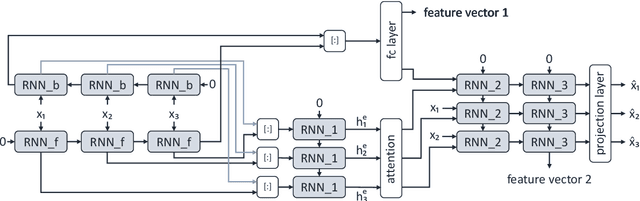
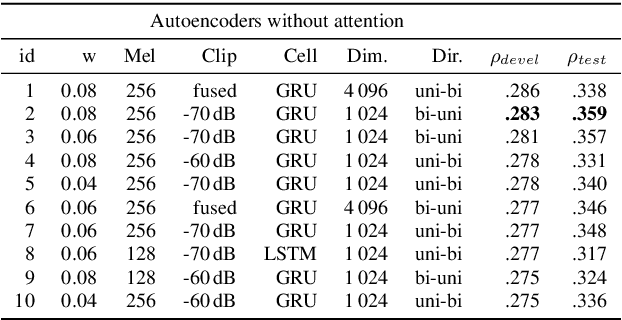
Motivated by the attention mechanism of the human visual system and recent developments in the field of machine translation, we introduce our attention-based and recurrent sequence to sequence autoencoders for fully unsupervised representation learning from audio files. In particular, we test the efficacy of our novel approach on the task of speech-based sleepiness recognition. We evaluate the learnt representations from both autoencoders, and then conduct an early fusion to ascertain possible complementarity between them. In our frameworks, we first extract Mel-spectrograms from raw audio files. Second, we train recurrent autoencoders on these spectrograms which are considered as time-dependent frequency vectors. Afterwards, we extract the activations of specific fully connected layers of the autoencoders which represent the learnt features of spectrograms for the corresponding audio instances. Finally, we train support vector regressors on these representations to obtain the predictions. On the development partition of the data, we achieve Spearman's correlation coefficients of .324, .283, and .320 with the targets on the Karolinska Sleepiness Scale by utilising attention and non-attention autoencoders, and the fusion of both autoencoders' representations, respectively. In the same order, we achieve .311, .359, and .367 Spearman's correlation coefficients on the test data, indicating the suitability of our proposed fusion strategy.