 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothCLAP: Soft-Target Enhanced Contrastive Language\--Audio Pretraining for Affective Computing
Jan 18, 2026The ambiguity of human emotions poses several challenges for machine learning models, as they often overlap and lack clear delineating boundaries. Contrastive language-audio pretraining (CLAP) has emerged as a key technique for generalisable emotion recognition. However, as conventional CLAP enforces a strict one-to-one alignment between paired audio-text samples, it overlooks intra-modal similarity and treats all non-matching pairs as equally negative. This conflicts with the fuzzy boundaries between different emotions. To address this limitation, we propose SmoothCLAP, which introduces softened targets derived from intra-modal similarity and paralinguistic features. By combining these softened targets with conventional contrastive supervision, SmoothCLAP learns embeddings that respect graded emotional relationships, while retaining the same inference pipeline as CLAP. Experiments on eight affective computing tasks across English and German demonstrate that SmoothCLAP is consistently achieving superior performance. Our results highlight that leveraging soft supervision is a promising strategy for building emotion-aware audio-text models.
Affective Computing Has Changed: The Foundation Model Disruption
Sep 13, 2024The dawn of Foundation Models has on the one hand revolutionised a wide range of research problems, and, on the other hand, democratised the access and use of AI-based tools by the general public. We even observe an incursion of these models into disciplines related to human psychology, such as the Affective Computing domain, suggesting their affective, emerging capabilities. In this work, we aim to raise awareness of the power of Foundation Models in the field of Affective Computing by synthetically generating and analysing multimodal affective data, focusing on vision, linguistics, and speech (acoustics). We also discuss some fundamental problems, such as ethical issues and regulatory aspects, related to the use of Foundation Models in this research area.
This Paper Had the Smartest Reviewers -- Flattery Detection Utilising an Audio-Textual Transformer-Based Approach
Jun 25, 2024



Flattery is an important aspect of human communication that facilitates social bonding, shapes perceptions, and influences behavior through strategic compliments and praise, leveraging the power of speech to build rapport effectively. Its automatic detection can thus enhance the naturalness of human-AI interactions. To meet this need, we present a novel audio textual dataset comprising 20 hours of speech and train machine learning models for automatic flattery detection. In particular, we employ pretrained AST, Wav2Vec2, and Whisper models for the speech modality, and Whisper TTS models combined with a RoBERTa text classifier for the textual modality. Subsequently, we build a multimodal classifier by combining text and audio representations. Evaluation on unseen test data demonstrates promising results, with Unweighted Average Recall scores reaching 82.46% in audio-only experiments, 85.97% in text-only experiments, and 87.16% using a multimodal approach.
ExHuBERT: Enhancing HuBERT Through Block Extension and Fine-Tuning on 37 Emotion Datasets
Jun 11, 2024



Foundation models have shown great promise in speech emotion recognition (SER) by leveraging their pre-trained representations to capture emotion patterns in speech signals. To further enhance SER performance across various languages and domains, we propose a novel twofold approach. First, we gather EmoSet++, a comprehensive multi-lingual, multi-cultural speech emotion corpus with 37 datasets, 150,907 samples, and a total duration of 119.5 hours. Second, we introduce ExHuBERT, an enhanced version of HuBERT achieved by backbone extension and fine-tuning on EmoSet++. We duplicate each encoder layer and its weights, then freeze the first duplicate, integrating an extra zero-initialized linear layer and skip connections to preserve functionality and ensure its adaptability for subsequent fine-tuning. Our evaluation on unseen datasets shows the efficacy of ExHuBERT, setting a new benchmark for various SER tasks. Model and details on EmoSet++: https://huggingface.co/amiriparian/ExHuBERT.
The MuSe 2024 Multimodal Sentiment Analysis Challenge: Social Perception and Humor Recognition
Jun 11, 2024



The Multimodal Sentiment Analysis Challenge (MuSe) 2024 addresses two contemporary multimodal affect and sentiment analysis problems: In the Social Perception Sub-Challenge (MuSe-Perception), participants will predict 16 different social attributes of individuals such as assertiveness, dominance, likability, and sincerity based on the provided audio-visual data. The Cross-Cultural Humor Detection Sub-Challenge (MuSe-Humor) dataset expands upon the Passau Spontaneous Football Coach Humor (Passau-SFCH) dataset, focusing on the detection of spontaneous humor in a cross-lingual and cross-cultural setting. The main objective of MuSe 2024 is to unite a broad audience from various research domains, including multimodal sentiment analysis, audio-visual affective computing, continuous signal processing, and natural language processing. By fostering collaboration and exchange among experts in these fields, the MuSe 2024 endeavors to advance the understanding and application of sentiment analysis and affective computing across multiple modalities. This baseline paper provides details on each sub-challenge and its corresponding dataset, extracted features from each data modality, and discusses challenge baselines. For our baseline system, we make use of a range of Transformers and expert-designed features and train Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) models on them, resulting in a competitive baseline system. On the unseen test datasets of the respective sub-challenges, it achieves a mean Pearson's Correlation Coefficient ($\rho$) of 0.3573 for MuSe-Perception and an Area Under the Curve (AUC) value of 0.8682 for MuSe-Humor.
Sustained Vowels for Pre- vs Post-Treatment COPD Classification
Jun 10, 2024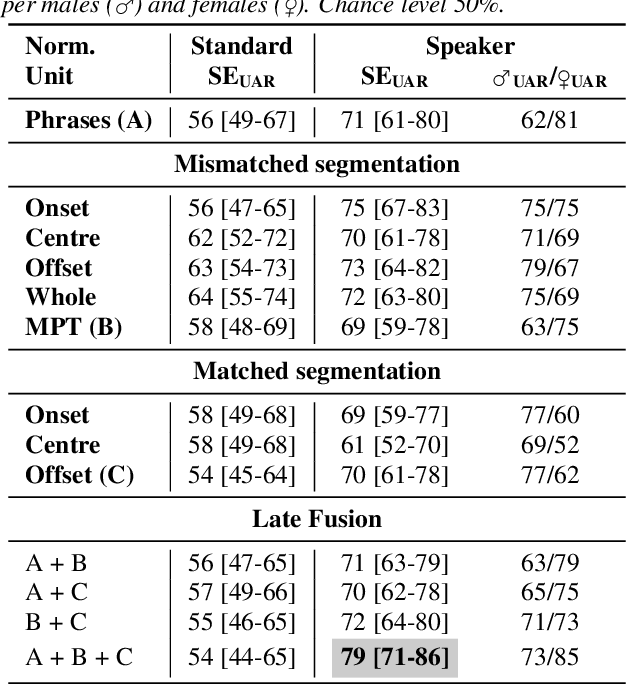
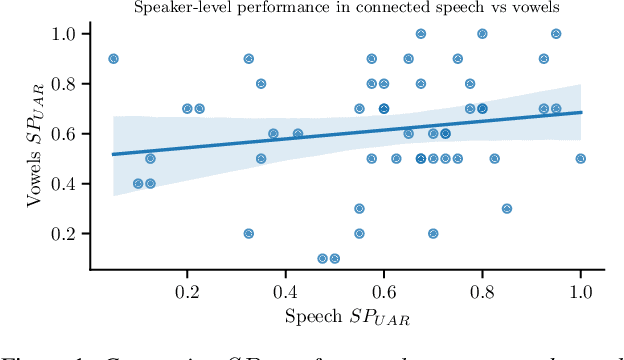
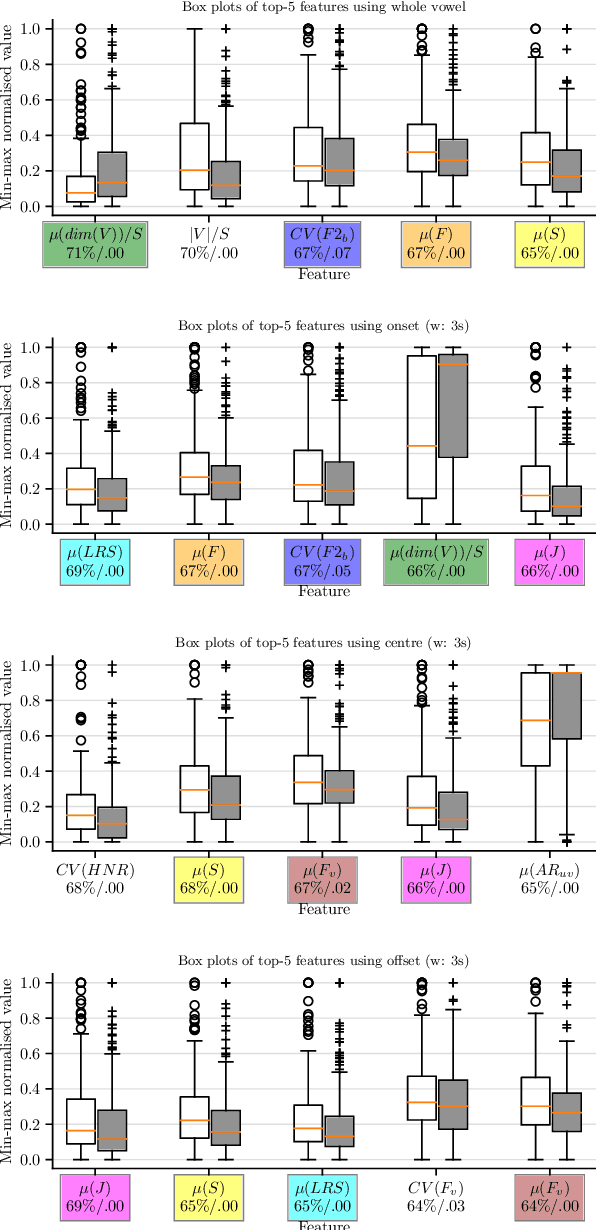
Chronic obstructive pulmonary disease (COPD) is a serious inflammatory lung disease affecting millions of people around the world. Due to an obstructed airflow from the lungs, it also becomes manifest in patients' vocal behaviour. Of particular importance is the detection of an exacerbation episode, which marks an acute phase and often requires hospitalisation and treatment. Previous work has shown that it is possible to distinguish between a pre- and a post-treatment state using automatic analysis of read speech. In this contribution, we examine whether sustained vowels can provide a complementary lens for telling apart these two states. Using a cohort of 50 patients, we show that the inclusion of sustained vowels can improve performance to up to 79\% unweighted average recall, from a 71\% baseline using read speech. We further identify and interpret the most important acoustic features that characterise the manifestation of COPD in sustained vowels.
Modeling Emotional Trajectories in Written Stories Utilizing Transformers and Weakly-Supervised Learning
Jun 04, 2024



Telling stories is an integral part of human communication which can evoke emotions and influence the affective states of the audience. Automatically modeling emotional trajectories in stories has thus attracted considerable scholarly interest. However, as most existing works have been limited to unsupervised dictionary-based approaches, there is no benchmark for this task. We address this gap by introducing continuous valence and arousal labels for an existing dataset of children's stories originally annotated with discrete emotion categories. We collect additional annotations for this data and map the categorical labels to the continuous valence and arousal space. For predicting the thus obtained emotionality signals, we fine-tune a DeBERTa model and improve upon this baseline via a weakly supervised learning approach. The best configuration achieves a Concordance Correlation Coefficient (CCC) of $.8221$ for valence and $.7125$ for arousal on the test set, demonstrating the efficacy of our proposed approach. A detailed analysis shows the extent to which the results vary depending on factors such as the author, the individual story, or the section within the story. In addition, we uncover the weaknesses of our approach by investigating examples that prove to be difficult to predict.
Enhancing Suicide Risk Assessment: A Speech-Based Automated Approach in Emergency Medicine
Apr 18, 2024
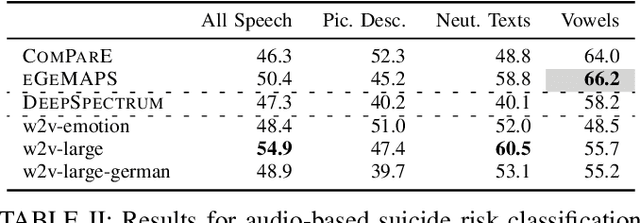
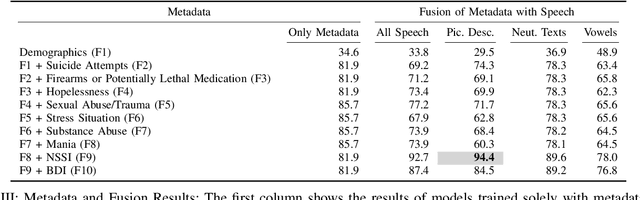
The delayed access to specialized psychiatric assessments and care for patients at risk of suicidal tendencies in emergency departments creates a notable gap in timely intervention, hindering the provision of adequate mental health support during critical situations. To address this, we present a non-invasive, speech-based approach for automatic suicide risk assessment. For our study, we have collected a novel dataset of speech recordings from $20$ patients from which we extract three sets of features, including wav2vec, interpretable speech and acoustic features, and deep learning-based spectral representations. We proceed by conducting a binary classification to assess suicide risk in a leave-one-subject-out fashion. Our most effective speech model achieves a balanced accuracy of $66.2\,\%$. Moreover, we show that integrating our speech model with a series of patients' metadata, such as the history of suicide attempts or access to firearms, improves the overall result. The metadata integration yields a balanced accuracy of $94.4\,\%$, marking an absolute improvement of $28.2\,\%$, demonstrating the efficacy of our proposed approaches for automatic suicide risk assessment in emergency medicine.
Executive Voiced Laughter and Social Approval: An Explorative Machine Learning Study
May 20, 2023

We study voiced laughter in executive communication and its effect on social approval. Integrating research on laughter, affect-as-information, and infomediaries' social evaluations of firms, we hypothesize that voiced laughter in executive communication positively affects social approval, defined as audience perceptions of affinity towards an organization. We surmise that the effect of laughter is especially strong for joint laughter, i.e., the number of instances in a given communication venue for which the focal executive and the audience laugh simultaneously. Finally, combining the notions of affect-as-information and negativity bias in human cognition, we hypothesize that the positive effect of laughter on social approval increases with bad organizational performance. We find partial support for our ideas when testing them on panel data comprising 902 German Bundesliga soccer press conferences and media tenor, applying state-of-the-art machine learning approaches for laughter detection as well as sentiment analysis. Our findings contribute to research at the nexus of executive communication, strategic leadership, and social evaluations, especially by introducing laughter as a highly consequential potential, but understudied social lubricant at the executive-infomediary interface. Our research is unique by focusing on reflexive microprocesses of social evaluations, rather than the infomediary-routines perspectives in infomediaries' evaluations. We also make methodological contributions.
The MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023



The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.