 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MuSe 2024 Multimodal Sentiment Analysis Challenge: Social Perception and Humor Recognition
Jun 11, 2024



The Multimodal Sentiment Analysis Challenge (MuSe) 2024 addresses two contemporary multimodal affect and sentiment analysis problems: In the Social Perception Sub-Challenge (MuSe-Perception), participants will predict 16 different social attributes of individuals such as assertiveness, dominance, likability, and sincerity based on the provided audio-visual data. The Cross-Cultural Humor Detection Sub-Challenge (MuSe-Humor) dataset expands upon the Passau Spontaneous Football Coach Humor (Passau-SFCH) dataset, focusing on the detection of spontaneous humor in a cross-lingual and cross-cultural setting. The main objective of MuSe 2024 is to unite a broad audience from various research domains, including multimodal sentiment analysis, audio-visual affective computing, continuous signal processing, and natural language processing. By fostering collaboration and exchange among experts in these fields, the MuSe 2024 endeavors to advance the understanding and application of sentiment analysis and affective computing across multiple modalities. This baseline paper provides details on each sub-challenge and its corresponding dataset, extracted features from each data modality, and discusses challenge baselines. For our baseline system, we make use of a range of Transformers and expert-designed features and train Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) models on them, resulting in a competitive baseline system. On the unseen test datasets of the respective sub-challenges, it achieves a mean Pearson's Correlation Coefficient ($\rho$) of 0.3573 for MuSe-Perception and an Area Under the Curve (AUC) value of 0.8682 for MuSe-Humor.
The MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023



The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.
Multimodal Prediction of Spontaneous Humour: A Novel Dataset and First Results
Sep 28, 2022
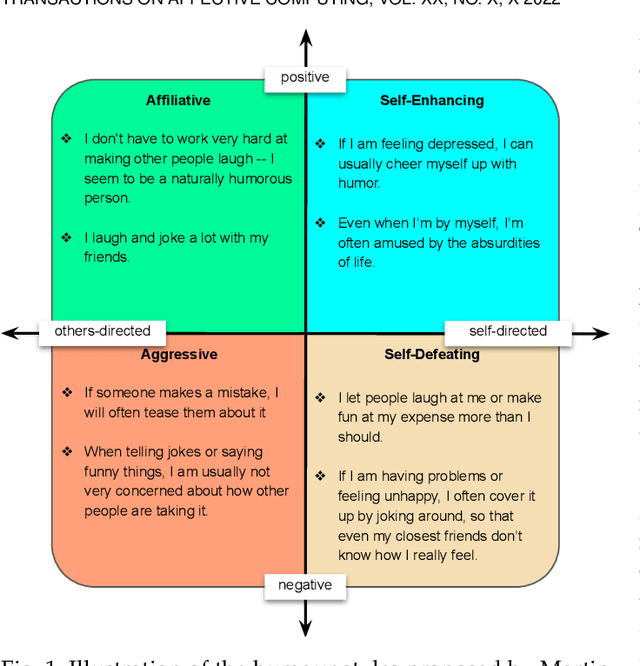
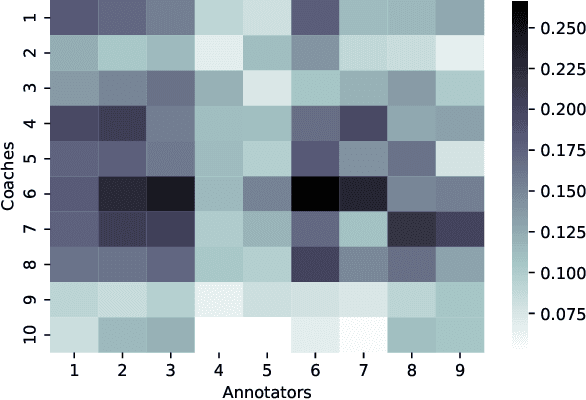

Humour is a substantial element of human affect and cognition. Its automatic understanding can facilitate a more naturalistic human-device interaction and the humanisation of artificial intelligence. Current methods of humour detection are solely based on staged data making them inadequate for 'real-world' applications. We address this deficiency by introducing the novel Passau-Spontaneous Football Coach Humour (Passau-SFCH) dataset, comprising of about 11 hours of recordings. The Passau-SFCH dataset is annotated for the presence of humour and its dimensions (sentiment and direction) as proposed in Martin's Humor Style Questionnaire. We conduct a series of experiments, employing pretrained Transformers, convolutional neural networks, and expert-designed features. The performance of each modality (text, audio, video) for spontaneous humour recognition is analysed and their complementarity is investigated. Our findings suggest that for the automatic analysis of humour and its sentiment, facial expressions are most promising, while humour direction can be best modelled via text-based features. The results reveal considerable differences among various subjects, highlighting the individuality of humour usage and style. Further, we observe that a decision-level fusion yields the best recognition result. Finally, we make our code publicly available at https://www.github.com/EIHW/passau-sfch. The Passau-SFCH dataset is available upon request.