 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent2Agent Threats in Safety-Critical LLM Assistants: A Human-Centric Taxonomy
Feb 05, 2026The integration of Large Language Model (LLM)-based conversational agents into vehicles creates novel security challenges at the intersection of agentic AI, automotive safety, and inter-agent communication. As these intelligent assistants coordinate with external services via protocols such as Google's Agent-to-Agent (A2A), they establish attack surfaces where manipulations can propagate through natural language payloads, potentially causing severe consequences ranging from driver distraction to unauthorized vehicle control. Existing AI security frameworks, while foundational, lack the rigorous "separation of concerns" standard in safety-critical systems engineering by co-mingling the concepts of what is being protected (assets) with how it is attacked (attack paths). This paper addresses this methodological gap by proposing a threat modeling framework called AgentHeLLM (Agent Hazard Exploration for LLM Assistants) that formally separates asset identification from attack path analysis. We introduce a human-centric asset taxonomy derived from harm-oriented "victim modeling" and inspired by the Universal Declaration of Human Rights, and a formal graph-based model that distinguishes poison paths (malicious data propagation) from trigger paths (activation actions). We demonstrate the framework's practical applicability through an open-source attack path suggestion tool AgentHeLLM Attack Path Generator that automates multi-stage threat discovery using a bi-level search strategy.
CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty
Jan 29, 2026Existing benchmarks for Large Language Model (LLM) agents focus on task completion under idealistic settings but overlook reliability in real-world, user-facing applications. In domains, such as in-car voice assistants, users often issue incomplete or ambiguous requests, creating intrinsic uncertainty that agents must manage through dialogue, tool use, and policy adherence. We introduce CAR-bench, a benchmark for evaluating consistency, uncertainty handling, and capability awareness in multi-turn, tool-using LLM agents in an in-car assistant domain. The environment features an LLM-simulated user, domain policies, and 58 interconnected tools spanning navigation, productivity, charging, and vehicle control. Beyond standard task completion, CAR-bench introduces Hallucination tasks that test agents' limit-awareness under missing tools or information, and Disambiguation tasks that require resolving uncertainty through clarification or internal information gathering. Baseline results reveal large gaps between occasional and consistent success on all task types. Even frontier reasoning LLMs achieve less than 50% consistent pass rate on Disambiguation tasks due to premature actions, and frequently violate policies or fabricate information to satisfy user requests in Hallucination tasks, underscoring the need for more reliable and self-aware LLM agents in real-world settings.
CarMem: Enhancing Long-Term Memory in LLM Voice Assistants through Category-Bounding
Jan 16, 2025



In today's assistant landscape, personalisation enhances interactions, fosters long-term relationships, and deepens engagement. However, many systems struggle with retaining user preferences, leading to repetitive user requests and disengagement. Furthermore, the unregulated and opaque extraction of user preferences in industry applications raises significant concerns about privacy and trust, especially in regions with stringent regulations like Europe. In response to these challenges, we propose a long-term memory system for voice assistants, structured around predefined categories. This approach leverages Large Language Models to efficiently extract, store, and retrieve preferences within these categories, ensuring both personalisation and transparency. We also introduce a synthetic multi-turn, multi-session conversation dataset (CarMem), grounded in real industry data, tailored to an in-car voice assistant setting. Benchmarked on the dataset, our system achieves an F1-score of .78 to .95 in preference extraction, depending on category granularity. Our maintenance strategy reduces redundant preferences by 95% and contradictory ones by 92%, while the accuracy of optimal retrieval is at .87. Collectively, the results demonstrate the system's suitability for industrial applications.
The MuSe 2024 Multimodal Sentiment Analysis Challenge: Social Perception and Humor Recognition
Jun 11, 2024



The Multimodal Sentiment Analysis Challenge (MuSe) 2024 addresses two contemporary multimodal affect and sentiment analysis problems: In the Social Perception Sub-Challenge (MuSe-Perception), participants will predict 16 different social attributes of individuals such as assertiveness, dominance, likability, and sincerity based on the provided audio-visual data. The Cross-Cultural Humor Detection Sub-Challenge (MuSe-Humor) dataset expands upon the Passau Spontaneous Football Coach Humor (Passau-SFCH) dataset, focusing on the detection of spontaneous humor in a cross-lingual and cross-cultural setting. The main objective of MuSe 2024 is to unite a broad audience from various research domains, including multimodal sentiment analysis, audio-visual affective computing, continuous signal processing, and natural language processing. By fostering collaboration and exchange among experts in these fields, the MuSe 2024 endeavors to advance the understanding and application of sentiment analysis and affective computing across multiple modalities. This baseline paper provides details on each sub-challenge and its corresponding dataset, extracted features from each data modality, and discusses challenge baselines. For our baseline system, we make use of a range of Transformers and expert-designed features and train Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) models on them, resulting in a competitive baseline system. On the unseen test datasets of the respective sub-challenges, it achieves a mean Pearson's Correlation Coefficient ($\rho$) of 0.3573 for MuSe-Perception and an Area Under the Curve (AUC) value of 0.8682 for MuSe-Humor.
Predicting Sex and Stroke Success -- Computer-aided Player Grunt Analysis in Tennis Matches
Feb 18, 2022


Professional athletes increasingly use automated analysis of meta- and signal data to improve their training and game performance. As in other related human-to-human research fields, signal data, in particular, contain important performance- and mood-specific indicators for automated analysis. In this paper, we introduce the novel data set SCORE! to investigate the performance of several features and machine learning paradigms in the prediction of the sex and immediate stroke success in tennis matches, based only on vocal expression through players' grunts. The data was gathered from YouTube, labelled under the exact same definition, and the audio processed for modelling. We extract several widely used basic, expert-knowledge, and deep acoustic features of the audio samples and evaluate their effectiveness in combination with various machine learning approaches. In a binary setting, the best system, using spectrograms and a Convolutional Recurrent Neural Network, achieves an unweighted average recall (UAR) of 84.0 % for the player sex prediction task, and 60.3 % predicting stroke success, based only on acoustic cues in players' grunts of both sexes. Further, we achieve a UAR of 58.3 %, and 61.3 %, when the models are exclusively trained on female or male grunts, respectively.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022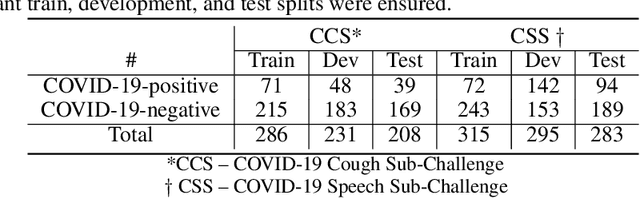
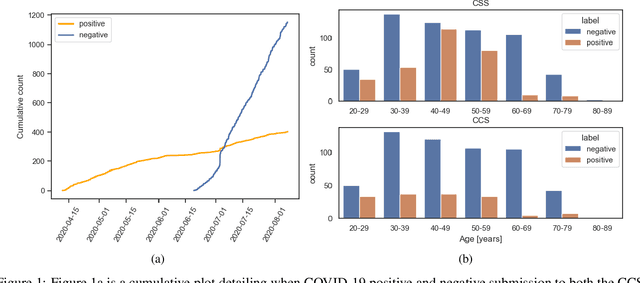
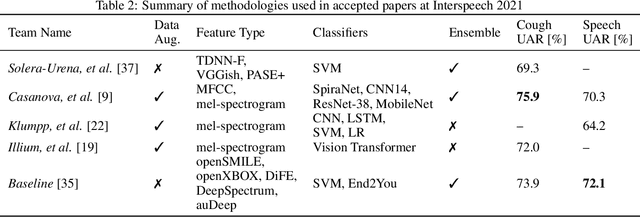
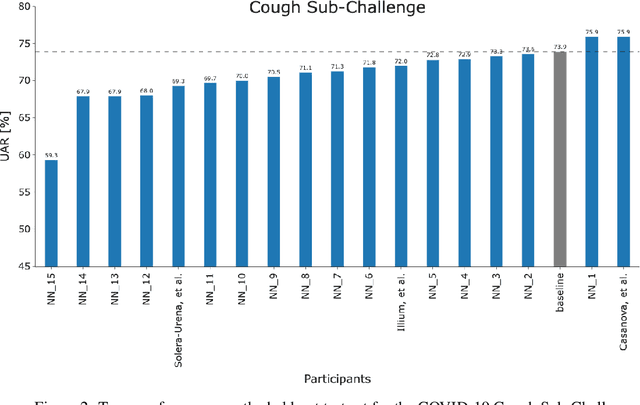
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
A Physiologically-Adapted Gold Standard for Arousal during Stress
Jul 28, 2021
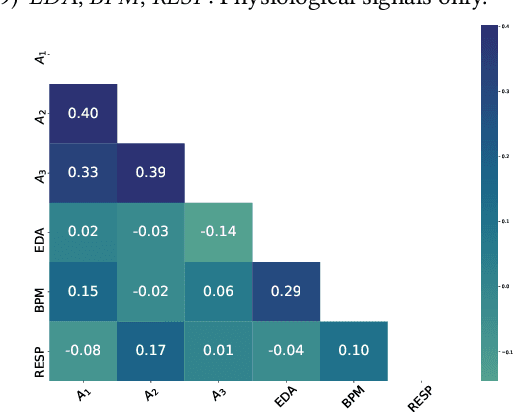
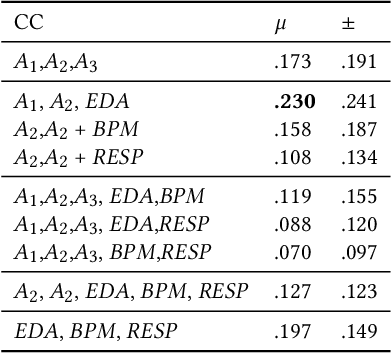
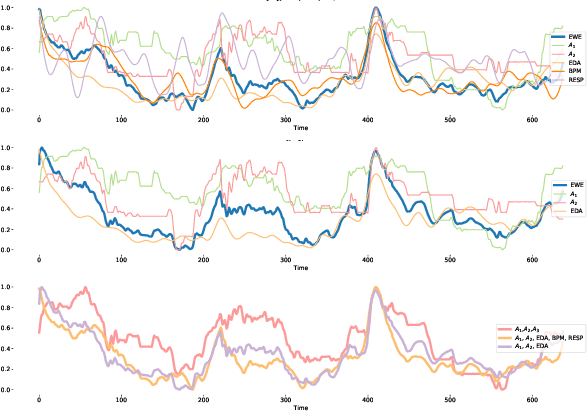
Emotion is an inherently subjective psychophysiological human-state and to produce an agreed-upon representation (gold standard) for continuous emotion requires a time-consuming and costly training procedure of multiple human annotators. There is strong evidence in the literature that physiological signals are sufficient objective markers for states of emotion, particularly arousal. In this contribution, we utilise a dataset which includes continuous emotion and physiological signals - Heartbeats per Minute (BPM), Electrodermal Activity (EDA), and Respiration-rate - captured during a stress inducing scenario (Trier Social Stress Test). We utilise a Long Short-Term Memory, Recurrent Neural Network to explore the benefit of fusing these physiological signals with arousal as the target, learning from various audio, video, and textual based features. We utilise the state-of-the-art MuSe-Toolbox to consider both annotation delay and inter-rater agreement weighting when fusing the target signals. An improvement in Concordance Correlation Coefficient (CCC) is seen across features sets when fusing EDA with arousal, compared to the arousal only gold standard results. Additionally, BERT-based textual features' results improved for arousal plus all physiological signals, obtaining up to .3344 CCC compared to .2118 CCC for arousal only. Multimodal fusion also improves overall CCC with audio plus video features obtaining up to .6157 CCC to recognize arousal plus EDA and BPM.
MuSe-Toolbox: The Multimodal Sentiment Analysis Continuous Annotation Fusion and Discrete Class Transformation Toolbox
Jul 25, 2021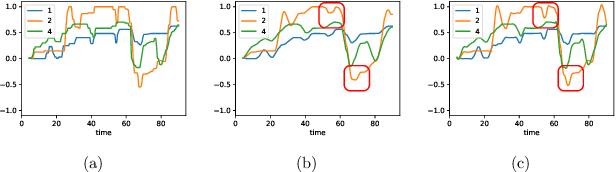
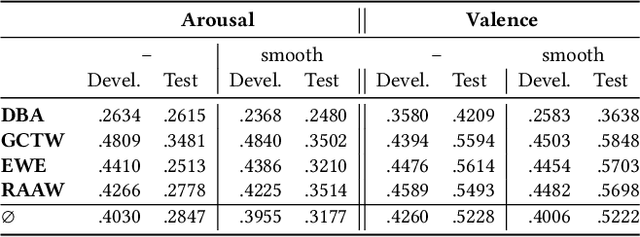


We introduce the MuSe-Toolbox - a Python-based open-source toolkit for creating a variety of continuous and discrete emotion gold standards. In a single framework, we unify a wide range of fusion methods and propose the novel Rater Aligned Annotation Weighting (RAAW), which aligns the annotations in a translation-invariant way before weighting and fusing them based on the inter-rater agreements between the annotations. Furthermore, discrete categories tend to be easier for humans to interpret than continuous signals. With this in mind, the MuSe-Toolbox provides the functionality to run exhaustive searches for meaningful class clusters in the continuous gold standards. To our knowledge, this is the first toolkit that provides a wide selection of state-of-the-art emotional gold standard methods and their transformation to discrete classes. Experimental results indicate that MuSe-Toolbox can provide promising and novel class formations which can be better predicted than hard-coded classes boundaries with minimal human intervention. The implementation (1) is out-of-the-box available with all dependencies using a Docker container (2).
An Estimation of Online Video User Engagement from Features of Continuous Emotions
May 04, 2021

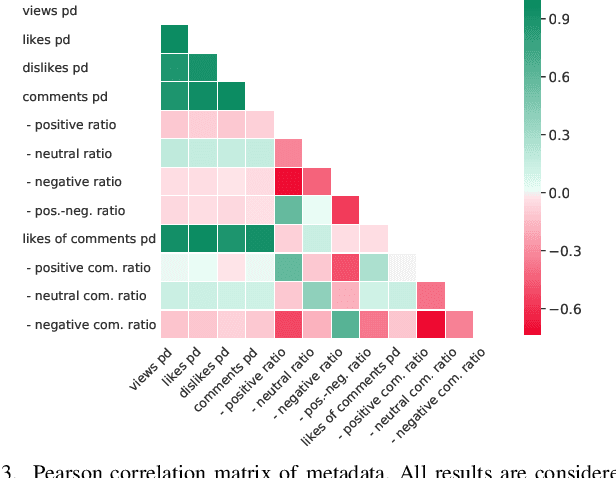
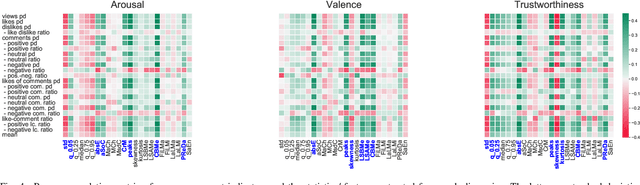
Portraying emotion and trustworthiness is known to increase the appeal of video content. However, the causal relationship between these signals and online user engagement is not well understood. This limited understanding is partly due to a scarcity in emotionally annotated data and the varied modalities which express user engagement online. In this contribution, we utilise a large dataset of YouTube review videos which includes ca. 600 hours of dimensional arousal, valence and trustworthiness annotations. We investigate features extracted from these signals against various user engagement indicators including views, like/dislike ratio, as well as the sentiment of comments. In doing so, we identify the positive and negative influences which single features have, as well as interpretable patterns in each dimension which relate to user engagement. Our results demonstrate that smaller boundary ranges and fluctuations for arousal lead to an increase in user engagement. Furthermore, the extracted time-series features reveal significant (p<0.05) correlations for each dimension, such as, count below signal mean (arousal), number of peaks (valence), and absolute energy (trustworthiness). From this, an effective combination of features is outlined for approaches aiming to automatically predict several user engagement indicators. In a user engagement prediction paradigm we compare all features against semi-automatic (cross-task), and automatic (task-specific) feature selection methods. These selected feature sets appear to outperform the usage of all features, e.g., using all features achieves 1.55 likes per day (Lp/d) mean absolute error from valence; this improves through semi-automatic and automatic selection to 1.33 and 1.23 Lp/d, respectively (data mean 9.72 Lp/d with a std. 28.75 Lp/d).
Unsupervised Graph-based Topic Modeling from Video Transcriptions
May 04, 2021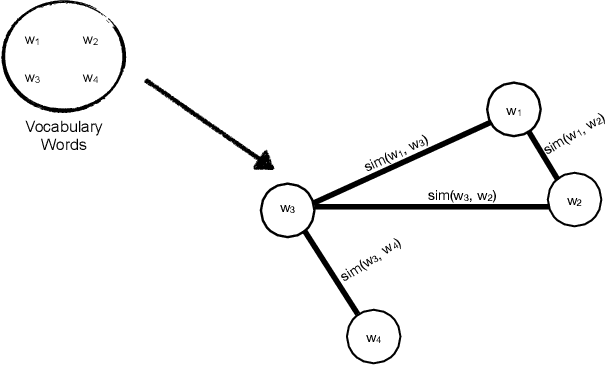



To unfold the tremendous amount of audiovisual data uploaded daily to social media platforms, effective topic modelling techniques are needed. Existing work tends to apply variants of topic models on text data sets. In this paper, we aim at developing a topic extractor on video transcriptions. The model improves coherence by exploiting neural word embeddings through a graph-based clustering method. Unlike typical topic models, this approach works without knowing the true number of topics. Experimental results on the real-life multimodal data set MuSe-CaR demonstrates that our approach extracts coherent and meaningful topics, outperforming baseline methods. Furthermore, we successfully demonstrate the generalisability of our approach on a pure text review data set.