 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty
Jan 29, 2026Existing benchmarks for Large Language Model (LLM) agents focus on task completion under idealistic settings but overlook reliability in real-world, user-facing applications. In domains, such as in-car voice assistants, users often issue incomplete or ambiguous requests, creating intrinsic uncertainty that agents must manage through dialogue, tool use, and policy adherence. We introduce CAR-bench, a benchmark for evaluating consistency, uncertainty handling, and capability awareness in multi-turn, tool-using LLM agents in an in-car assistant domain. The environment features an LLM-simulated user, domain policies, and 58 interconnected tools spanning navigation, productivity, charging, and vehicle control. Beyond standard task completion, CAR-bench introduces Hallucination tasks that test agents' limit-awareness under missing tools or information, and Disambiguation tasks that require resolving uncertainty through clarification or internal information gathering. Baseline results reveal large gaps between occasional and consistent success on all task types. Even frontier reasoning LLMs achieve less than 50% consistent pass rate on Disambiguation tasks due to premature actions, and frequently violate policies or fabricate information to satisfy user requests in Hallucination tasks, underscoring the need for more reliable and self-aware LLM agents in real-world settings.
CarMem: Enhancing Long-Term Memory in LLM Voice Assistants through Category-Bounding
Jan 16, 2025



In today's assistant landscape, personalisation enhances interactions, fosters long-term relationships, and deepens engagement. However, many systems struggle with retaining user preferences, leading to repetitive user requests and disengagement. Furthermore, the unregulated and opaque extraction of user preferences in industry applications raises significant concerns about privacy and trust, especially in regions with stringent regulations like Europe. In response to these challenges, we propose a long-term memory system for voice assistants, structured around predefined categories. This approach leverages Large Language Models to efficiently extract, store, and retrieve preferences within these categories, ensuring both personalisation and transparency. We also introduce a synthetic multi-turn, multi-session conversation dataset (CarMem), grounded in real industry data, tailored to an in-car voice assistant setting. Benchmarked on the dataset, our system achieves an F1-score of .78 to .95 in preference extraction, depending on category granularity. Our maintenance strategy reduces redundant preferences by 95% and contradictory ones by 92%, while the accuracy of optimal retrieval is at .87. Collectively, the results demonstrate the system's suitability for industrial applications.
Learning the Koopman Eigendecomposition: A Diffeomorphic Approach
Oct 15, 2021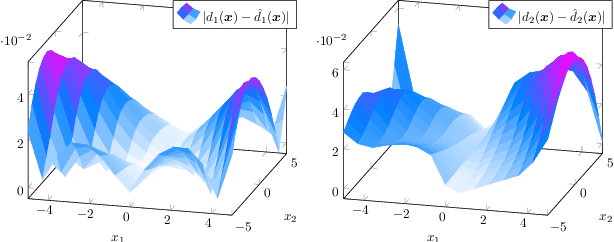
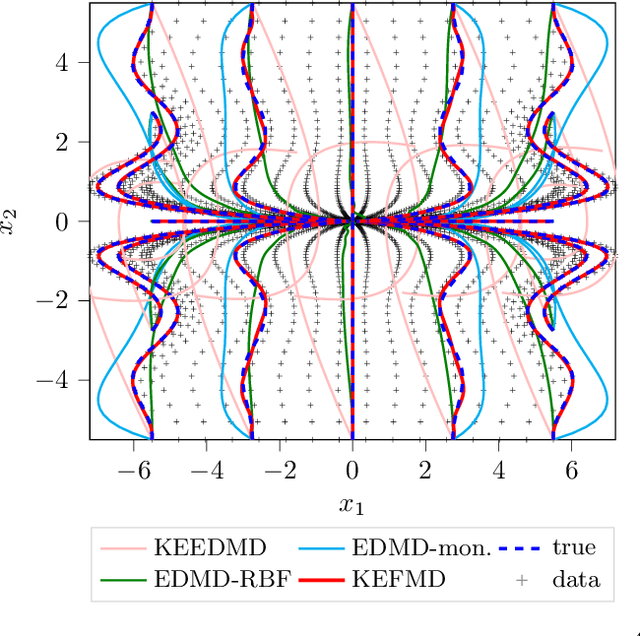

We present a novel data-driven approach for learning linear representations of a class of stable nonlinear systems using Koopman eigenfunctions. By learning the conjugacy map between a nonlinear system and its Jacobian linearization through a Normalizing Flow one can guarantee the learned function is a diffeomorphism. Using this diffeomorphism, we construct eigenfunctions of the nonlinear system via the spectral equivalence of conjugate systems - allowing the construction of linear predictors for nonlinear systems. The universality of the diffeomorphism learner leads to the universal approximation of the nonlinear system's Koopman eigenfunctions. The developed method is also safe as it guarantees the model is asymptotically stable regardless of the representation accuracy. To our best knowledge, this is the first work to close the gap between the operator, system and learning theories. The efficacy of our approach is shown through simulation examples.