 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics from Infrequent Output Measurements for Uncertainty-Aware Optimal Control
Dec 08, 2025Reliable optimal control is challenging when the dynamics of a nonlinear system are unknown and only infrequent, noisy output measurements are available. This work addresses this setting of limited sensing by formulating a Bayesian prior over the continuous-time dynamics and latent state trajectory in state-space form and updating it through a targeted marginal Metropolis-Hastings sampler equipped with a numerical ODE integrator. The resulting posterior samples are used to formulate a scenario-based optimal control problem that accounts for both model and measurement uncertainty and is solved using standard nonlinear programming methods. The approach is validated in a numerical case study on glucose regulation using a Type 1 diabetes model.
Operator Models for Continuous-Time Offline Reinforcement Learning
Nov 13, 2025Continuous-time stochastic processes underlie many natural and engineered systems. In healthcare, autonomous driving, and industrial control, direct interaction with the environment is often unsafe or impractical, motivating offline reinforcement learning from historical data. However, there is limited statistical understanding of the approximation errors inherent in learning policies from offline datasets. We address this by linking reinforcement learning to the Hamilton-Jacobi-Bellman equation and proposing an operator-theoretic algorithm based on a simple dynamic programming recursion. Specifically, we represent our world model in terms of the infinitesimal generator of controlled diffusion processes learned in a reproducing kernel Hilbert space. By integrating statistical learning methods and operator theory, we establish global convergence of the value function and derive finite-sample guarantees with bounds tied to system properties such as smoothness and stability. Our theoretical and numerical results indicate that operator-based approaches may hold promise in solving offline reinforcement learning using continuous-time optimal control.
SAD-Flower: Flow Matching for Safe, Admissible, and Dynamically Consistent Planning
Nov 07, 2025Flow matching (FM) has shown promising results in data-driven planning. However, it inherently lacks formal guarantees for ensuring state and action constraints, whose satisfaction is a fundamental and crucial requirement for the safety and admissibility of planned trajectories on various systems. Moreover, existing FM planners do not ensure the dynamical consistency, which potentially renders trajectories inexecutable. We address these shortcomings by proposing SAD-Flower, a novel framework for generating Safe, Admissible, and Dynamically consistent trajectories. Our approach relies on an augmentation of the flow with a virtual control input. Thereby, principled guidance can be derived using techniques from nonlinear control theory, providing formal guarantees for state constraints, action constraints, and dynamic consistency. Crucially, SAD-Flower operates without retraining, enabling test-time satisfaction of unseen constraints. Through extensive experiments across several tasks, we demonstrate that SAD-Flower outperforms various generative-model-based baselines in ensuring constraint satisfaction.
Learning Safe Control via On-the-Fly Bandit Exploration
Jun 12, 2025Control tasks with safety requirements under high levels of model uncertainty are increasingly common. Machine learning techniques are frequently used to address such tasks, typically by leveraging model error bounds to specify robust constraint-based safety filters. However, if the learned model uncertainty is very high, the corresponding filters are potentially invalid, meaning no control input satisfies the constraints imposed by the safety filter. While most works address this issue by assuming some form of safe backup controller, ours tackles it by collecting additional data on the fly using a Gaussian process bandit-type algorithm. We combine a control barrier function with a learned model to specify a robust certificate that ensures safety if feasible. Whenever infeasibility occurs, we leverage the control barrier function to guide exploration, ensuring the collected data contributes toward the closed-loop system safety. By combining a safety filter with exploration in this manner, our method provably achieves safety in a setting that allows for a zero-mean prior dynamics model, without requiring a backup controller. To the best of our knowledge, it is the first safe learning-based control method that achieves this.
Learning Geometrically-Informed Lyapunov Functions with Deep Diffeomorphic RBF Networks
Apr 03, 2025The practical deployment of learning-based autonomous systems would greatly benefit from tools that flexibly obtain safety guarantees in the form of certificate functions from data. While the geometrical properties of such certificate functions are well understood, synthesizing them using machine learning techniques still remains a challenge. To mitigate this issue, we propose a diffeomorphic function learning framework where prior structural knowledge of the desired output is encoded in the geometry of a simple surrogate function, which is subsequently augmented through an expressive, topology-preserving state-space transformation. Thereby, we achieve an indirect function approximation framework that is guaranteed to remain in the desired hypothesis space. To this end, we introduce a novel approach to construct diffeomorphic maps based on RBF networks, which facilitate precise, local transformations around data. Finally, we demonstrate our approach by learning diffeomorphic Lyapunov functions from real-world data and apply our method to different attractor systems.
Barrier Certificates for Unknown Systems with Latent States and Polynomial Dynamics using Bayesian Inference
Apr 02, 2025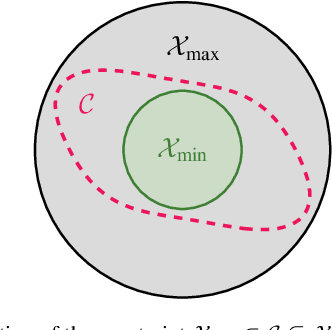



Certifying safety in dynamical systems is crucial, but barrier certificates - widely used to verify that system trajectories remain within a safe region - typically require explicit system models. When dynamics are unknown, data-driven methods can be used instead, yet obtaining a valid certificate requires rigorous uncertainty quantification. For this purpose, existing methods usually rely on full-state measurements, limiting their applicability. This paper proposes a novel approach for synthesizing barrier certificates for unknown systems with latent states and polynomial dynamics. A Bayesian framework is employed, where a prior in state-space representation is updated using input-output data via a targeted marginal Metropolis-Hastings sampler. The resulting samples are used to construct a candidate barrier certificate through a sum-of-squares program. It is shown that if the candidate satisfies the required conditions on a test set of additional samples, it is also valid for the true, unknown system with high probability. The approach and its probabilistic guarantees are illustrated through a numerical simulation.
Koopman-Equivariant Gaussian Processes
Feb 10, 2025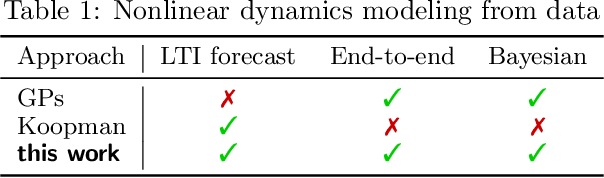

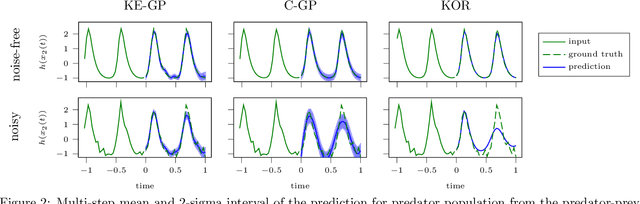
Credible forecasting and representation learning of dynamical systems are of ever-increasing importance for reliable decision-making. To that end, we propose a family of Gaussian processes (GP) for dynamical systems with linear time-invariant responses, which are nonlinear only in initial conditions. This linearity allows us to tractably quantify forecasting and representational uncertainty, simultaneously alleviating the challenge of computing the distribution of trajectories from a GP-based dynamical system and enabling a new probabilistic treatment of learning Koopman operator representations. Using a trajectory-based equivariance -- which we refer to as \textit{Koopman equivariance} -- we obtain a GP model with enhanced generalization capabilities. To allow for large-scale regression, we equip our framework with variational inference based on suitable inducing points. Experiments demonstrate on-par and often better forecasting performance compared to kernel-based methods for learning dynamical systems.
Asynchronous Distributed Gaussian Process Regression for Online Learning and Dynamical Systems: Complementary Document
Dec 16, 2024



This is a complementary document for the paper titled "Asynchronous Distributed Gaussian Process Regression for Online Learning and Dynamical Systems".
Kernel-Based Optimal Control: An Infinitesimal Generator Approach
Dec 02, 2024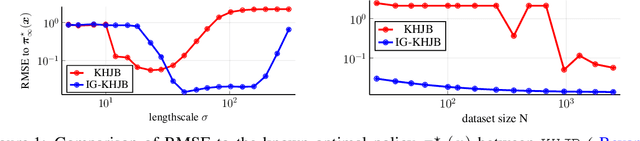

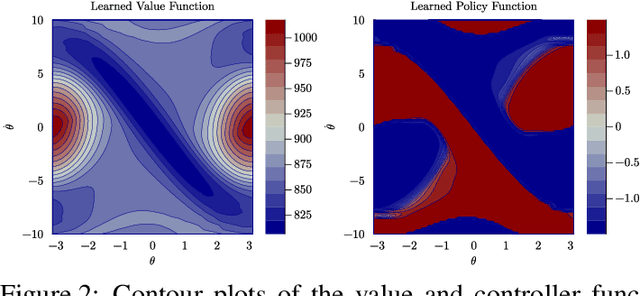
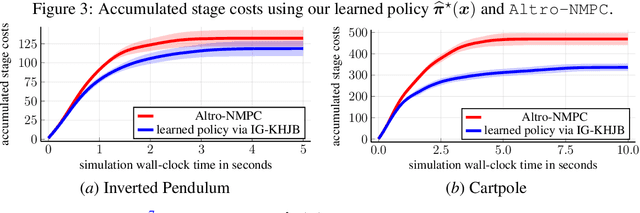
This paper presents a novel approach for optimal control of nonlinear stochastic systems using infinitesimal generator learning within infinite-dimensional reproducing kernel Hilbert spaces. Our learning framework leverages data samples of system dynamics and stage cost functions, with only control penalties and constraints provided. The proposed method directly learns the diffusion operator of a controlled Fokker-Planck-Kolmogorov equation in an infinite-dimensional hypothesis space. This operator models the continuous-time evolution of the probability measure of the control system's state. We demonstrate that this approach seamlessly integrates with modern convex operator-theoretic Hamilton-Jacobi-Bellman recursions, enabling a data-driven solution to the optimal control problem. Furthermore, our statistical learning framework includes nonparametric estimators for uncontrolled forward infinitesimal generators as a special case. Numerical experiments, ranging from synthetic differential equations to simulated robotic systems, showcase the advantages of our approach compared to both modern data-driven and classical nonlinear programming methods for optimal control.
Risk-averse learning with delayed feedback
Sep 25, 2024



In real-world scenarios, the impacts of decisions may not manifest immediately. Taking these delays into account facilitates accurate assessment and management of risk in real-world environments, thereby ensuring the efficacy of strategies. In this paper, we investigate risk-averse learning using Conditional Value at Risk (CVaR) as risk measure, while incorporating delayed feedback with unknown but bounded delays. We develop two risk-averse learning algorithms that rely on one-point and two-point zeroth-order optimization approaches, respectively. The regret achieved by the algorithms is analyzed in terms of the cumulative delay and the number of total samplings. The results suggest that the two-point risk-averse learning achieves a smaller regret bound than the one-point algorithm. Furthermore, the one-point risk-averse learning algorithm attains sublinear regret under certain delay conditions, and the two-point risk-averse learning algorithm achieves sublinear regret with minimal restrictions on the delay. We provide numerical experiments on a dynamic pricing problem to demonstrate the performance of the proposed algorithms.