 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Geometrically-Informed Lyapunov Functions with Deep Diffeomorphic RBF Networks
Apr 03, 2025The practical deployment of learning-based autonomous systems would greatly benefit from tools that flexibly obtain safety guarantees in the form of certificate functions from data. While the geometrical properties of such certificate functions are well understood, synthesizing them using machine learning techniques still remains a challenge. To mitigate this issue, we propose a diffeomorphic function learning framework where prior structural knowledge of the desired output is encoded in the geometry of a simple surrogate function, which is subsequently augmented through an expressive, topology-preserving state-space transformation. Thereby, we achieve an indirect function approximation framework that is guaranteed to remain in the desired hypothesis space. To this end, we introduce a novel approach to construct diffeomorphic maps based on RBF networks, which facilitate precise, local transformations around data. Finally, we demonstrate our approach by learning diffeomorphic Lyapunov functions from real-world data and apply our method to different attractor systems.
Stable Inverse Reinforcement Learning: Policies from Control Lyapunov Landscapes
May 14, 2024



Learning from expert demonstrations to flexibly program an autonomous system with complex behaviors or to predict an agent's behavior is a powerful tool, especially in collaborative control settings. A common method to solve this problem is inverse reinforcement learning (IRL), where the observed agent, e.g., a human demonstrator, is assumed to behave according to the optimization of an intrinsic cost function that reflects its intent and informs its control actions. While the framework is expressive, it is also computationally demanding and generally lacks convergence guarantees. We therefore propose a novel, stability-certified IRL approach by reformulating the cost function inference problem to learning control Lyapunov functions (CLF) from demonstrations data. By additionally exploiting closed-form expressions for associated control policies, we are able to efficiently search the space of CLFs by observing the attractor landscape of the induced dynamics. For the construction of the inverse optimal CLFs, we use a Sum of Squares and formulate a convex optimization problem. We present a theoretical analysis of the optimality properties provided by the CLF and evaluate our approach using both simulated and real-world data.
Data-driven Force Observer for Human-Robot Interaction with Series Elastic Actuators using Gaussian Processes
May 14, 2024Ensuring safety and adapting to the user's behavior are of paramount importance in physical human-robot interaction. Thus, incorporating elastic actuators in the robot's mechanical design has become popular, since it offers intrinsic compliance and additionally provide a coarse estimate for the interaction force by measuring the deformation of the elastic components. While observer-based methods have been shown to improve these estimates, they rely on accurate models of the system, which are challenging to obtain in complex operating environments. In this work, we overcome this issue by learning the unknown dynamics components using Gaussian process (GP) regression. By employing the learned model in a Bayesian filtering framework, we improve the estimation accuracy and additionally obtain an observer that explicitly considers local model uncertainty in the confidence measure of the state estimate. Furthermore, we derive guaranteed estimation error bounds, thus, facilitating the use in safety-critical applications. We demonstrate the effectiveness of the proposed approach experimentally in a human-exoskeleton interaction scenario.
Uncertainty-Aware Visual Perception for Safe Motion Planning
Sep 14, 2022
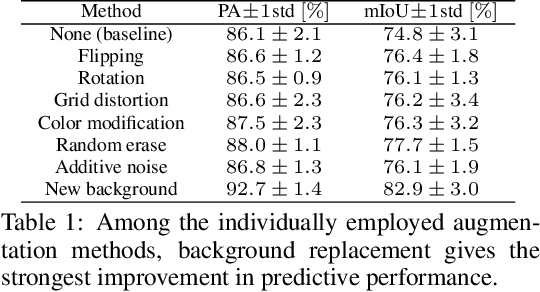
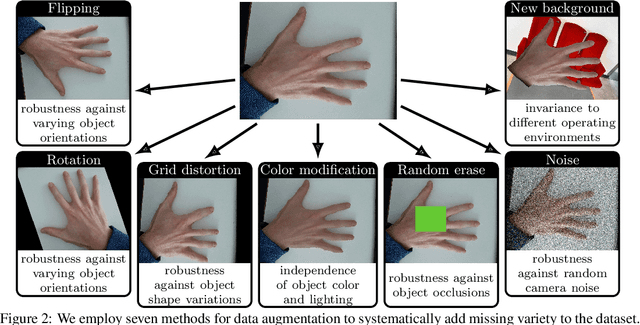
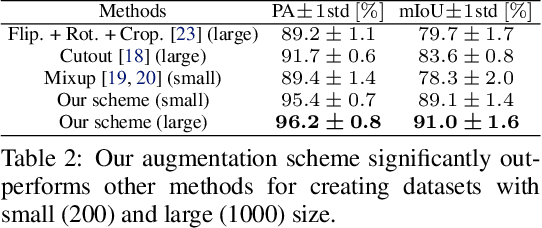
For safe operation, a robot must be able to avoid collisions in uncertain environments. Existing approaches for motion planning with uncertainties often make conservative assumptions about Gaussianity and the obstacle geometry. While visual perception can deliver a more accurate representation of the environment, its use for safe motion planning is limited by the inherent miscalibration of neural networks and the challenge of obtaining adequate datasets. In order to address these imitations, we propose to employ ensembles of deep semantic segmentation networks trained with systematically augmented datasets to ensure reliable probabilistic occupancy information. For avoiding conservatism during motion planning, we directly employ the probabilistic perception via a scenario-based path planning approach. A velocity scheduling scheme is applied to the path to ensure a safe motion despite tracking inaccuracies. We demonstrate the effectiveness of the systematic data augmentation in combination with deep ensembles and the proposed scenario-based planning approach in comparisons to state-of-the-art methods and validate our framework in an experiment involving a human hand.
Networked Online Learning for Control of Safety-Critical Resource-Constrained Systems based on Gaussian Processes
Feb 23, 2022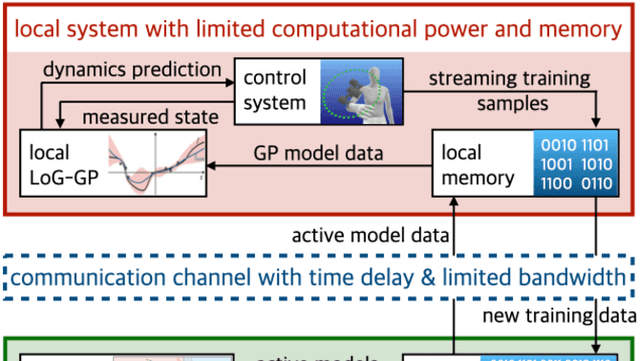


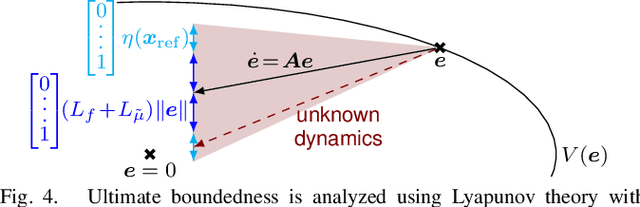
Safety-critical technical systems operating in unknown environments require the ability to quickly adapt their behavior, which can be achieved in control by inferring a model online from the data stream generated during operation. Gaussian process-based learning is particularly well suited for safety-critical applications as it ensures bounded prediction errors. While there exist computationally efficient approximations for online inference, these approaches lack guarantees for the prediction error and have high memory requirements, and are therefore not applicable to safety-critical systems with tight memory constraints. In this work, we propose a novel networked online learning approach based on Gaussian process regression, which addresses the issue of limited local resources by employing remote data management in the cloud. Our approach formally guarantees a bounded tracking error with high probability, which is exploited to identify the most relevant data to achieve a certain control performance. We further propose an effective data transmission scheme between the local system and the cloud taking bandwidth limitations and time delay of the transmission channel into account. The effectiveness of the proposed method is successfully demonstrated in a simulation.
Personalized Rehabilitation Robotics based on Online Learning Control
Oct 01, 2021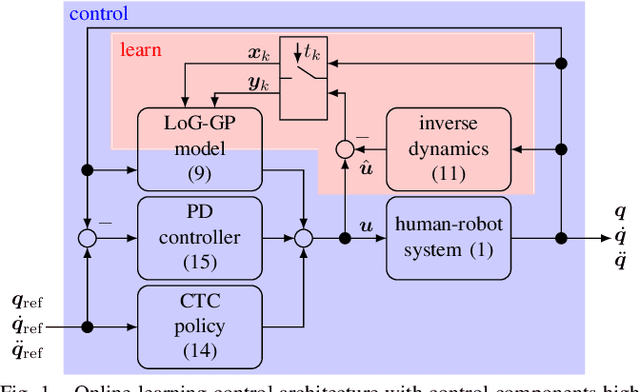

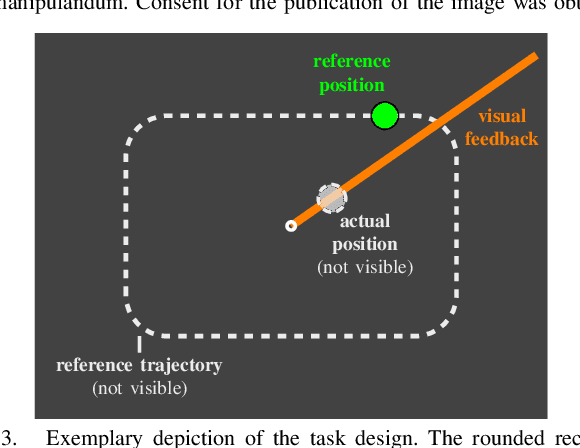
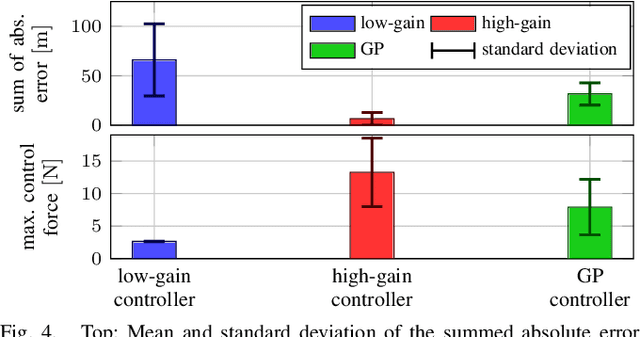
The use of rehabilitation robotics in clinical applications gains increasing importance, due to therapeutic benefits and the ability to alleviate labor-intensive works. However, their practical utility is dependent on the deployment of appropriate control algorithms, which adapt the level of task-assistance according to each individual patient's need. Generally, the required personalization is achieved through manual tuning by clinicians, which is cumbersome and error-prone. In this work we propose a novel online learning control architecture, which is able to personalize the control force at run time to each individual user. To this end, we deploy Gaussian process-based online learning with previously unseen prediction and update rates. Finally, we evaluate our method in an experimental user study, where the learning controller is shown to provide personalized control, while also obtaining safe interaction forces.
Inverse Reinforcement Learning a Control Lyapunov Approach
Apr 09, 2021

Inferring the intent of an intelligent agent from demonstrations and subsequently predicting its behavior, is a critical task in many collaborative settings. A common approach to solve this problem is the framework of inverse reinforcement learning (IRL), where the observed agent, e.g., a human demonstrator, is assumed to behave according to an intrinsic cost function that reflects its intent and informs its control actions. In this work, we reformulate the IRL inference problem to learning control Lyapunov functions (CLF) from demonstrations by exploiting the inverse optimality property, which states that every CLF is also a meaningful value function. Moreover, the derived CLF formulation directly guarantees stability of inferred control policies. We show the flexibility of our proposed method by learning from goal-directed movement demonstrations in a continuous environment.
Deep Decentralized Reinforcement Learning for Cooperative Control
Oct 29, 2019


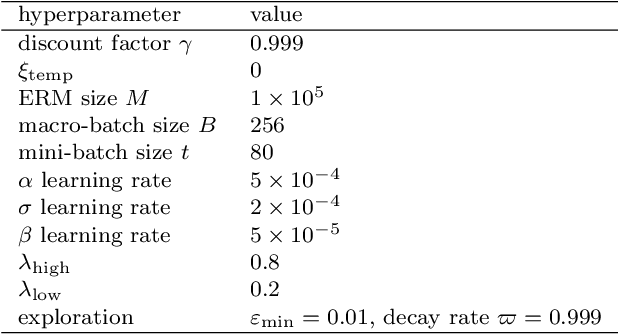
In order to collaborate efficiently with unknown partners in cooperative control settings, adaptation of the partners based on online experience is required. The rather general and widely applicable control setting, where each cooperation partner might strive for individual goals while the control laws and objectives of the partners are unknown, entails various challenges such as the non-stationarity of the environment, the multi-agent credit assignment problem, the alter-exploration problem and the coordination problem. We propose new, modular deep decentralized Multi-Agent Reinforcement Learning mechanisms to account for these challenges. Therefore, our method uses a time-dependent prioritization of samples, incorporates a model of the system dynamics and utilizes variable, accountability-driven learning rates and simulated, artificial experiences in order to guide the learning process. The effectiveness of our method is demonstrated by means of a simulated, nonlinear cooperative control task.