 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Decentralized Reinforcement Learning for Cooperative Control
Oct 29, 2019


In order to collaborate efficiently with unknown partners in cooperative control settings, adaptation of the partners based on online experience is required. The rather general and widely applicable control setting, where each cooperation partner might strive for individual goals while the control laws and objectives of the partners are unknown, entails various challenges such as the non-stationarity of the environment, the multi-agent credit assignment problem, the alter-exploration problem and the coordination problem. We propose new, modular deep decentralized Multi-Agent Reinforcement Learning mechanisms to account for these challenges. Therefore, our method uses a time-dependent prioritization of samples, incorporates a model of the system dynamics and utilizes variable, accountability-driven learning rates and simulated, artificial experiences in order to guide the learning process. The effectiveness of our method is demonstrated by means of a simulated, nonlinear cooperative control task.
Adaptive Dynamic Programming for Model-free Tracking of Trajectories with Time-varying Parameters
Oct 28, 2019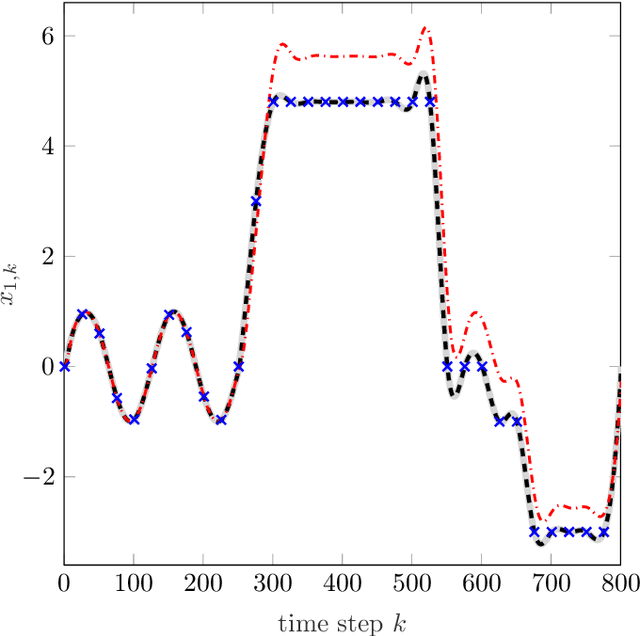
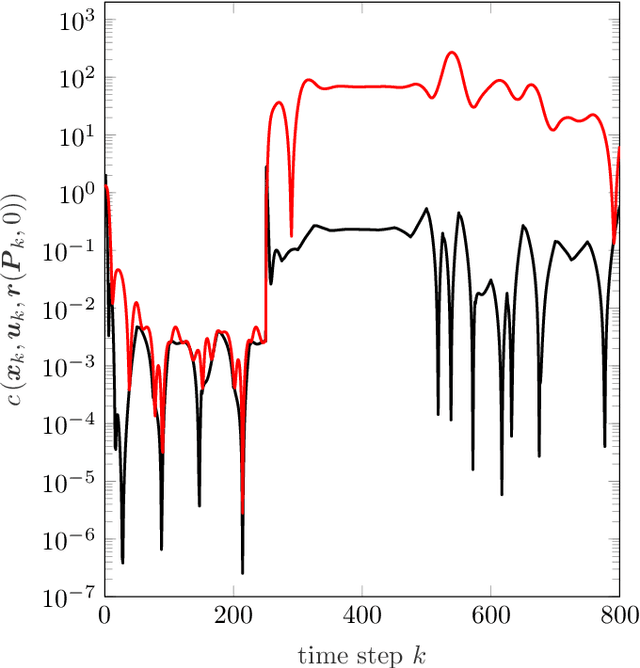
In order to autonomously learn to control unknown systems optimally w.r.t. an objective function, Adaptive Dynamic Programming (ADP) is well-suited to adapt controllers based on experience from interaction with the system. In recent years, many researchers focused on the tracking case, where the aim is to follow a desired trajectory. So far, ADP tracking controllers assume that the reference trajectory follows time-invariant exo-system dynamics-an assumption that does not hold for many applications. In order to overcome this limitation, we propose a new Q-function which explicitly incorporates a parametrized approximation of the reference trajectory. This allows to learn to track a general class of trajectories by means of ADP. Once our Q-function has been learned, the associated controller copes with time-varying reference trajectories without need of further training and independent of exo-system dynamics. After proposing our general model-free off-policy tracking method, we provide analysis of the important special case of linear quadratic tracking. We conclude our paper with an example which demonstrates that our new method successfully learns the optimal tracking controller and outperforms existing approaches in terms of tracking error and cost.
Partner Approximating Learners (PAL): Simulation-Accelerated Learning with Explicit Partner Modeling in Multi-Agent Domains
Sep 10, 2019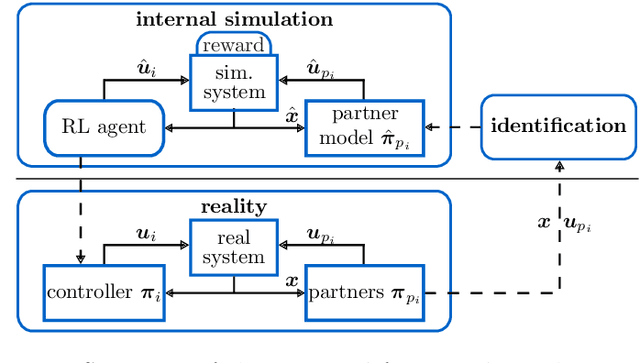

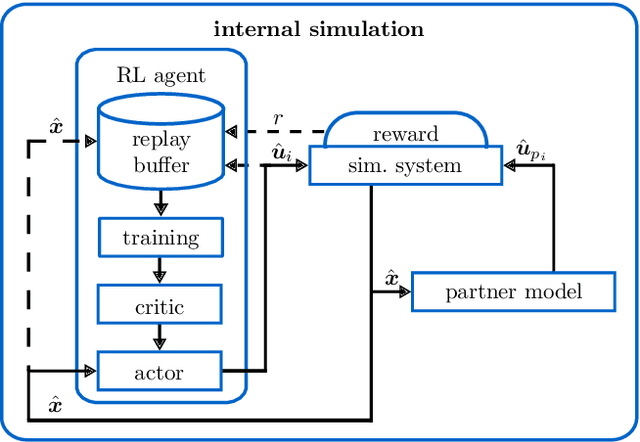
Mixed cooperative-competitive control scenarios such as human-machine interaction with individual goals of the interacting partners are very challenging for reinforcement learning agents. In order to contribute towards intuitive human-machine collaboration, we focus on problems in the continuous state and control domain where no explicit communication is considered and the agents do not know the others' goals or control laws but only sense their control inputs retrospectively. Our proposed framework combines a learned partner model based on online data with a reinforcement learning agent that is trained in a simulated environment including the partner model. Thus, we overcome drawbacks of independent learners and, in addition, benefit from a reduced amount of real world data required for reinforcement learning which is vital in the human-machine context. We finally analyze an example that demonstrates the merits of our proposed framework which learns fast due to the simulated environment and adapts to the continuously changing partner due to the partner approximation.
Adaptive Optimal Control for Reference Tracking Independent of Exo-System Dynamics
Jul 24, 2019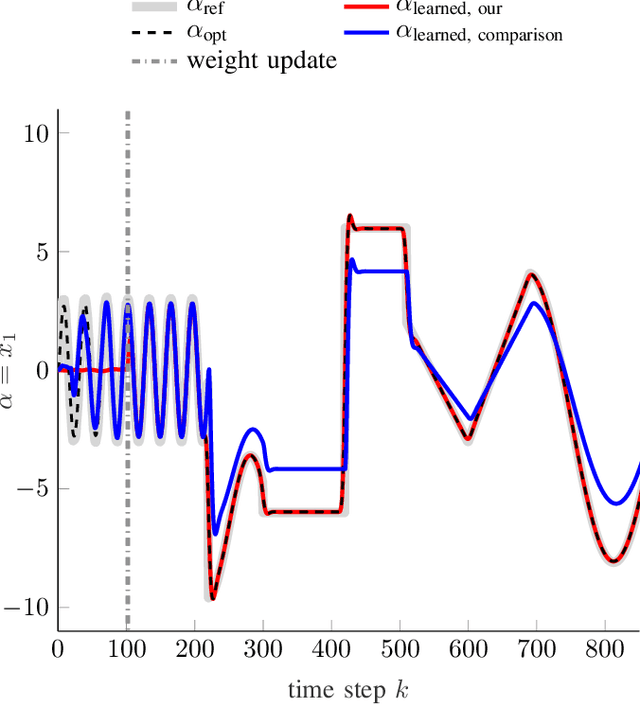

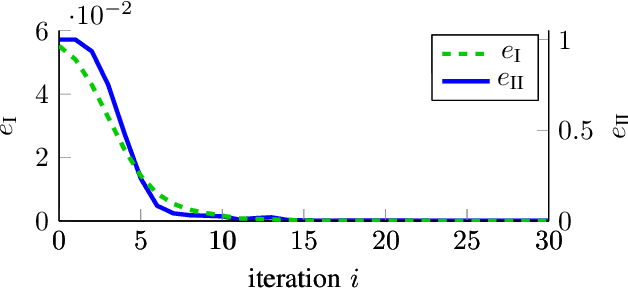
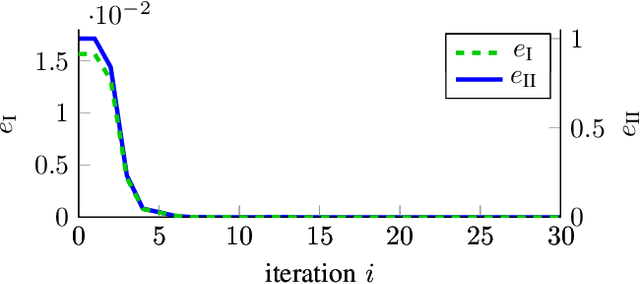
Model-free control based on the idea of Reinforcement Learning is a promising approach that has recently gained extensive attention. However, Reinforcement-Learning-based control methods solely focus on the regulation problem or learn to track a reference that is generated by a time-invariant exo-system. In the latter case, controllers are only able to track the time-invariant reference dynamics which they have been trained on and need to be re-trained each time the reference dynamics change. Consequently, these methods fail in a number of applications which obviously rely on a trajectory not being generated by an exo-system. One prominent example is autonomous driving. This paper provides for the first time an adaptive optimal control method capable to track reference trajectories not being generated by an exo-system. The main innovation is a novel Q-function that directly incorporates a given reference trajectory on a moving horizon. This new Q-function exhibits a particular structure which allows the design of an efficient, iterative, provably convergent Reinforcement Learning algorithm that enables optimal tracking. Two real-world examples demonstrate by simulation that our new method outperforms existing approaches in terms of tracking error.