 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dynamic Programming for Model-free Tracking of Trajectories with Time-varying Parameters
Oct 28, 2019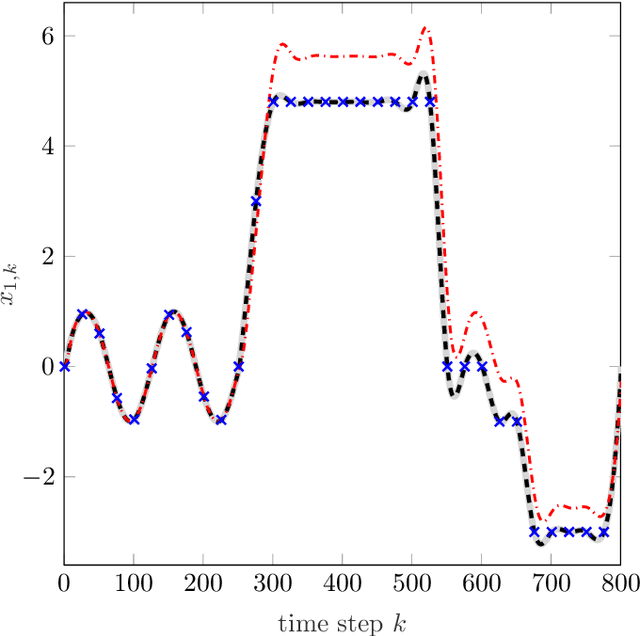
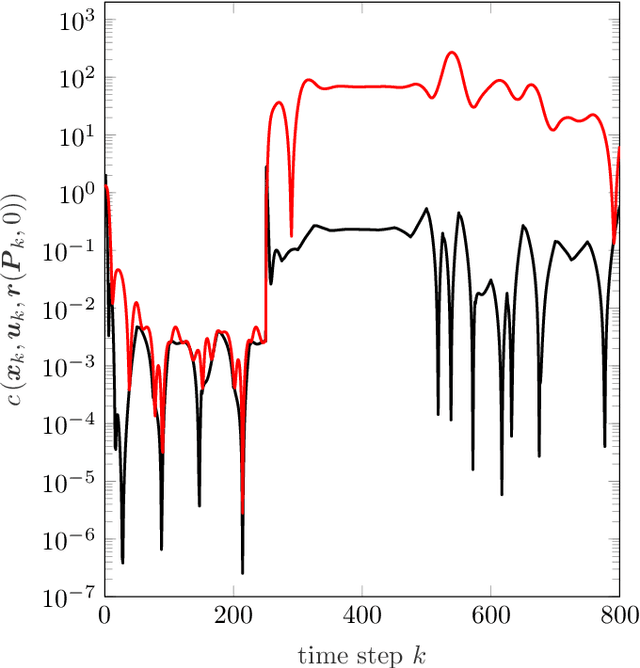
In order to autonomously learn to control unknown systems optimally w.r.t. an objective function, Adaptive Dynamic Programming (ADP) is well-suited to adapt controllers based on experience from interaction with the system. In recent years, many researchers focused on the tracking case, where the aim is to follow a desired trajectory. So far, ADP tracking controllers assume that the reference trajectory follows time-invariant exo-system dynamics-an assumption that does not hold for many applications. In order to overcome this limitation, we propose a new Q-function which explicitly incorporates a parametrized approximation of the reference trajectory. This allows to learn to track a general class of trajectories by means of ADP. Once our Q-function has been learned, the associated controller copes with time-varying reference trajectories without need of further training and independent of exo-system dynamics. After proposing our general model-free off-policy tracking method, we provide analysis of the important special case of linear quadratic tracking. We conclude our paper with an example which demonstrates that our new method successfully learns the optimal tracking controller and outperforms existing approaches in terms of tracking error and cost.