 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Optimization for Tracking Control Exploiting Future Reference Information
Jul 20, 2021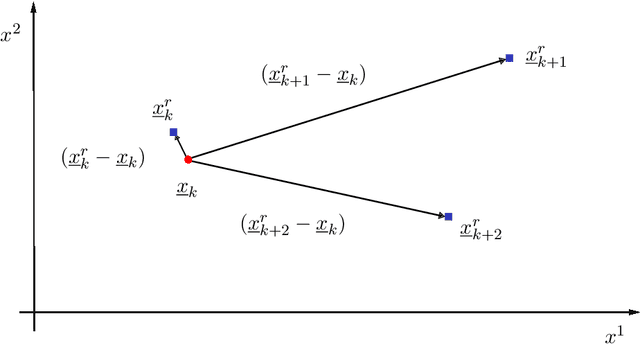

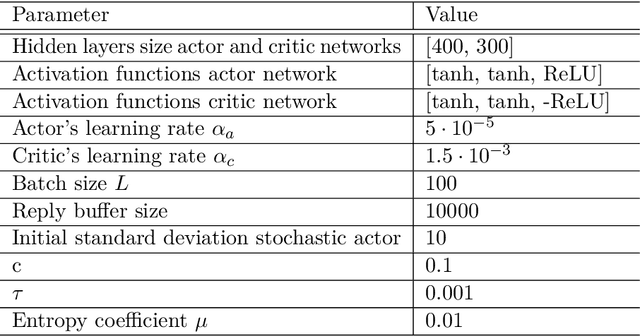
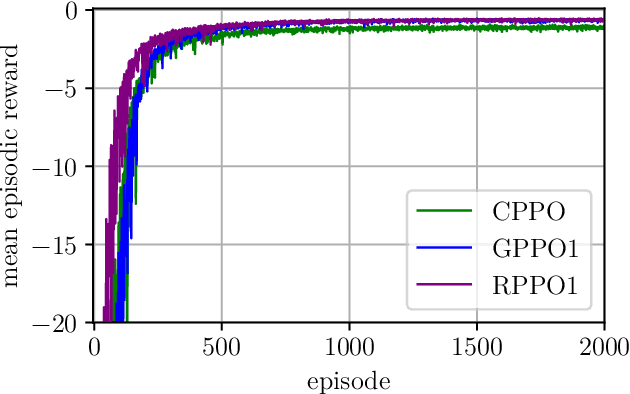
In recent years, reinforcement learning (RL) has gained increasing attention in control engineering. Especially, policy gradient methods are widely used. In this work, we improve the tracking performance of proximal policy optimization (PPO) for arbitrary reference signals by incorporating information about future reference values. Two variants of extending the argument of the actor and the critic taking future reference values into account are presented. In the first variant, global future reference values are added to the argument. For the second variant, a novel kind of residual space with future reference values applicable to model-free reinforcement learning is introduced. Our approach is evaluated against a PI controller on a simple drive train model. We expect our method to generalize to arbitrary references better than previous approaches, pointing towards the applicability of RL to control real systems.
Adaptive Optimal Control for Reference Tracking Independent of Exo-System Dynamics
Jul 24, 2019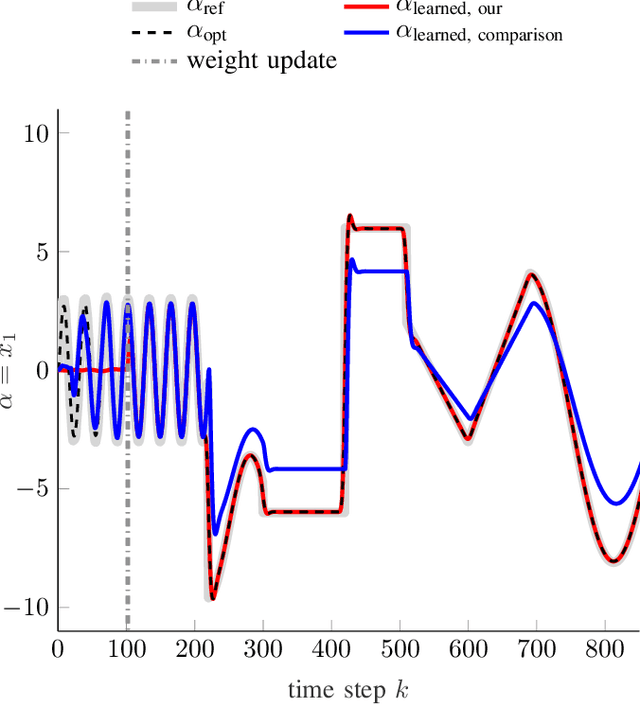

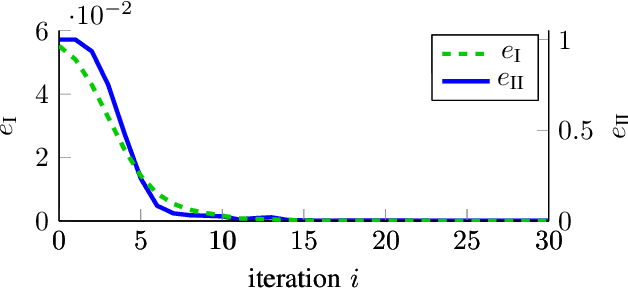
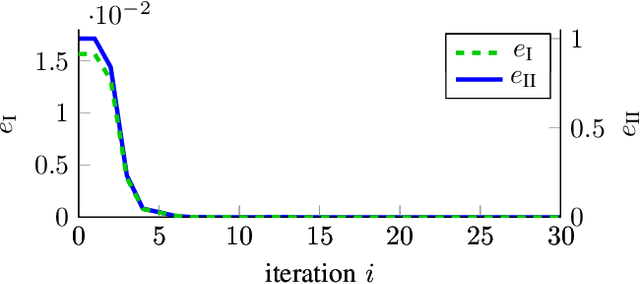
Model-free control based on the idea of Reinforcement Learning is a promising approach that has recently gained extensive attention. However, Reinforcement-Learning-based control methods solely focus on the regulation problem or learn to track a reference that is generated by a time-invariant exo-system. In the latter case, controllers are only able to track the time-invariant reference dynamics which they have been trained on and need to be re-trained each time the reference dynamics change. Consequently, these methods fail in a number of applications which obviously rely on a trajectory not being generated by an exo-system. One prominent example is autonomous driving. This paper provides for the first time an adaptive optimal control method capable to track reference trajectories not being generated by an exo-system. The main innovation is a novel Q-function that directly incorporates a given reference trajectory on a moving horizon. This new Q-function exhibits a particular structure which allows the design of an efficient, iterative, provably convergent Reinforcement Learning algorithm that enables optimal tracking. Two real-world examples demonstrate by simulation that our new method outperforms existing approaches in terms of tracking error.