 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Optimization for Tracking Control Exploiting Future Reference Information
Jul 20, 2021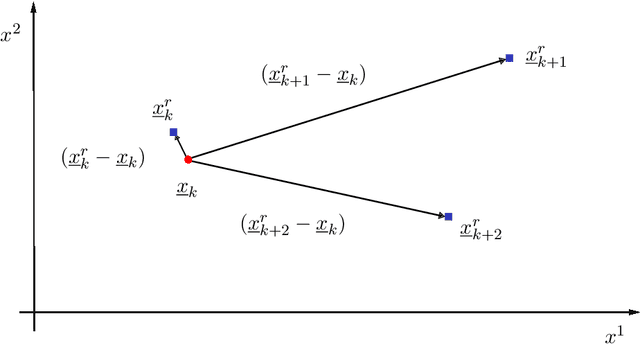

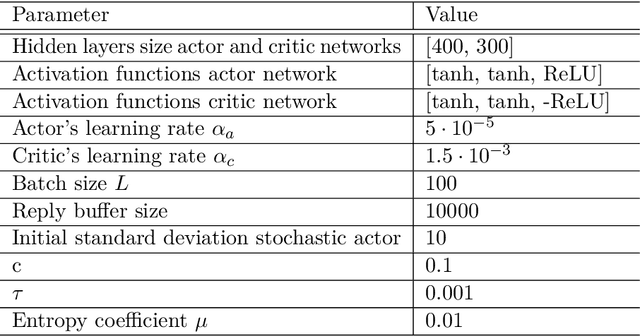
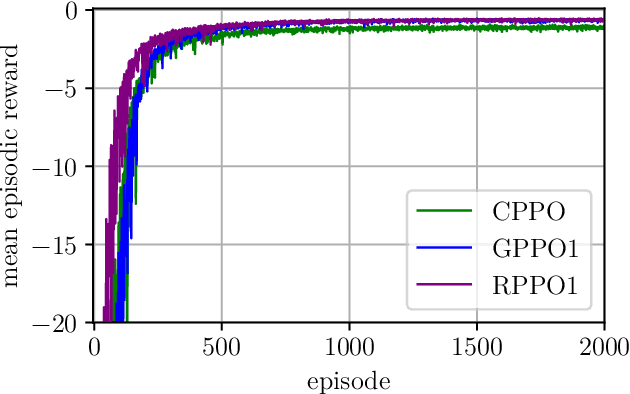
In recent years, reinforcement learning (RL) has gained increasing attention in control engineering. Especially, policy gradient methods are widely used. In this work, we improve the tracking performance of proximal policy optimization (PPO) for arbitrary reference signals by incorporating information about future reference values. Two variants of extending the argument of the actor and the critic taking future reference values into account are presented. In the first variant, global future reference values are added to the argument. For the second variant, a novel kind of residual space with future reference values applicable to model-free reinforcement learning is introduced. Our approach is evaluated against a PI controller on a simple drive train model. We expect our method to generalize to arbitrary references better than previous approaches, pointing towards the applicability of RL to control real systems.