 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe-GS: Coarse-to-Refined Gaussian Splatting with Semantic Object Focus
Sep 05, 2025Mobile reconstruction for autonomous aerial robotics holds strong potential for critical applications such as tele-guidance and disaster response. These tasks demand both accurate 3D reconstruction and fast scene processing. Instead of reconstructing the entire scene in detail, it is often more efficient to focus on specific objects, i.e., points of interest (PoIs). Mobile robots equipped with advanced sensing can usually detect these early during data acquisition or preliminary analysis, reducing the need for full-scene optimization. Gaussian Splatting (GS) has recently shown promise in delivering high-quality novel view synthesis and 3D representation by an incremental learning process. Extending GS with scene editing, semantics adds useful per-splat features to isolate objects effectively. Semantic 3D Gaussian editing can already be achieved before the full training cycle is completed, reducing the overall training time. Moreover, the semantically relevant area, the PoI, is usually already known during capturing. To balance high-quality reconstruction with reduced training time, we propose CoRe-GS. We first generate a coarse segmentation-ready scene with semantic GS and then refine it for the semantic object using our novel color-based effective filtering for effective object isolation. This is speeding up the training process to be about a quarter less than a full training cycle for semantic GS. We evaluate our approach on two datasets, SCRREAM (real-world, outdoor) and NeRDS 360 (synthetic, indoor), showing reduced runtime and higher novel-view-synthesis quality.
Latent Action Priors From a Single Gait Cycle Demonstration for Online Imitation Learning
Oct 04, 2024



Deep Reinforcement Learning (DRL) in simulation often results in brittle and unrealistic learning outcomes. To push the agent towards more desirable solutions, prior information can be injected in the learning process through, for instance, reward shaping, expert data, or motion primitives. We propose an additional inductive bias for robot learning: latent actions learned from expert demonstration as priors in the action space. We show that these action priors can be learned from only a single open-loop gait cycle using a simple autoencoder. Using these latent action priors combined with established style rewards for imitation in DRL achieves above expert demonstration level of performance and leads to more desirable gaits. Further, action priors substantially improve the performance on transfer tasks, even leading to gait transitions for higher target speeds. Videos and code are available at https://sites.google.com/view/latent-action-priors.
Reinforcement Learning with Lie Group Orientations for Robotics
Sep 18, 2024



Handling orientations of robots and objects is a crucial aspect of many applications. Yet, ever so often, there is a lack of mathematical correctness when dealing with orientations, especially in learning pipelines involving, for example, artificial neural networks. In this paper, we investigate reinforcement learning with orientations and propose a simple modification of the network's input and output that adheres to the Lie group structure of orientations. As a result, we obtain an easy and efficient implementation that is directly usable with existing learning libraries and achieves significantly better performance than other common orientation representations. We briefly introduce Lie theory specifically for orientations in robotics to motivate and outline our approach. Subsequently, a thorough empirical evaluation of different combinations of orientation representations for states and actions demonstrates the superior performance of our proposed approach in different scenarios, including: direct orientation control, end effector orientation control, and pick-and-place tasks.
Does Unpredictability Influence Driving Behavior?
Jul 28, 2023



In this paper we investigate the effect of the unpredictability of surrounding cars on an ego-car performing a driving maneuver. We use Maximum Entropy Inverse Reinforcement Learning to model reward functions for an ego-car conducting a lane change in a highway setting. We define a new feature based on the unpredictability of surrounding cars and use it in the reward function. We learn two reward functions from human data: a baseline and one that incorporates our defined unpredictability feature, then compare their performance with a quantitative and qualitative evaluation. Our evaluation demonstrates that incorporating the unpredictability feature leads to a better fit of human-generated test data. These results encourage further investigation of the effect of unpredictability on driving behavior.
Perception-aware Tag Placement Planning for Robust Localization of UAVs in Indoor Construction Environments
Oct 27, 2022



Tag-based visual-inertial localization is a lightweight method for enabling autonomous data collection missions of low-cost unmanned aerial vehicles (UAVs) in indoor construction environments. However, finding the optimal tag configuration (i.e., number, size, and location) on dynamic construction sites remains challenging. This paper proposes a perception-aware genetic algorithm-based tag placement planner (PGA-TaPP) to determine the optimal tag configuration using 4D-BIM, considering the project progress, safety requirements, and UAV's localizability. The proposed method provides a 4D plan for tag placement by maximizing the localizability in user-specified regions of interest (ROIs) while limiting the installation costs. Localizability is quantified using the Fisher information matrix (FIM) and encapsulated in navigable grids. The experimental results show the effectiveness of our method in finding an optimal 4D tag placement plan for the robust localization of UAVs on under-construction indoor sites.
Adaptive Model Predictive Control for High-Accuracy Trajectory Tracking in Changing Conditions
Aug 02, 2018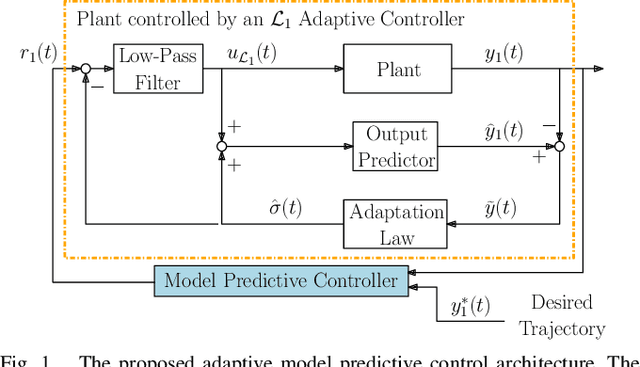



Robots and automated systems are increasingly being introduced to unknown and dynamic environments where they are required to handle disturbances, unmodeled dynamics, and parametric uncertainties. Robust and adaptive control strategies are required to achieve high performance in these dynamic environments. In this paper, we propose a novel adaptive model predictive controller that combines model predictive control (MPC) with an underlying $\mathcal{L}_1$ adaptive controller to improve trajectory tracking of a system subject to unknown and changing disturbances. The $\mathcal{L}_1$ adaptive controller forces the system to behave in a predefined way, as specified by a reference model. A higher-level model predictive controller then uses this reference model to calculate the optimal reference input based on a cost function, while taking into account input and state constraints. We focus on the experimental validation of the proposed approach and demonstrate its effectiveness in experiments on a quadrotor. We show that the proposed approach has a lower trajectory tracking error compared to non-predictive, adaptive approaches and a predictive, non-adaptive approach, even when external wind disturbances are applied.