 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGA: Open-World Mobile Manipulation via Structured Affordance Grounding
Dec 14, 2025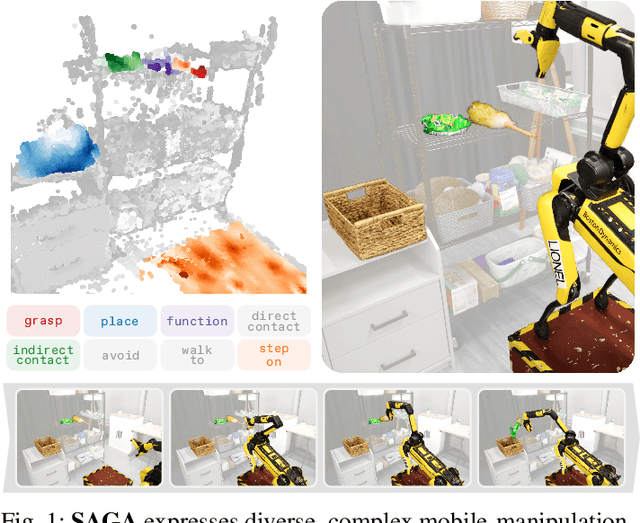
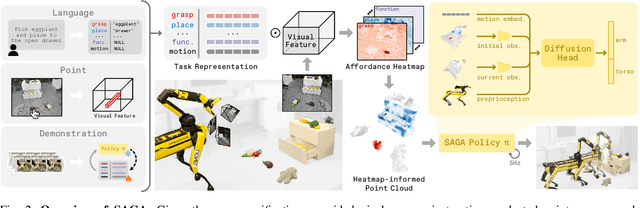
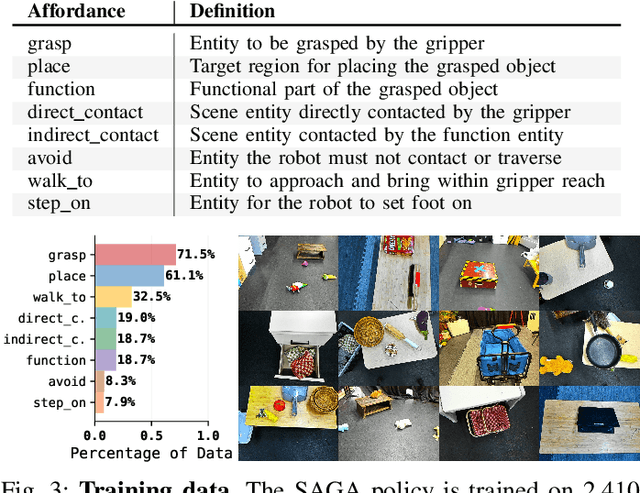
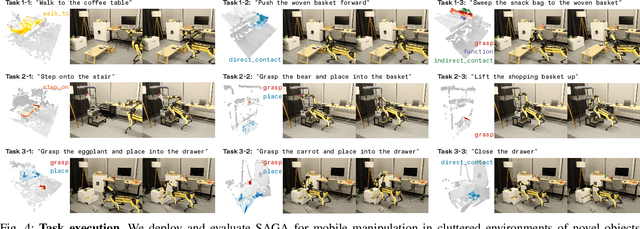
We present SAGA, a versatile and adaptive framework for visuomotor control that can generalize across various environments, task objectives, and user specifications. To efficiently learn such capability, our key idea is to disentangle high-level semantic intent from low-level visuomotor control by explicitly grounding task objectives in the observed environment. Using an affordance-based task representation, we express diverse and complex behaviors in a unified, structured form. By leveraging multimodal foundation models, SAGA grounds the proposed task representation to the robot's visual observation as 3D affordance heatmaps, highlighting task-relevant entities while abstracting away spurious appearance variations that would hinder generalization. These grounded affordances enable us to effectively train a conditional policy on multi-task demonstration data for whole-body control. In a unified framework, SAGA can solve tasks specified in different forms, including language instructions, selected points, and example demonstrations, enabling both zero-shot execution and few-shot adaptation. We instantiate SAGA on a quadrupedal manipulator and conduct extensive experiments across eleven real-world tasks. SAGA consistently outperforms end-to-end and modular baselines by substantial margins. Together, these results demonstrate that structured affordance grounding offers a scalable and effective pathway toward generalist mobile manipulation.
Prompting with the Future: Open-World Model Predictive Control with Interactive Digital Twins
Jun 16, 2025Recent advancements in open-world robot manipulation have been largely driven by vision-language models (VLMs). While these models exhibit strong generalization ability in high-level planning, they struggle to predict low-level robot controls due to limited physical-world understanding. To address this issue, we propose a model predictive control framework for open-world manipulation that combines the semantic reasoning capabilities of VLMs with physically-grounded, interactive digital twins of the real-world environments. By constructing and simulating the digital twins, our approach generates feasible motion trajectories, simulates corresponding outcomes, and prompts the VLM with future observations to evaluate and select the most suitable outcome based on language instructions of the task. To further enhance the capability of pre-trained VLMs in understanding complex scenes for robotic control, we leverage the flexible rendering capabilities of the digital twin to synthesize the scene at various novel, unoccluded viewpoints. We validate our approach on a diverse set of complex manipulation tasks, demonstrating superior performance compared to baseline methods for language-conditioned robotic control using VLMs.
Versatile Loco-Manipulation through Flexible Interlimb Coordination
Jun 09, 2025The ability to flexibly leverage limbs for loco-manipulation is essential for enabling autonomous robots to operate in unstructured environments. Yet, prior work on loco-manipulation is often constrained to specific tasks or predetermined limb configurations. In this work, we present Reinforcement Learning for Interlimb Coordination (ReLIC), an approach that enables versatile loco-manipulation through flexible interlimb coordination. The key to our approach is an adaptive controller that seamlessly bridges the execution of manipulation motions and the generation of stable gaits based on task demands. Through the interplay between two controller modules, ReLIC dynamically assigns each limb for manipulation or locomotion and robustly coordinates them to achieve the task success. Using efficient reinforcement learning in simulation, ReLIC learns to perform stable gaits in accordance with the manipulation goals in the real world. To solve diverse and complex tasks, we further propose to interface the learned controller with different types of task specifications, including target trajectories, contact points, and natural language instructions. Evaluated on 12 real-world tasks that require diverse and complex coordination patterns, ReLIC demonstrates its versatility and robustness by achieving a success rate of 78.9% on average. Videos and code can be found at https://relic-locoman.github.io/.
Temporal Representation Alignment: Successor Features Enable Emergent Compositionality in Robot Instruction Following Temporal Representation Alignment
Feb 08, 2025



Effective task representations should facilitate compositionality, such that after learning a variety of basic tasks, an agent can perform compound tasks consisting of multiple steps simply by composing the representations of the constituent steps together. While this is conceptually simple and appealing, it is not clear how to automatically learn representations that enable this sort of compositionality. We show that learning to associate the representations of current and future states with a temporal alignment loss can improve compositional generalization, even in the absence of any explicit subtask planning or reinforcement learning. We evaluate our approach across diverse robotic manipulation tasks as well as in simulation, showing substantial improvements for tasks specified with either language or goal images.
Should We Learn Contact-Rich Manipulation Policies from Sampling-Based Planners?
Dec 12, 2024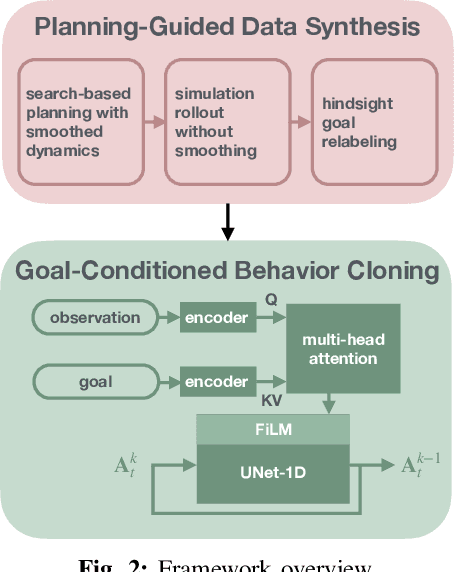
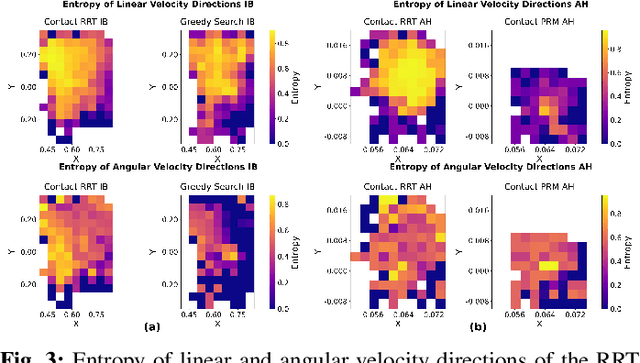

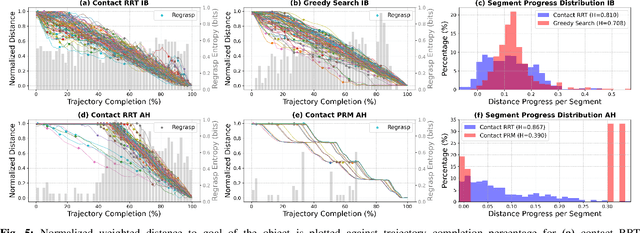
The tremendous success of behavior cloning (BC) in robotic manipulation has been largely confined to tasks where demonstrations can be effectively collected through human teleoperation. However, demonstrations for contact-rich manipulation tasks that require complex coordination of multiple contacts are difficult to collect due to the limitations of current teleoperation interfaces. We investigate how to leverage model-based planning and optimization to generate training data for contact-rich dexterous manipulation tasks. Our analysis reveals that popular sampling-based planners like rapidly exploring random tree (RRT), while efficient for motion planning, produce demonstrations with unfavorably high entropy. This motivates modifications to our data generation pipeline that prioritizes demonstration consistency while maintaining solution diversity. Combined with a diffusion-based goal-conditioned BC approach, our method enables effective policy learning and zero-shot transfer to hardware for two challenging contact-rich manipulation tasks.
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
Dec 03, 2024



Contact-rich bimanual manipulation involves precise coordination of two arms to change object states through strategically selected contacts and motions. Due to the inherent complexity of these tasks, acquiring sufficient demonstration data and training policies that generalize to unseen scenarios remain a largely unresolved challenge. Building on recent advances in planning through contacts, we introduce Generalizable Planning-Guided Diffusion Policy Learning (GLIDE), an approach that effectively learns to solve contact-rich bimanual manipulation tasks by leveraging model-based motion planners to generate demonstration data in high-fidelity physics simulation. Through efficient planning in randomized environments, our approach generates large-scale and high-quality synthetic motion trajectories for tasks involving diverse objects and transformations. We then train a task-conditioned diffusion policy via behavior cloning using these demonstrations. To tackle the sim-to-real gap, we propose a set of essential design options in feature extraction, task representation, action prediction, and data augmentation that enable learning robust prediction of smooth action sequences and generalization to unseen scenarios. Through experiments in both simulation and the real world, we demonstrate that our approach can enable a bimanual robotic system to effectively manipulate objects of diverse geometries, dimensions, and physical properties. Website: https://glide-manip.github.io/
Blox-Net: Generative Design-for-Robot-Assembly Using VLM Supervision, Physics Simulation, and a Robot with Reset
Sep 25, 2024
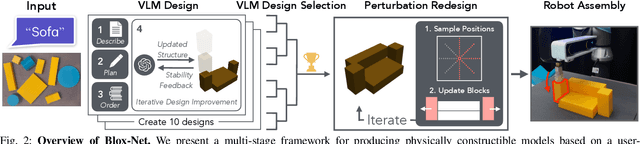


Generative AI systems have shown impressive capabilities in creating text, code, and images. Inspired by the rich history of research in industrial ''Design for Assembly'', we introduce a novel problem: Generative Design-for-Robot-Assembly (GDfRA). The task is to generate an assembly based on a natural language prompt (e.g., ''giraffe'') and an image of available physical components, such as 3D-printed blocks. The output is an assembly, a spatial arrangement of these components, and instructions for a robot to build this assembly. The output must 1) resemble the requested object and 2) be reliably assembled by a 6 DoF robot arm with a suction gripper. We then present Blox-Net, a GDfRA system that combines generative vision language models with well-established methods in computer vision, simulation, perturbation analysis, motion planning, and physical robot experimentation to solve a class of GDfRA problems with minimal human supervision. Blox-Net achieved a Top-1 accuracy of 63.5% in the ''recognizability'' of its designed assemblies (eg, resembling giraffe as judged by a VLM). These designs, after automated perturbation redesign, were reliably assembled by a robot, achieving near-perfect success across 10 consecutive assembly iterations with human intervention only during reset prior to assembly. Surprisingly, this entire design process from textual word (''giraffe'') to reliable physical assembly is performed with zero human intervention.
KALIE: Fine-Tuning Vision-Language Models for Open-World Manipulation without Robot Data
Sep 21, 2024
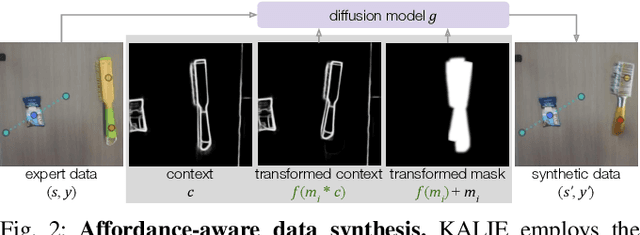


Building generalist robotic systems involves effectively endowing robots with the capabilities to handle novel objects in an open-world setting. Inspired by the advances of large pre-trained models, we propose Keypoint Affordance Learning from Imagined Environments (KALIE), which adapts pre-trained Vision Language Models (VLMs) for robotic control in a scalable manner. Instead of directly producing motor commands, KALIE controls the robot by predicting point-based affordance representations based on natural language instructions and visual observations of the scene. The VLM is trained on 2D images with affordances labeled by humans, bypassing the need for training data collected on robotic systems. Through an affordance-aware data synthesis pipeline, KALIE automatically creates massive high-quality training data based on limited example data manually collected by humans. We demonstrate that KALIE can learn to robustly solve new manipulation tasks with unseen objects given only 50 example data points. Compared to baselines using pre-trained VLMs, our approach consistently achieves superior performance.
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Aug 29, 2024

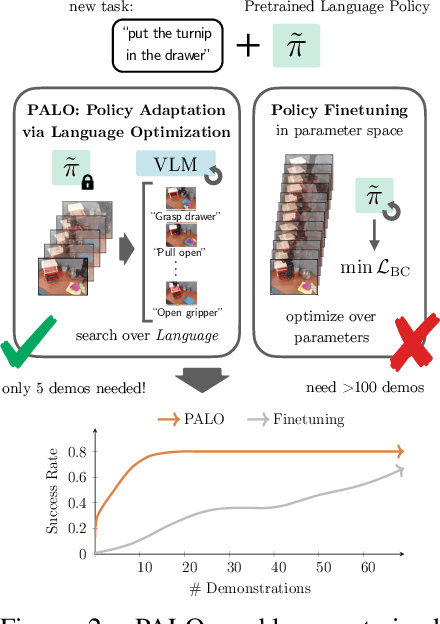

Learned language-conditioned robot policies often struggle to effectively adapt to new real-world tasks even when pre-trained across a diverse set of instructions. We propose a novel approach for few-shot adaptation to unseen tasks that exploits the semantic understanding of task decomposition provided by vision-language models (VLMs). Our method, Policy Adaptation via Language Optimization (PALO), combines a handful of demonstrations of a task with proposed language decompositions sampled from a VLM to quickly enable rapid nonparametric adaptation, avoiding the need for a larger fine-tuning dataset. We evaluate PALO on extensive real-world experiments consisting of challenging unseen, long-horizon robot manipulation tasks. We find that PALO is able of consistently complete long-horizon, multi-tier tasks in the real world, outperforming state of the art pre-trained generalist policies, and methods that have access to the same demonstrations.
Jacta: A Versatile Planner for Learning Dexterous and Whole-body Manipulation
Aug 02, 2024



Robotic manipulation is challenging due to discontinuous dynamics, as well as high-dimensional state and action spaces. Data-driven approaches that succeed in manipulation tasks require large amounts of data and expert demonstrations, typically from humans. Existing manipulation planners are restricted to specific systems and often depend on specialized algorithms for using demonstration. Therefore, we introduce a flexible motion planner tailored to dexterous and whole-body manipulation tasks. Our planner creates readily usable demonstrations for reinforcement learning algorithms, eliminating the need for additional training pipeline complexities. With this approach, we can efficiently learn policies for complex manipulation tasks, where traditional reinforcement learning alone only makes little progress. Furthermore, we demonstrate that learned policies are transferable to real robotic systems for solving complex dexterous manipulation tasks.