 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Diffusion: Training Diffusion Policies on Cross-Embodiment Human Demonstrations
Nov 06, 2025Human videos can be recorded quickly and at scale, making them an appealing source of training data for robot learning. However, humans and robots differ fundamentally in embodiment, resulting in mismatched action execution. Direct kinematic retargeting of human hand motion can therefore produce actions that are physically infeasible for robots. Despite these low-level differences, human demonstrations provide valuable motion cues about how to manipulate and interact with objects. Our key idea is to exploit the forward diffusion process: as noise is added to actions, low-level execution differences fade while high-level task guidance is preserved. We present X-Diffusion, a principled framework for training diffusion policies that maximally leverages human data without learning dynamically infeasible motions. X-Diffusion first trains a classifier to predict whether a noisy action is executed by a human or robot. Then, a human action is incorporated into policy training only after adding sufficient noise such that the classifier cannot discern its embodiment. Actions consistent with robot execution supervise fine-grained denoising at low noise levels, while mismatched human actions provide only coarse guidance at higher noise levels. Our experiments show that naive co-training under execution mismatches degrades policy performance, while X-Diffusion consistently improves it. Across five manipulation tasks, X-Diffusion achieves a 16% higher average success rate than the best baseline. The project website is available at https://portal-cornell.github.io/X-Diffusion/.
Prompting with the Future: Open-World Model Predictive Control with Interactive Digital Twins
Jun 16, 2025Recent advancements in open-world robot manipulation have been largely driven by vision-language models (VLMs). While these models exhibit strong generalization ability in high-level planning, they struggle to predict low-level robot controls due to limited physical-world understanding. To address this issue, we propose a model predictive control framework for open-world manipulation that combines the semantic reasoning capabilities of VLMs with physically-grounded, interactive digital twins of the real-world environments. By constructing and simulating the digital twins, our approach generates feasible motion trajectories, simulates corresponding outcomes, and prompts the VLM with future observations to evaluate and select the most suitable outcome based on language instructions of the task. To further enhance the capability of pre-trained VLMs in understanding complex scenes for robotic control, we leverage the flexible rendering capabilities of the digital twin to synthesize the scene at various novel, unoccluded viewpoints. We validate our approach on a diverse set of complex manipulation tasks, demonstrating superior performance compared to baseline methods for language-conditioned robotic control using VLMs.
GarmentLab: A Unified Simulation and Benchmark for Garment Manipulation
Nov 02, 2024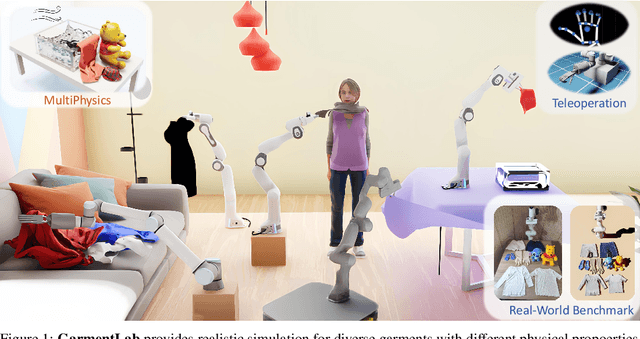

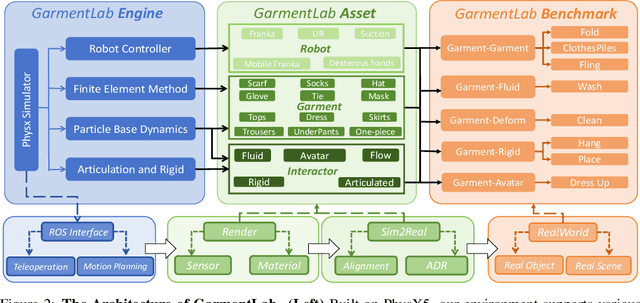
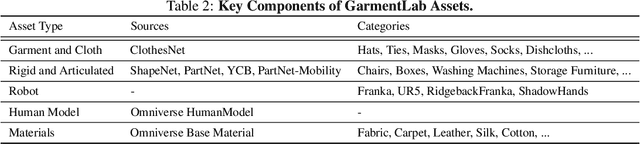
Manipulating garments and fabrics has long been a critical endeavor in the development of home-assistant robots. However, due to complex dynamics and topological structures, garment manipulations pose significant challenges. Recent successes in reinforcement learning and vision-based methods offer promising avenues for learning garment manipulation. Nevertheless, these approaches are severely constrained by current benchmarks, which offer limited diversity of tasks and unrealistic simulation behavior. Therefore, we present GarmentLab, a content-rich benchmark and realistic simulation designed for deformable object and garment manipulation. Our benchmark encompasses a diverse range of garment types, robotic systems and manipulators. The abundant tasks in the benchmark further explores of the interactions between garments, deformable objects, rigid bodies, fluids, and human body. Moreover, by incorporating multiple simulation methods such as FEM and PBD, along with our proposed sim-to-real algorithms and real-world benchmark, we aim to significantly narrow the sim-to-real gap. We evaluate state-of-the-art vision methods, reinforcement learning, and imitation learning approaches on these tasks, highlighting the challenges faced by current algorithms, notably their limited generalization capabilities. Our proposed open-source environments and comprehensive analysis show promising boost to future research in garment manipulation by unlocking the full potential of these methods. We guarantee that we will open-source our code as soon as possible. You can watch the videos in supplementary files to learn more about the details of our work. Our project page is available at: https://garmentlab.github.io/
Broadcasting Support Relations Recursively from Local Dynamics for Object Retrieval in Clutters
Jun 04, 2024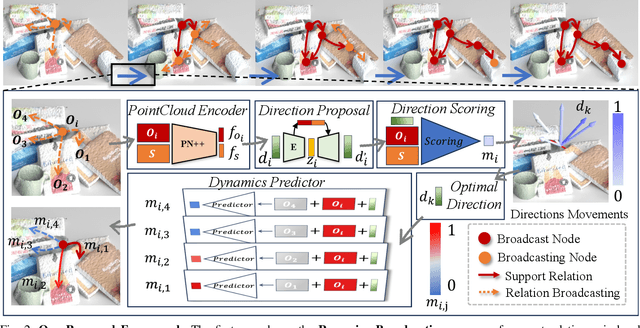
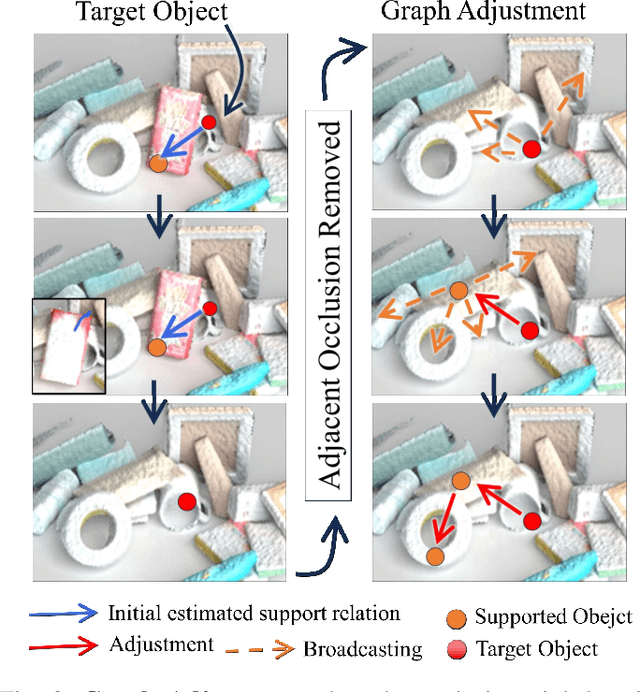

In our daily life, cluttered objects are everywhere, from scattered stationery and books cluttering the table to bowls and plates filling the kitchen sink. Retrieving a target object from clutters is an essential while challenging skill for robots, for the difficulty of safely manipulating an object without disturbing others, which requires the robot to plan a manipulation sequence and first move away a few other objects supported by the target object step by step. However, due to the diversity of object configurations (e.g., categories, geometries, locations and poses) and their combinations in clutters, it is difficult for a robot to accurately infer the support relations between objects faraway with various objects in between. In this paper, we study retrieving objects in complicated clutters via a novel method of recursively broadcasting the accurate local dynamics to build a support relation graph of the whole scene, which largely reduces the complexity of the support relation inference and improves the accuracy. Experiments in both simulation and the real world demonstrate the efficiency and effectiveness of our method.
Learning Environment-Aware Affordance for 3D Articulated Object Manipulation under Occlusions
Sep 25, 2023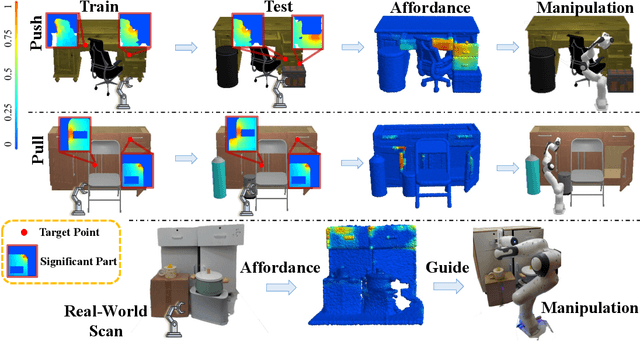
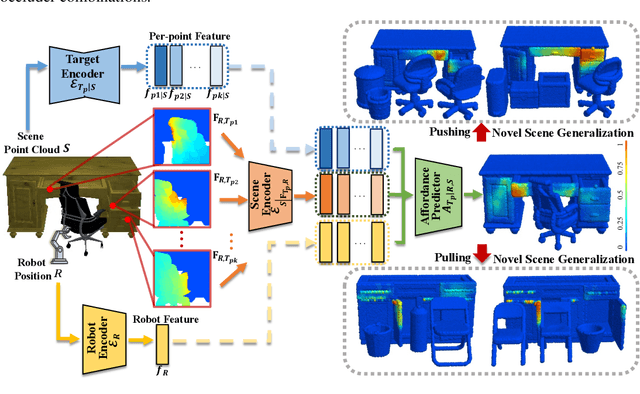

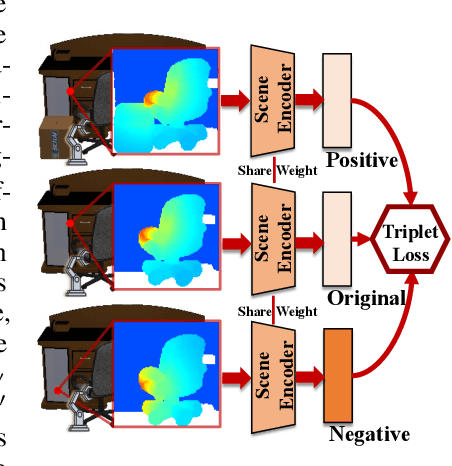
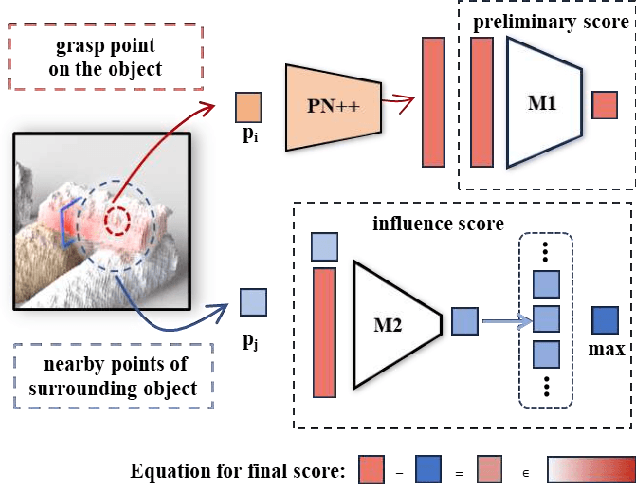
Perceiving and manipulating 3D articulated objects in diverse environments is essential for home-assistant robots. Recent studies have shown that point-level affordance provides actionable priors for downstream manipulation tasks. However, existing works primarily focus on single-object scenarios with homogeneous agents, overlooking the realistic constraints imposed by the environment and the agent's morphology, e.g., occlusions and physical limitations. In this paper, we propose an environment-aware affordance framework that incorporates both object-level actionable priors and environment constraints. Unlike object-centric affordance approaches, learning environment-aware affordance faces the challenge of combinatorial explosion due to the complexity of various occlusions, characterized by their quantities, geometries, positions and poses. To address this and enhance data efficiency, we introduce a novel contrastive affordance learning framework capable of training on scenes containing a single occluder and generalizing to scenes with complex occluder combinations. Experiments demonstrate the effectiveness of our proposed approach in learning affordance considering environment constraints. Project page at https://chengkaiacademycity.github.io/EnvAwareAfford/
Where2Explore: Few-shot Affordance Learning for Unseen Novel Categories of Articulated Objects
Sep 14, 2023



Articulated object manipulation is a fundamental yet challenging task in robotics. Due to significant geometric and semantic variations across object categories, previous manipulation models struggle to generalize to novel categories. Few-shot learning is a promising solution for alleviating this issue by allowing robots to perform a few interactions with unseen objects. However, extant approaches often necessitate costly and inefficient test-time interactions with each unseen instance. Recognizing this limitation, we observe that despite their distinct shapes, different categories often share similar local geometries essential for manipulation, such as pullable handles and graspable edges - a factor typically underutilized in previous few-shot learning works. To harness this commonality, we introduce 'Where2Explore', an affordance learning framework that effectively explores novel categories with minimal interactions on a limited number of instances. Our framework explicitly estimates the geometric similarity across different categories, identifying local areas that differ from shapes in the training categories for efficient exploration while concurrently transferring affordance knowledge to similar parts of the objects. Extensive experiments in simulated and real-world environments demonstrate our framework's capacity for efficient few-shot exploration and generalization.
Learning Foresightful Dense Visual Affordance for Deformable Object Manipulation
Mar 25, 2023Understanding and manipulating deformable objects (e.g., ropes and fabrics) is an essential yet challenging task with broad applications. Difficulties come from complex states and dynamics, diverse configurations and high-dimensional action space of deformable objects. Besides, the manipulation tasks usually require multiple steps to accomplish, and greedy policies may easily lead to local optimal states. Existing studies usually tackle this problem using reinforcement learning or imitating expert demonstrations, with limitations in modeling complex states or requiring hand-crafted expert policies. In this paper, we study deformable object manipulation using dense visual affordance, with generalization towards diverse states, and propose a novel kind of foresightful dense affordance, which avoids local optima by estimating states' values for long-term manipulation. We propose a framework for learning this representation, with novel designs such as multi-stage stable learning and efficient self-supervised data collection without experts. Experiments demonstrate the superiority of our proposed foresightful dense affordance. Project page: https://hyperplane-lab.github.io/DeformableAffordance