 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactBench: A Cause-Driven Benchmark for Multimodal Hallucination via Systematic Evaluation
May 28, 2026While multimodal large language models (MLLMs) have achieved rapid progress in vision-language understanding, they remain prone to multimodal hallucinations, producing responses that are inconsistent with the visual input. Existing benchmarks predominantly focus on detecting hallucination outcomes rather than evaluating the underlying causes of these failures. Moreover, many benchmarks rely on simplistic scenarios and limited evaluation formats that no longer challenge state-of-the-art models. To address these limitations, we introduce ReactBench, a cause-driven hallucination benchmark featuring multiple tasks and an exam-style evaluation format. By generating adversarial images and hallucination-inducing queries, ReactBench introduces four targeted tasks: Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting. These tasks systematically expose co-occurrence bias, language priors, cross-image comparative perception deficiencies, and fine-grained perceptual bottlenecks. Beyond standard accuracy-based evaluation, we leverage Chain-of-Thought reasoning to identify fine-grained sub-causes of hallucination within each task. Extensive evaluations reveal that current MLLMs remain notably vulnerable to cause-specific hallucination triggers, demonstrating the value of ReactBench as a systematic and interpretable testbed for diagnosing and improving multimodal model robustness. The project page is available at https://reactbench.github.io/.
LeHome: A Simulation Environment for Deformable Object Manipulation in Household Scenarios
Apr 24, 2026Household environments present one of the most common, impactful yet challenging application domains for robotics. Within household scenarios, manipulating deformable objects is particularly difficult, both in simulation and real-world execution, due to varied categories and shapes, complex dynamics, and diverse material properties, as well as the lack of reliable deformable-object support in existing simulations. We introduce LeHome, a comprehensive simulation environment designed for deformable object manipulation in household scenarios. LeHome covers a wide spectrum of deformable objects, such as garments and food items, offering high-fidelity dynamics and realistic interactions that existing simulators struggle to simulate accurately. Moreover, LeHome supports multiple robotic embodiments and emphasizes low-cost robots as a core focus, enabling end-to-end evaluation of household tasks on resource-constrained hardware. By bridging the gap between realistic deformable object simulation and practical robotic platforms, LeHome provides a scalable testbed for advancing household robotics. Webpage: https://lehome-web.github.io/ .
BiPreManip: Learning Affordance-Based Bimanual Preparatory Manipulation through Anticipatory Collaboration
Mar 23, 2026Many everyday objects are difficult to directly grasp (e.g., a flat iPad) or manipulate functionally (e.g., opening the cap of a pen lying on a desk). Such tasks require sequential, asymmetric coordination between two arms, where one arm performs preparatory manipulation that enables the other's goal-directed action - for instance, pushing the iPad to the table's edge before picking it up, or lifting the pen body to allow the other hand to remove its cap. In this work, we introduce Collaborative Preparatory Manipulation, a class of bimanual manipulation tasks that demand understanding object semantics and geometry, anticipating spatial relationships, and planning long-horizon coordinated actions between the two arms. To tackle this challenge, we propose a visual affordance-based framework that first envisions the final goal-directed action and then guides one arm to perform a sequence of preparatory manipulations that facilitate the other arm's subsequent operation. This affordance-centric representation enables anticipatory inter-arm reasoning and coordination, generalizing effectively across various objects spanning diverse categories. Extensive experiments in both simulation and the real world demonstrate that our approach substantially improves task success rates and generalization compared to competitive baselines.
A3D: Adaptive Affordance Assembly with Dual-Arm Manipulation
Jan 16, 2026Furniture assembly is a crucial yet challenging task for robots, requiring precise dual-arm coordination where one arm manipulates parts while the other provides collaborative support and stabilization. To accomplish this task more effectively, robots need to actively adapt support strategies throughout the long-horizon assembly process, while also generalizing across diverse part geometries. We propose A3D, a framework which learns adaptive affordances to identify optimal support and stabilization locations on furniture parts. The method employs dense point-level geometric representations to model part interaction patterns, enabling generalization across varied geometries. To handle evolving assembly states, we introduce an adaptive module that uses interaction feedback to dynamically adjust support strategies during assembly based on previous interactions. We establish a simulation environment featuring 50 diverse parts across 8 furniture types, designed for dual-arm collaboration evaluation. Experiments demonstrate that our framework generalizes effectively to diverse part geometries and furniture categories in both simulation and real-world settings.
Towards Reliable Forgetting: A Survey on Machine Unlearning Verification, Challenges, and Future Directions
Jun 18, 2025With growing demands for privacy protection, security, and legal compliance (e.g., GDPR), machine unlearning has emerged as a critical technique for ensuring the controllability and regulatory alignment of machine learning models. However, a fundamental challenge in this field lies in effectively verifying whether unlearning operations have been successfully and thoroughly executed. Despite a growing body of work on unlearning techniques, verification methodologies remain comparatively underexplored and often fragmented. Existing approaches lack a unified taxonomy and a systematic framework for evaluation. To bridge this gap, this paper presents the first structured survey of machine unlearning verification methods. We propose a taxonomy that organizes current techniques into two principal categories -- behavioral verification and parametric verification -- based on the type of evidence used to assess unlearning fidelity. We examine representative methods within each category, analyze their underlying assumptions, strengths, and limitations, and identify potential vulnerabilities in practical deployment. In closing, we articulate a set of open problems in current verification research, aiming to provide a foundation for developing more robust, efficient, and theoretically grounded unlearning verification mechanisms.
BiAssemble: Learning Collaborative Affordance for Bimanual Geometric Assembly
Jun 06, 2025Shape assembly, the process of combining parts into a complete whole, is a crucial robotic skill with broad real-world applications. Among various assembly tasks, geometric assembly--where broken parts are reassembled into their original form (e.g., reconstructing a shattered bowl)--is particularly challenging. This requires the robot to recognize geometric cues for grasping, assembly, and subsequent bimanual collaborative manipulation on varied fragments. In this paper, we exploit the geometric generalization of point-level affordance, learning affordance aware of bimanual collaboration in geometric assembly with long-horizon action sequences. To address the evaluation ambiguity caused by geometry diversity of broken parts, we introduce a real-world benchmark featuring geometric variety and global reproducibility. Extensive experiments demonstrate the superiority of our approach over both previous affordance-based and imitation-based methods. Project page: https://sites.google.com/view/biassembly/.
SR3D: Unleashing Single-view 3D Reconstruction for Transparent and Specular Object Grasping
May 30, 2025Recent advancements in 3D robotic manipulation have improved grasping of everyday objects, but transparent and specular materials remain challenging due to depth sensing limitations. While several 3D reconstruction and depth completion approaches address these challenges, they suffer from setup complexity or limited observation information utilization. To address this, leveraging the power of single view 3D object reconstruction approaches, we propose a training free framework SR3D that enables robotic grasping of transparent and specular objects from a single view observation. Specifically, given single view RGB and depth images, SR3D first uses the external visual models to generate 3D reconstructed object mesh based on RGB image. Then, the key idea is to determine the 3D object's pose and scale to accurately localize the reconstructed object back into its original depth corrupted 3D scene. Therefore, we propose view matching and keypoint matching mechanisms,which leverage both the 2D and 3D's inherent semantic and geometric information in the observation to determine the object's 3D state within the scene, thereby reconstructing an accurate 3D depth map for effective grasp detection. Experiments in both simulation and real world show the reconstruction effectiveness of SR3D.
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
May 04, 2025In robotic, task goals can be conveyed through various modalities, such as language, goal images, and goal videos. However, natural language can be ambiguous, while images or videos may offer overly detailed specifications. To tackle these challenges, we introduce CrayonRobo that leverages comprehensive multi-modal prompts that explicitly convey both low-level actions and high-level planning in a simple manner. Specifically, for each key-frame in the task sequence, our method allows for manual or automatic generation of simple and expressive 2D visual prompts overlaid on RGB images. These prompts represent the required task goals, such as the end-effector pose and the desired movement direction after contact. We develop a training strategy that enables the model to interpret these visual-language prompts and predict the corresponding contact poses and movement directions in SE(3) space. Furthermore, by sequentially executing all key-frame steps, the model can complete long-horizon tasks. This approach not only helps the model explicitly understand the task objectives but also enhances its robustness on unseen tasks by providing easily interpretable prompts. We evaluate our method in both simulated and real-world environments, demonstrating its robust manipulation capabilities.
Using Powerful Prior Knowledge of Diffusion Model in Deep Unfolding Networks for Image Compressive Sensing
Mar 11, 2025Recently, Deep Unfolding Networks (DUNs) have achieved impressive reconstruction quality in the field of image Compressive Sensing (CS) by unfolding iterative optimization algorithms into neural networks. The reconstruction quality of DUNs depends on the learned prior knowledge, so introducing stronger prior knowledge can further improve reconstruction quality. On the other hand, pre-trained diffusion models contain powerful prior knowledge and have a solid theoretical foundation and strong scalability, but it requires a large number of iterative steps to achieve reconstruction. In this paper, we propose to use the powerful prior knowledge of pre-trained diffusion model in DUNs to achieve high-quality reconstruction with less steps for image CS. Specifically, we first design an iterative optimization algorithm named Diffusion Message Passing (DMP), which embeds a pre-trained diffusion model into each iteration process of DMP. Then, we deeply unfold the DMP algorithm into a neural network named DMP-DUN. The proposed DMP-DUN can use lightweight neural networks to achieve mapping from measurement data to the intermediate steps of the reverse diffusion process and directly approximate the divergence of the diffusion model, thereby further improving reconstruction efficiency. Extensive experiments show that our proposed DMP-DUN achieves state-of-the-art performance and requires at least only 2 steps to reconstruct the image. Codes are available at https://github.com/FengodChen/DMP-DUN-CVPR2025.
GarmentLab: A Unified Simulation and Benchmark for Garment Manipulation
Nov 02, 2024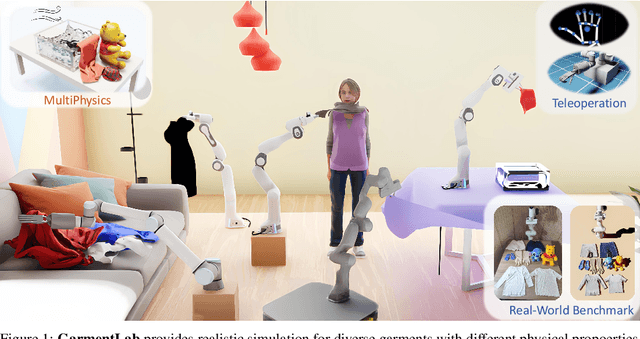

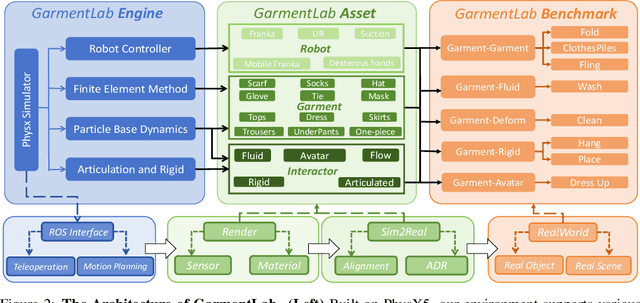
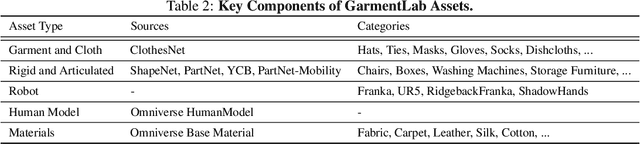
Manipulating garments and fabrics has long been a critical endeavor in the development of home-assistant robots. However, due to complex dynamics and topological structures, garment manipulations pose significant challenges. Recent successes in reinforcement learning and vision-based methods offer promising avenues for learning garment manipulation. Nevertheless, these approaches are severely constrained by current benchmarks, which offer limited diversity of tasks and unrealistic simulation behavior. Therefore, we present GarmentLab, a content-rich benchmark and realistic simulation designed for deformable object and garment manipulation. Our benchmark encompasses a diverse range of garment types, robotic systems and manipulators. The abundant tasks in the benchmark further explores of the interactions between garments, deformable objects, rigid bodies, fluids, and human body. Moreover, by incorporating multiple simulation methods such as FEM and PBD, along with our proposed sim-to-real algorithms and real-world benchmark, we aim to significantly narrow the sim-to-real gap. We evaluate state-of-the-art vision methods, reinforcement learning, and imitation learning approaches on these tasks, highlighting the challenges faced by current algorithms, notably their limited generalization capabilities. Our proposed open-source environments and comprehensive analysis show promising boost to future research in garment manipulation by unlocking the full potential of these methods. We guarantee that we will open-source our code as soon as possible. You can watch the videos in supplementary files to learn more about the details of our work. Our project page is available at: https://garmentlab.github.io/