 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATCH: A Controllable Theme Detection Framework with Contextualized Clustering and Hierarchical Generation
Dec 25, 2025Theme detection is a fundamental task in user-centric dialogue systems, aiming to identify the latent topic of each utterance without relying on predefined schemas. Unlike intent induction, which operates within fixed label spaces, theme detection requires cross-dialogue consistency and alignment with personalized user preferences, posing significant challenges. Existing methods often struggle with sparse, short utterances for accurate topic representation and fail to capture user-level thematic preferences across dialogues. To address these challenges, we propose CATCH (Controllable Theme Detection with Contextualized Clustering and Hierarchical Generation), a unified framework that integrates three core components: (1) context-aware topic representation, which enriches utterance-level semantics using surrounding topic segments; (2) preference-guided topic clustering, which jointly models semantic proximity and personalized feedback to align themes across dialogue; and (3) a hierarchical theme generation mechanism designed to suppress noise and produce robust, coherent topic labels. Experiments on a multi-domain customer dialogue benchmark (DSTC-12) demonstrate the effectiveness of CATCH with 8B LLM in both theme clustering and topic generation quality.
Trajectory Densification and Depth from Perspective-based Blur
Dec 09, 2025In the absence of a mechanical stabilizer, the camera undergoes inevitable rotational dynamics during capturing, which induces perspective-based blur especially under long-exposure scenarios. From an optical standpoint, perspective-based blur is depth-position-dependent: objects residing at distinct spatial locations incur different blur levels even under the same imaging settings. Inspired by this, we propose a novel method that estimate metric depth by examining the blur pattern of a video stream and dense trajectory via joint optical design algorithm. Specifically, we employ off-the-shelf vision encoder and point tracker to extract video information. Then, we estimate depth map via windowed embedding and multi-window aggregation, and densify the sparse trajectory from the optical algorithm using a vision-language model. Evaluations on multiple depth datasets demonstrate that our method attains strong performance over large depth range, while maintaining favorable generalization. Relative to the real trajectory in handheld shooting settings, our optical algorithm achieves superior precision and the dense reconstruction maintains strong accuracy.
SR3D: Unleashing Single-view 3D Reconstruction for Transparent and Specular Object Grasping
May 30, 2025Recent advancements in 3D robotic manipulation have improved grasping of everyday objects, but transparent and specular materials remain challenging due to depth sensing limitations. While several 3D reconstruction and depth completion approaches address these challenges, they suffer from setup complexity or limited observation information utilization. To address this, leveraging the power of single view 3D object reconstruction approaches, we propose a training free framework SR3D that enables robotic grasping of transparent and specular objects from a single view observation. Specifically, given single view RGB and depth images, SR3D first uses the external visual models to generate 3D reconstructed object mesh based on RGB image. Then, the key idea is to determine the 3D object's pose and scale to accurately localize the reconstructed object back into its original depth corrupted 3D scene. Therefore, we propose view matching and keypoint matching mechanisms,which leverage both the 2D and 3D's inherent semantic and geometric information in the observation to determine the object's 3D state within the scene, thereby reconstructing an accurate 3D depth map for effective grasp detection. Experiments in both simulation and real world show the reconstruction effectiveness of SR3D.
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
May 04, 2025In robotic, task goals can be conveyed through various modalities, such as language, goal images, and goal videos. However, natural language can be ambiguous, while images or videos may offer overly detailed specifications. To tackle these challenges, we introduce CrayonRobo that leverages comprehensive multi-modal prompts that explicitly convey both low-level actions and high-level planning in a simple manner. Specifically, for each key-frame in the task sequence, our method allows for manual or automatic generation of simple and expressive 2D visual prompts overlaid on RGB images. These prompts represent the required task goals, such as the end-effector pose and the desired movement direction after contact. We develop a training strategy that enables the model to interpret these visual-language prompts and predict the corresponding contact poses and movement directions in SE(3) space. Furthermore, by sequentially executing all key-frame steps, the model can complete long-horizon tasks. This approach not only helps the model explicitly understand the task objectives but also enhances its robustness on unseen tasks by providing easily interpretable prompts. We evaluate our method in both simulated and real-world environments, demonstrating its robust manipulation capabilities.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
Unsupervised Mutual Learning of Dialogue Discourse Parsing and Topic Segmentation
Jun 03, 2024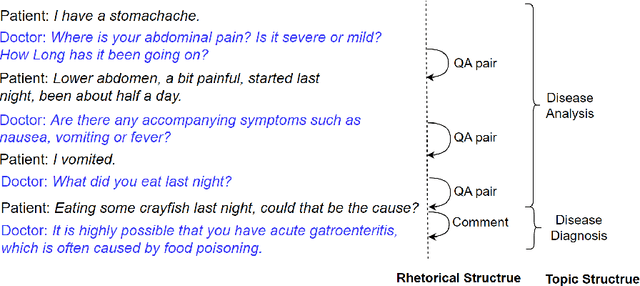

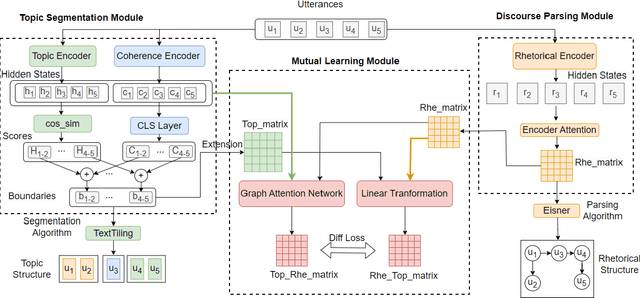

The advancement of large language models (LLMs) has propelled the development of dialogue systems. Unlike the popular ChatGPT-like assistant model, which only satisfies the user's preferences, task-oriented dialogue systems have also faced new requirements and challenges in the broader business field. They are expected to provide correct responses at each dialogue turn, at the same time, achieve the overall goal defined by the task. By understanding rhetorical structures and topic structures via topic segmentation and discourse parsing, a dialogue system may do a better planning to achieve both objectives. However, while both structures belong to discourse structure in linguistics, rhetorical structure and topic structure are mostly modeled separately or with one assisting the other in the prior work. The interaction between these two structures has not been considered for joint modeling and mutual learning. Furthermore, unsupervised learning techniques to achieve the above are not well explored. To fill this gap, we propose an unsupervised mutual learning framework of two structures leveraging the global and local connections between them. We extend the topic modeling between non-adjacent discourse units to ensure global structural relevance with rhetorical structures. We also incorporate rhetorical structures into the topic structure through a graph neural network model to ensure local coherence consistency. Finally, we utilize the similarity between the two fused structures for mutual learning. The experimental results demonstrate that our methods outperform all strong baselines on two dialogue rhetorical datasets (STAC and Molweni), as well as dialogue topic datasets (Doc2Dial and TIAGE). We provide our code at https://github.com/Jeff-Sue/URT.
Uncertainty-Aware Prediction and Application in Planning for Autonomous Driving: Definitions, Methods, and Comparison
Mar 04, 2024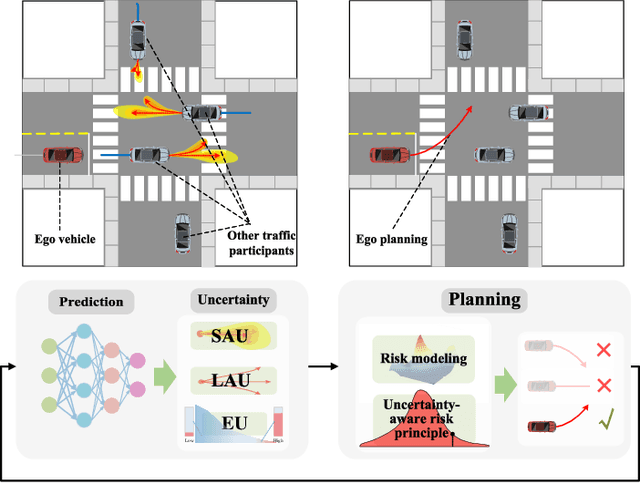

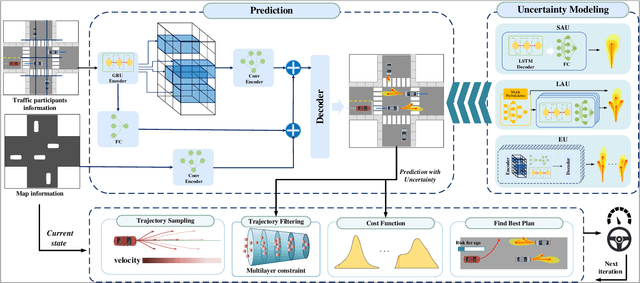

Autonomous driving systems face the formidable challenge of navigating intricate and dynamic environments with uncertainty. This study presents a unified prediction and planning framework that concurrently models short-term aleatoric uncertainty (SAU), long-term aleatoric uncertainty (LAU), and epistemic uncertainty (EU) to predict and establish a robust foundation for planning in dynamic contexts. The framework uses Gaussian mixture models and deep ensemble methods, to concurrently capture and assess SAU, LAU, and EU, where traditional methods do not integrate these uncertainties simultaneously. Additionally, uncertainty-aware planning is introduced, considering various uncertainties. The study's contributions include comparisons of uncertainty estimations, risk modeling, and planning methods in comparison to existing approaches. The proposed methods were rigorously evaluated using the CommonRoad benchmark and settings with limited perception. These experiments illuminated the advantages and roles of different uncertainty factors in autonomous driving processes. In addition, comparative assessments of various uncertainty modeling strategies underscore the benefits of modeling multiple types of uncertainties, thus enhancing planning accuracy and reliability. The proposed framework facilitates the development of methods for UAP and surpasses existing uncertainty-aware risk models, particularly when considering diverse traffic scenarios. Project page: https://swb19.github.io/UAP/.
Towards Safe and Reliable Autonomous Driving: Dynamic Occupancy Set Prediction
Feb 29, 2024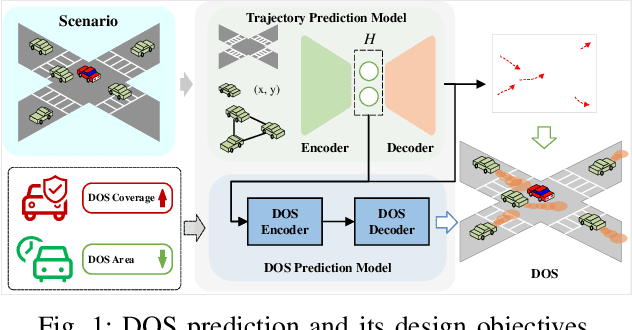
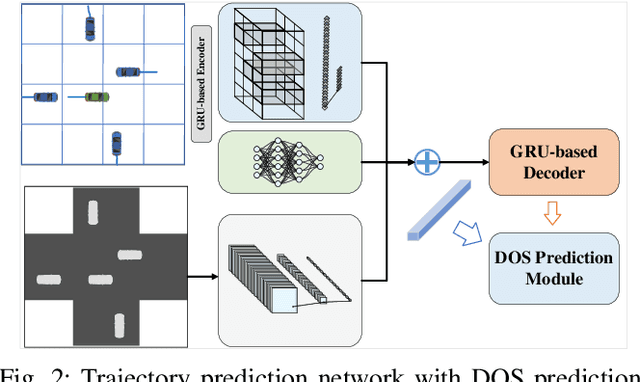
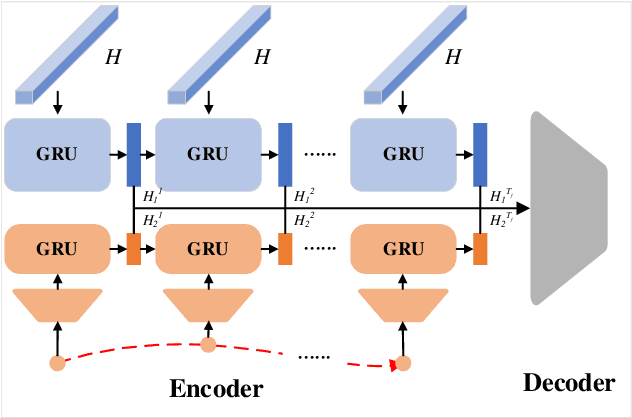
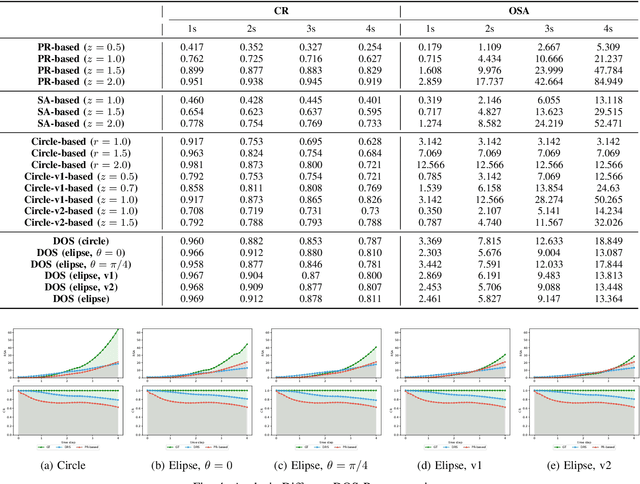
In the rapidly evolving field of autonomous driving, accurate trajectory prediction is pivotal for vehicular safety. However, trajectory predictions often deviate from actual paths, particularly in complex and challenging environments, leading to significant errors. To address this issue, our study introduces a novel method for Dynamic Occupancy Set (DOS) prediction, enhancing trajectory prediction capabilities. This method effectively combines advanced trajectory prediction networks with a DOS prediction module, overcoming the shortcomings of existing models. It provides a comprehensive and adaptable framework for predicting the potential occupancy sets of traffic participants. The main contributions of this research include: 1) A novel DOS prediction model tailored for complex scenarios, augmenting traditional trajectory prediction; 2) The development of unique DOS representations and evaluation metrics; 3) Extensive validation through experiments, demonstrating enhanced performance and adaptability. This research contributes to the advancement of safer and more efficient intelligent vehicle and transportation systems.
Pose2Gaze: Generating Realistic Human Gaze Behaviour from Full-body Poses using an Eye-body Coordination Model
Dec 19, 2023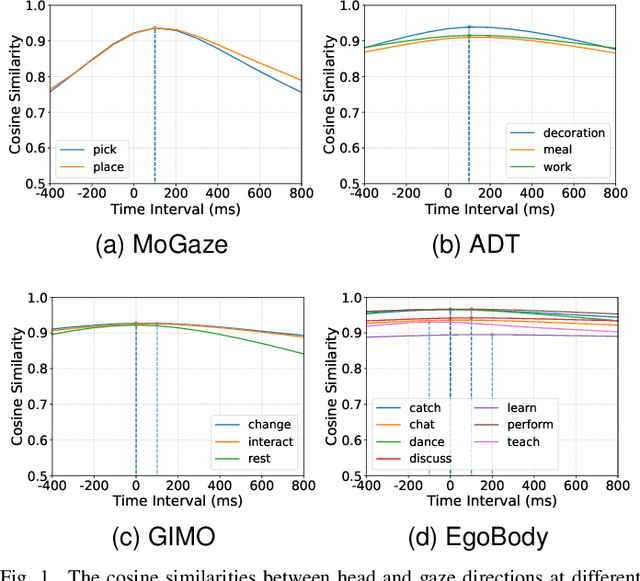
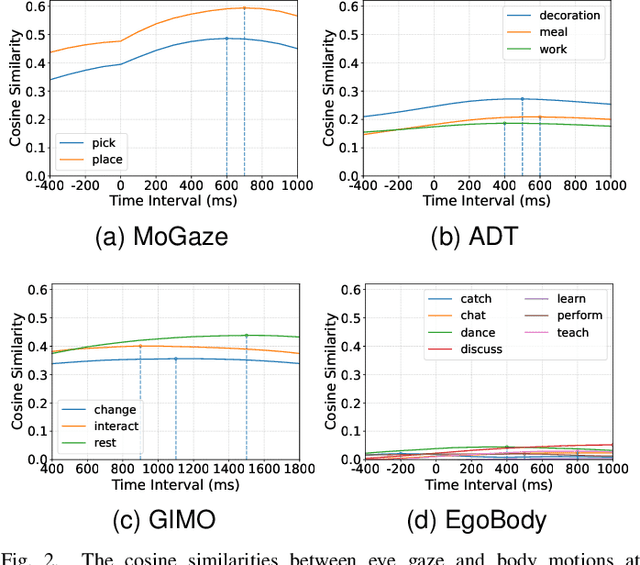
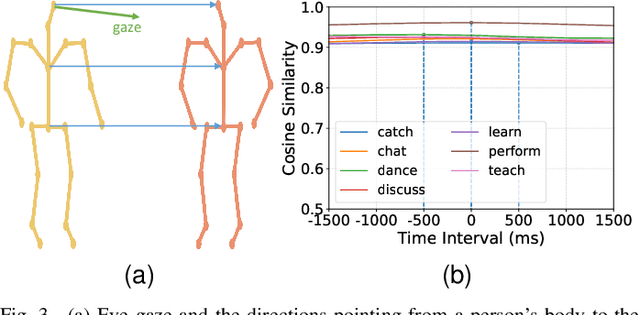
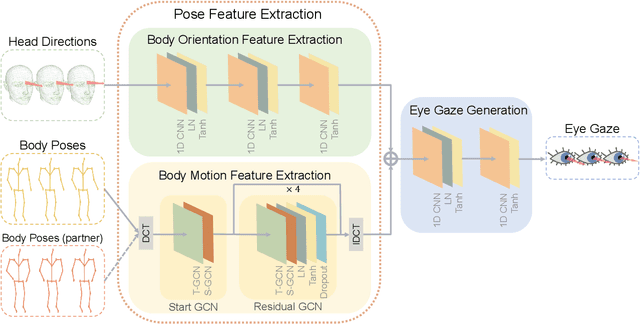
While generating realistic body movements, e.g., for avatars in virtual reality, is widely studied in computer vision and graphics, the generation of eye movements that exhibit realistic coordination with the body remains under-explored. We first report a comprehensive analysis of the coordination of human eye and full-body movements during everyday activities based on data from the MoGaze and GIMO datasets. We show that eye gaze has strong correlations with head directions and also full-body motions and there exists a noticeable time delay between body and eye movements. Inspired by the analyses, we then present Pose2Gaze -- a novel eye-body coordination model that first uses a convolutional neural network and a spatio-temporal graph convolutional neural network to extract features from head directions and full-body poses respectively and then applies a convolutional neural network to generate realistic eye movements. We compare our method with state-of-the-art methods that predict eye gaze only from head movements for three different generation tasks and demonstrate that Pose2Gaze significantly outperforms these baselines on both datasets with an average improvement of 26.4% and 21.6% in mean angular error, respectively. Our findings underline the significant potential of cross-modal human gaze behaviour analysis and modelling.
Enhancing Black-Box Few-Shot Text Classification with Prompt-Based Data Augmentation
May 23, 2023



Training or finetuning large-scale language models (LLMs) such as GPT-3 requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One practical area of research is to treat these models as black boxes and interact with them through their inference APIs. In this paper, we investigate how to optimize few-shot text classification without accessing the gradients of the LLMs. To achieve this, we treat the black-box model as a feature extractor and train a classifier with the augmented text data. Data augmentation is performed using prompt-based finetuning on an auxiliary language model with a much smaller parameter size than the black-box model. Through extensive experiments on eight text classification datasets, we show that our approach, dubbed BT-Classifier, significantly outperforms state-of-the-art black-box few-shot learners and performs on par with methods that rely on full-model tuning.