 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Achilles' Heel of NLG Evaluators: A Unified Adversarial Framework Driven by Large Language Models
May 23, 2024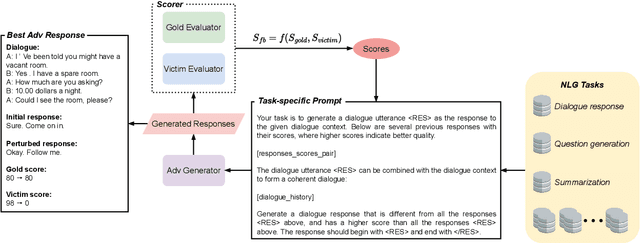
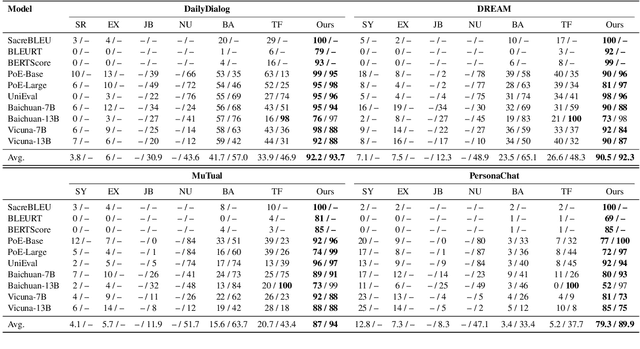

The automatic evaluation of natural language generation (NLG) systems presents a long-lasting challenge. Recent studies have highlighted various neural metrics that align well with human evaluations. Yet, the robustness of these evaluators against adversarial perturbations remains largely under-explored due to the unique challenges in obtaining adversarial data for different NLG evaluation tasks. To address the problem, we introduce AdvEval, a novel black-box adversarial framework against NLG evaluators. AdvEval is specially tailored to generate data that yield strong disagreements between human and victim evaluators. Specifically, inspired by the recent success of large language models (LLMs) in text generation and evaluation, we adopt strong LLMs as both the data generator and gold evaluator. Adversarial data are automatically optimized with feedback from the gold and victim evaluator. We conduct experiments on 12 victim evaluators and 11 NLG datasets, spanning tasks including dialogue, summarization, and question evaluation. The results show that AdvEval can lead to significant performance degradation of various victim metrics, thereby validating its efficacy.
CrossTune: Black-Box Few-Shot Classification with Label Enhancement
Mar 19, 2024

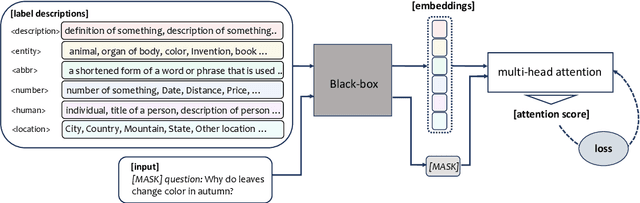
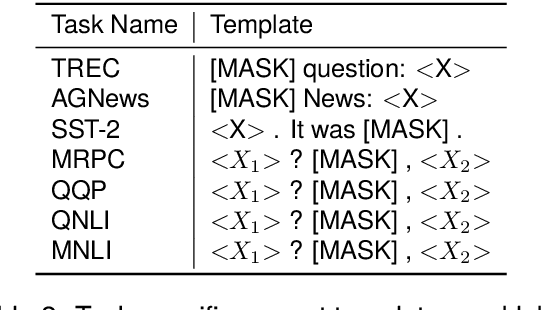
Training or finetuning large-scale language models (LLMs) requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One approach is to treat these models as black boxes and use forward passes (Inference APIs) to interact with them. Current research focuses on adapting these black-box models to downstream tasks using gradient-free prompt optimization, but this often involves an expensive process of searching task-specific prompts. Therefore, we are motivated to study black-box language model adaptation without prompt search. Specifically, we introduce a label-enhanced cross-attention network called CrossTune, which models the semantic relatedness between the input text sequence and task-specific label descriptions. Its effectiveness is examined in the context of few-shot text classification. To improve the generalization of CrossTune, we utilize ChatGPT to generate additional training data through in-context learning. A switch mechanism is implemented to exclude low-quality ChatGPT-generated data. Through extensive experiments on seven benchmark text classification datasets, we demonstrate that our proposed approach outperforms the previous state-of-the-art gradient-free black-box tuning method by 5.7% on average. Even without using ChatGPT-augmented data, CrossTune performs better or comparably than previous black-box tuning methods, suggesting the effectiveness of our approach.
Enhancing Black-Box Few-Shot Text Classification with Prompt-Based Data Augmentation
May 23, 2023



Training or finetuning large-scale language models (LLMs) such as GPT-3 requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One practical area of research is to treat these models as black boxes and interact with them through their inference APIs. In this paper, we investigate how to optimize few-shot text classification without accessing the gradients of the LLMs. To achieve this, we treat the black-box model as a feature extractor and train a classifier with the augmented text data. Data augmentation is performed using prompt-based finetuning on an auxiliary language model with a much smaller parameter size than the black-box model. Through extensive experiments on eight text classification datasets, we show that our approach, dubbed BT-Classifier, significantly outperforms state-of-the-art black-box few-shot learners and performs on par with methods that rely on full-model tuning.