 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossTune: Black-Box Few-Shot Classification with Label Enhancement
Paper and Code
Mar 19, 2024

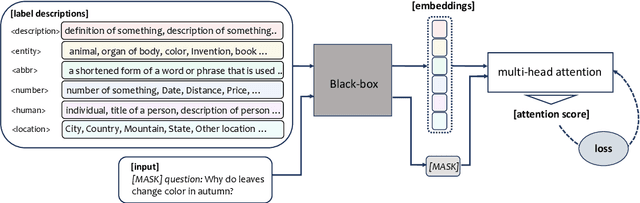
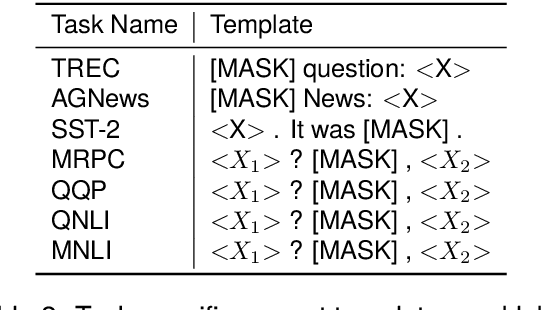
Training or finetuning large-scale language models (LLMs) requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One approach is to treat these models as black boxes and use forward passes (Inference APIs) to interact with them. Current research focuses on adapting these black-box models to downstream tasks using gradient-free prompt optimization, but this often involves an expensive process of searching task-specific prompts. Therefore, we are motivated to study black-box language model adaptation without prompt search. Specifically, we introduce a label-enhanced cross-attention network called CrossTune, which models the semantic relatedness between the input text sequence and task-specific label descriptions. Its effectiveness is examined in the context of few-shot text classification. To improve the generalization of CrossTune, we utilize ChatGPT to generate additional training data through in-context learning. A switch mechanism is implemented to exclude low-quality ChatGPT-generated data. Through extensive experiments on seven benchmark text classification datasets, we demonstrate that our proposed approach outperforms the previous state-of-the-art gradient-free black-box tuning method by 5.7% on average. Even without using ChatGPT-augmented data, CrossTune performs better or comparably than previous black-box tuning methods, suggesting the effectiveness of our approach.