 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLR-voyance: Reinforcing Open-Ended Reasoning for Inpatient Clinical Decision Support with Outcome-Aware Rubrics
May 10, 2026Inpatient clinical reasoning is a sequential decision under partial observability: the clinician sees the admission so far and must choose the next action whose downstream consequences are not yet visible. Existing clinical-LLM evaluations and RL rewards signals collapse this into closed-form retrieval, clinical journey leakage, or unanchored LLM-as-judge scoring. We introduce CLR-voyance, a framework that reformulates inpatient reasoning as a Partially Observable Markov Decision Process (POMDP) and supervises it with rewards that are simultaneously outcome-grounded and clinician-validated. We instantiate the formulation as CLR-POMDP, which partitions successful patient journeys into a policy-visible past and an oracle-only future. Using the past information, an oracle LLM generates a case-specific query-answer pair, and the first adaptive rubric for clinical reasoning which is verifiable in the future of the patient journey. These rubrics are used for both post-training and evaluation of models for inpatient clinical reasoning. We post-train Qwen3-8B and MedGemma-4B with GRPO followed by model merging, yielding state-of-the-art inpatient clinical reasoning while retaining generalist capabilities. CLR-voyance-8B achieves 84.91% on CLR-POMDP, ahead of frontier medical reasoning models like GPT-5 (77.83%) and MedGemma-27B (66.66%) and has comparable or better performance on existing medical benchmarks. To ensure a clinically meaningful setting, we conduct a large-scale clinician alignment study, where physicians curate per-case rubrics, grade candidate responses, and provide blinded pairwise preferences of model reasoning. This study provides insights on clinical LLM-as-a-judge and clinical preference-model selection, which can inform the community at large. CLR-voyance has been deployed for 6+ months at a partner public hospital, drafting thousands of reasoning-heavy inpatient notes.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
HalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
Apr 21, 2026Large Audio-Language Models (LALMs) have recently achieved strong performance across various audio-centric tasks. However, hallucination, where models generate responses that are semantically incorrect or acoustically unsupported, remains largely underexplored in the audio domain. Existing hallucination benchmarks mainly focus on text or vision, while the few audio-oriented studies are limited in scale, modality coverage, and diagnostic depth. We therefore introduce HalluAudio, the first large-scale benchmark for evaluating hallucinations across speech, environmental sound, and music. HalluAudio comprises over 5K human-verified QA pairs and spans diverse task types, including binary judgments, multi-choice reasoning, attribute verification, and open-ended QA. To systematically induce hallucinations, we design adversarial prompts and mixed-audio conditions. Beyond accuracy, our evaluation protocol measures hallucination rate, yes/no bias, error-type analysis, and refusal rate, enabling a fine-grained analysis of LALM failure modes. We benchmark a broad range of open-source and proprietary models, providing the first large-scale comparison across speech, sound, and music. Our results reveal significant deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding, underscoring the need for reliable and robust LALMs.
Test-time Scaling over Perception: Resolving the Grounding Paradox in Thinking with Images
Apr 13, 2026Recent multimodal large language models (MLLMs) have begun to support Thinking with Images by invoking visual tools such as zooming and cropping during inference. Yet these systems remain brittle in fine-grained visual reasoning because they must decide where to look before they have access to the evidence needed to make that decision correctly. We identify this circular dependency as the Grounding Paradox. To address it, we propose Test-Time Scaling over Perception (TTSP), a framework that treats perception itself as a scalable inference process. TTSP generates multiple exploratory perception traces, filters unreliable traces using entropy-based confidence estimation, distills validated observations into structured knowledge, and iteratively refines subsequent exploration toward unresolved uncertainty. Extensive experiments on high-resolution and general multimodal reasoning benchmarks show that TTSP consistently outperforms strong baselines across backbone sizes, while also exhibiting favorable scalability and token efficiency. Our results suggest that scaling perception at test time is a promising direction for robust multimodal reasoning under perceptual uncertainty.
SubFLOT: Submodel Extraction for Efficient and Personalized Federated Learning via Optimal Transport
Apr 08, 2026Federated Learning (FL) enables collaborative model training while preserving data privacy, but its practical deployment is hampered by system and statistical heterogeneity. While federated network pruning offers a path to mitigate these issues, existing methods face a critical dilemma: server-side pruning lacks personalization, whereas client-side pruning is computationally prohibitive for resource-constrained devices. Furthermore, the pruning process itself induces significant parametric divergence among heterogeneous submodels, destabilizing training and hindering global convergence. To address these challenges, we propose SubFLOT, a novel framework for server-side personalized federated pruning. SubFLOT introduces an Optimal Transport-enhanced Pruning (OTP) module that treats historical client models as proxies for local data distributions, formulating the pruning task as a Wasserstein distance minimization problem to generate customized submodels without accessing raw data. Concurrently, to counteract parametric divergence, our Scaling-based Adaptive Regularization (SAR) module adaptively penalizes a submodel's deviation from the global model, with the penalty's strength scaled by the client's pruning rate. Comprehensive experiments demonstrate that SubFLOT consistently and substantially outperforms state-of-the-art methods, underscoring its potential for deploying efficient and personalized models on resource-constrained edge devices.
Near-Field Channel Estimation for mmWave/THz Communications with Extremely Large-Scale UPAs
Mar 15, 2026Extremely large antenna arrays (ELAAs) are widely adopted in mmWave/THz communications to compensate for the severe path loss, wherein the channel estimation remains a significant challenge since the Rayleigh distance of ELAAs stretches to tens or even hundreds of meters and the near-field channel model should be considered. Existing polar-domain based methods and block-sparse based methods are originally devised for Uniform Linear Arrays (ULAs) near-field channel estimation. The polar-domain based method can be applied to Uniform Planar Arrays (UPAs), but it behaves plain since it ignores the specific sparsity structure of the UPA near-field channels. Meanwhile, the block-sparse based method cannot be extended to the UPA scenarios directly. To address these issues, we first reformulate the original UPA near-field channel as an outer product of two ULA near-field channels and we construct a modified two-dimensional DFT (2D-DFT) dictionary for it. With the proposed dictionary, we further prove that the UPA near-field channel admits a 2D block-sparse structure. Leveraging this specific sparse structure, we solve the channel estimation problem with the 2D Pattern-Coupled Sparse Bayesian Learning (2D-PCSBL) algorithm. Simulation results show that the proposed approach outperforms conventional existing methods while maintaining a comparable computational complexity.
MORE: Multi-Objective Adversarial Attacks on Speech Recognition
Jan 05, 2026The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy degradation under adversarial attacks, robustness with respect to efficiency remains largely unexplored. This narrow focus provides only a partial understanding of ASR model vulnerabilities. To address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. We introduce MORE, a multi-objective repetitive doubling encouragement attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion-anchoring mechanism. Specifically, we reformulate multi-objective adversarial optimization into a hierarchical framework that sequentially achieves the dual objectives. To further amplify effectiveness, we propose a novel repetitive encouragement doubling objective (REDO) that induces duplicative text generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, triggered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effectiveness in multi-objective adversarial attack.
CaFe-TeleVision: A Coarse-to-Fine Teleoperation System with Immersive Situated Visualization for Enhanced Ergonomics
Dec 17, 2025Teleoperation presents a promising paradigm for remote control and robot proprioceptive data collection. Despite recent progress, current teleoperation systems still suffer from limitations in efficiency and ergonomics, particularly in challenging scenarios. In this paper, we propose CaFe-TeleVision, a coarse-to-fine teleoperation system with immersive situated visualization for enhanced ergonomics. At its core, a coarse-to-fine control mechanism is proposed in the retargeting module to bridge workspace disparities, jointly optimizing efficiency and physical ergonomics. To stream immersive feedback with adequate visual cues for human vision systems, an on-demand situated visualization technique is integrated in the perception module, which reduces the cognitive load for multi-view processing. The system is built on a humanoid collaborative robot and validated with six challenging bimanual manipulation tasks. User study among 24 participants confirms that CaFe-TeleVision enhances ergonomics with statistical significance, indicating a lower task load and a higher user acceptance during teleoperation. Quantitative results also validate the superior performance of our system across six tasks, surpassing comparative methods by up to 28.89% in success rate and accelerating by 26.81% in completion time. Project webpage: https://clover-cuhk.github.io/cafe_television/
Interactive Motion Planning for Human-Robot Collaboration Based on Human-Centric Configuration Space Ergonomic Field
Dec 16, 2025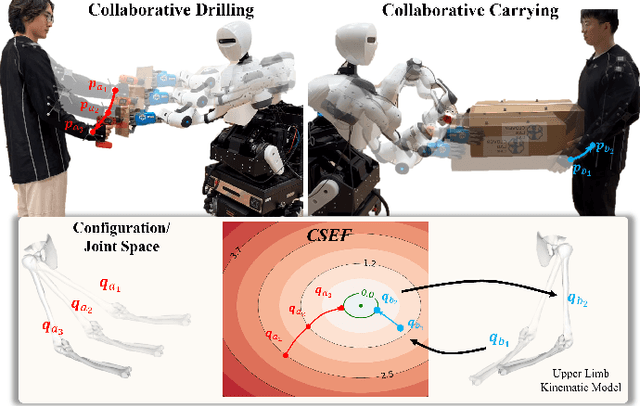
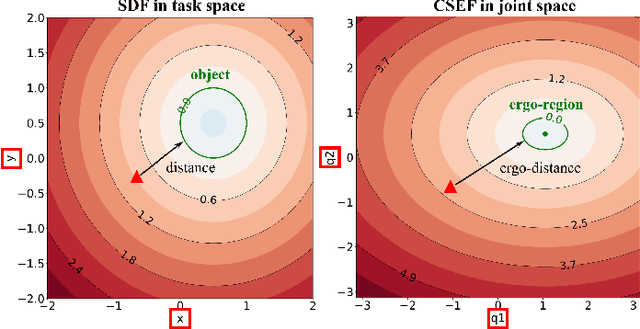
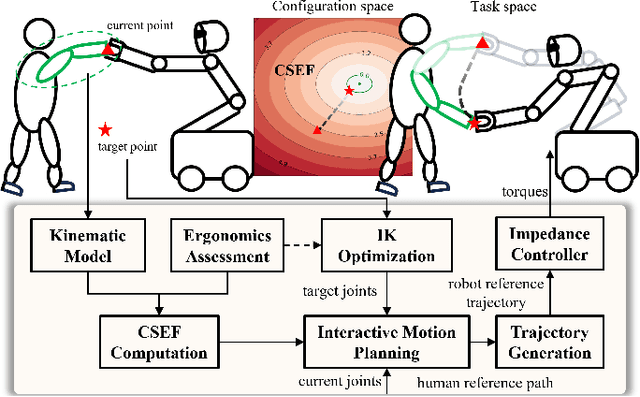
Industrial human-robot collaboration requires motion planning that is collision-free, responsive, and ergonomically safe to reduce fatigue and musculoskeletal risk. We propose the Configuration Space Ergonomic Field (CSEF), a continuous and differentiable field over the human joint space that quantifies ergonomic quality and provides gradients for real-time ergonomics-aware planning. An efficient algorithm constructs CSEF from established metrics with joint-wise weighting and task conditioning, and we integrate it into a gradient-based planner compatible with impedance-controlled robots. In a 2-DoF benchmark, CSEF-based planning achieves higher success rates, lower ergonomic cost, and faster computation than a task-space ergonomic planner. Hardware experiments with a dual-arm robot in unimanual guidance, collaborative drilling, and bimanual cocarrying show faster ergonomic cost reduction, closer tracking to optimized joint targets, and lower muscle activation than a point-to-point baseline. CSEF-based planning method reduces average ergonomic scores by up to 10.31% for collaborative drilling tasks and 5.60% for bimanual co-carrying tasks while decreasing activation in key muscle groups, indicating practical benefits for real-world deployment.
Integrating Ergonomics and Manipulability for Upper Limb Postural Optimization in Bimanual Human-Robot Collaboration
Nov 06, 2025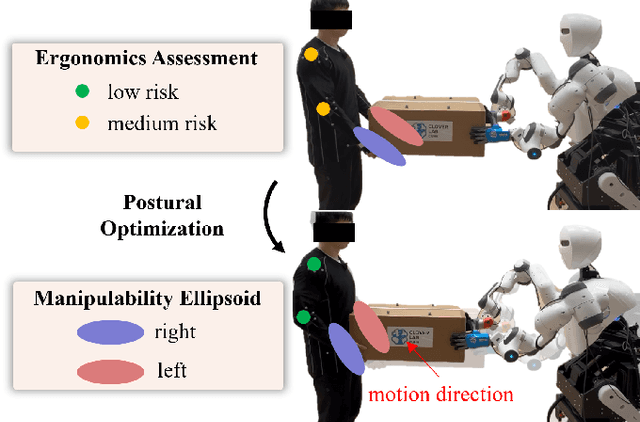

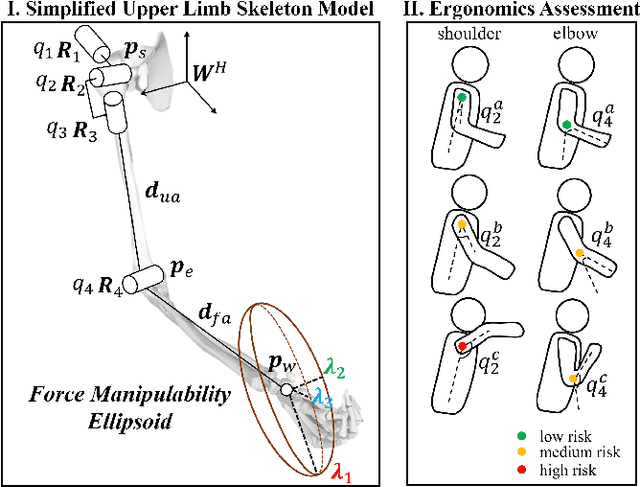
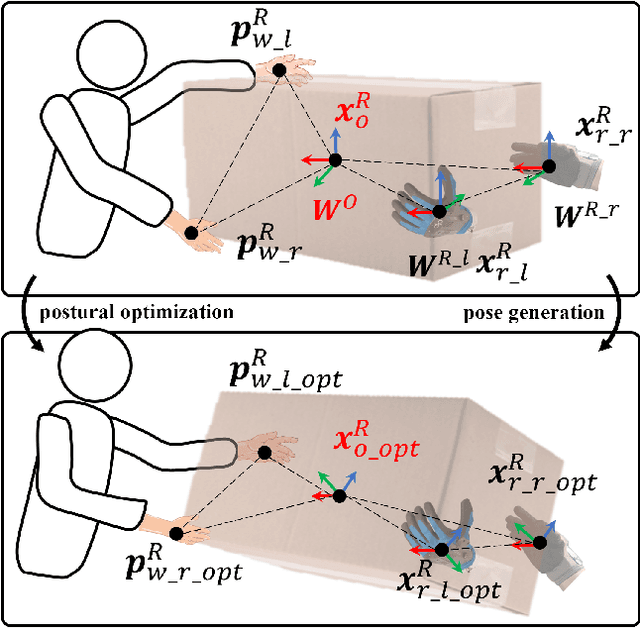
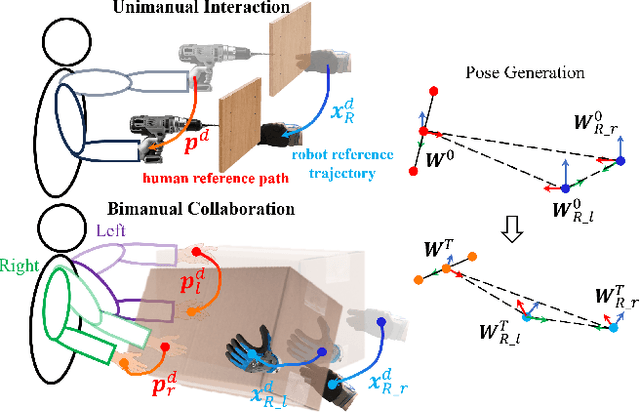
This paper introduces an upper limb postural optimization method for enhancing physical ergonomics and force manipulability during bimanual human-robot co-carrying tasks. Existing research typically emphasizes human safety or manipulative efficiency, whereas our proposed method uniquely integrates both aspects to strengthen collaboration across diverse conditions (e.g., different grasping postures of humans, and different shapes of objects). Specifically, the joint angles of a simplified human skeleton model are optimized by minimizing the cost function to prioritize safety and manipulative capability. To guide humans towards the optimized posture, the reference end-effector poses of the robot are generated through a transformation module. A bimanual model predictive impedance controller (MPIC) is proposed for our human-like robot, CURI, to recalibrate the end effector poses through planned trajectories. The proposed method has been validated through various subjects and objects during human-human collaboration (HHC) and human-robot collaboration (HRC). The experimental results demonstrate significant improvement in muscle conditions by comparing the activation of target muscles before and after optimization.