 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt as You Say: Online Interactive Bimanual Skill Adaptation via Human Language Feedback
Mar 27, 2026Developing general-purpose robots capable of autonomously operating in human living environments requires the ability to adapt to continuously evolving task conditions. However, adapting high-dimensional coordinated bimanual skills to novel task variations at deployment remains a fundamental challenge. In this work, we present BiSAIL (Bimanual Skill Adaptation via Interactive Language), a novel framework that enables zero-shot online adaptation of offline-learned bimanual skills through interactive language feedback. The key idea of BiSAIL is to adopt a hierarchical reason-then-modulate paradigm, which first infers generalized adaptation objectives from multimodal task variations, and then adapts bimanual motions via diffusion modulation to achieve the inferred objectives. Extensive real-robot experiments across six bimanual tasks and two dual-arm platforms demonstrate that BiSAIL significantly outperforms existing methods in human-in-the-loop adaptability, task generalization and cross-embodiment scalability. This work enables the development of adaptive bimanual assistants that can be flexibly customized by non-expert users via intuitive verbal corrections. Experimental videos and code are available at https://rip4kobe.github.io/BiSAIL/.
SEED-SET: Scalable Evolving Experimental Design for System-level Ethical Testing
Mar 02, 2026As autonomous systems such as drones, become increasingly deployed in high-stakes, human-centric domains, it is critical to evaluate the ethical alignment since failure to do so imposes imminent danger to human lives, and long term bias in decision-making. Automated ethical benchmarking of these systems is understudied due to the lack of ubiquitous, well-defined metrics for evaluation, and stakeholder-specific subjectivity, which cannot be modeled analytically. To address these challenges, we propose SEED-SET, a Bayesian experimental design framework that incorporates domain-specific objective evaluations, and subjective value judgments from stakeholders. SEED-SET models both evaluation types separately with hierarchical Gaussian Processes, and uses a novel acquisition strategy to propose interesting test candidates based on learnt qualitative preferences and objectives that align with the stakeholder preferences. We validate our approach for ethical benchmarking of autonomous agents on two applications and find our method to perform the best. Our method provides an interpretable and efficient trade-off between exploration and exploitation, by generating up to $2\times$ optimal test candidates compared to baselines, with $1.25\times$ improvement in coverage of high dimensional search spaces.
Disentangling perception and reasoning for improving data efficiency in learning cloth manipulation without demonstrations
Jan 29, 2026Cloth manipulation is a ubiquitous task in everyday life, but it remains an open challenge for robotics. The difficulties in developing cloth manipulation policies are attributed to the high-dimensional state space, complex dynamics, and high propensity to self-occlusion exhibited by fabrics. As analytical methods have not been able to provide robust and general manipulation policies, reinforcement learning (RL) is considered a promising approach to these problems. However, to address the large state space and complex dynamics, data-based methods usually rely on large models and long training times. The resulting computational cost significantly hampers the development and adoption of these methods. Additionally, due to the challenge of robust state estimation, garment manipulation policies often adopt an end-to-end learning approach with workspace images as input. While this approach enables a conceptually straightforward sim-to-real transfer via real-world fine-tuning, it also incurs a significant computational cost by training agents on a highly lossy representation of the environment state. This paper questions this common design choice by exploring an efficient and modular approach to RL for cloth manipulation. We show that, through careful design choices, model size and training time can be significantly reduced when learning in simulation. Furthermore, we demonstrate how the resulting simulation-trained model can be transferred to the real world. We evaluate our approach on the SoftGym benchmark and achieve significant performance improvements over available baselines on our task, while using a substantially smaller model.
Decoding Speech Envelopes from Electroencephalogram with a Contrastive Pearson Correlation Coefficient Loss
Jan 29, 2026Recent advances in reconstructing speech envelopes from Electroencephalogram (EEG) signals have enabled continuous auditory attention decoding (AAD) in multi-speaker environments. Most Deep Neural Network (DNN)-based envelope reconstruction models are trained to maximize the Pearson correlation coefficients (PCC) between the attended envelope and the reconstructed envelope (attended PCC). While the difference between the attended PCC and the unattended PCC plays an essential role in auditory attention decoding, existing methods often focus on maximizing the attended PCC. We therefore propose a contrastive PCC loss which represents the difference between the attended PCC and the unattended PCC. The proposed approach is evaluated on three public EEG AAD datasets using four DNN architectures. Across many settings, the proposed objective improves envelope separability and AAD accuracy, while also revealing dataset- and architecture-dependent failure cases.
CaFe-TeleVision: A Coarse-to-Fine Teleoperation System with Immersive Situated Visualization for Enhanced Ergonomics
Dec 17, 2025Teleoperation presents a promising paradigm for remote control and robot proprioceptive data collection. Despite recent progress, current teleoperation systems still suffer from limitations in efficiency and ergonomics, particularly in challenging scenarios. In this paper, we propose CaFe-TeleVision, a coarse-to-fine teleoperation system with immersive situated visualization for enhanced ergonomics. At its core, a coarse-to-fine control mechanism is proposed in the retargeting module to bridge workspace disparities, jointly optimizing efficiency and physical ergonomics. To stream immersive feedback with adequate visual cues for human vision systems, an on-demand situated visualization technique is integrated in the perception module, which reduces the cognitive load for multi-view processing. The system is built on a humanoid collaborative robot and validated with six challenging bimanual manipulation tasks. User study among 24 participants confirms that CaFe-TeleVision enhances ergonomics with statistical significance, indicating a lower task load and a higher user acceptance during teleoperation. Quantitative results also validate the superior performance of our system across six tasks, surpassing comparative methods by up to 28.89% in success rate and accelerating by 26.81% in completion time. Project webpage: https://clover-cuhk.github.io/cafe_television/
Interactive Motion Planning for Human-Robot Collaboration Based on Human-Centric Configuration Space Ergonomic Field
Dec 16, 2025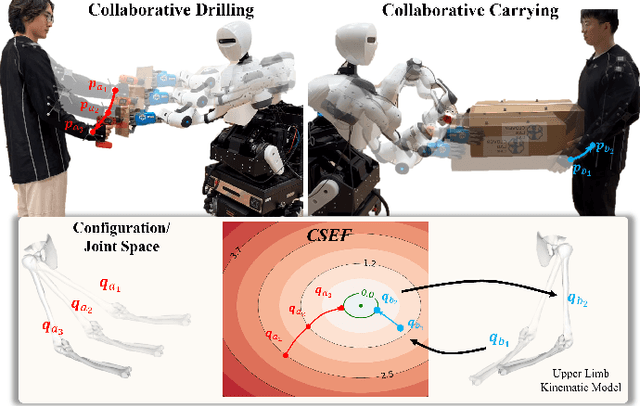
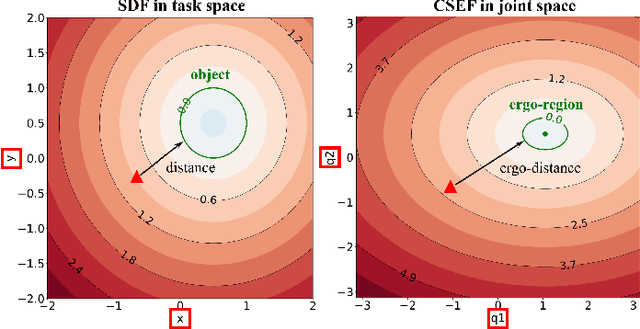
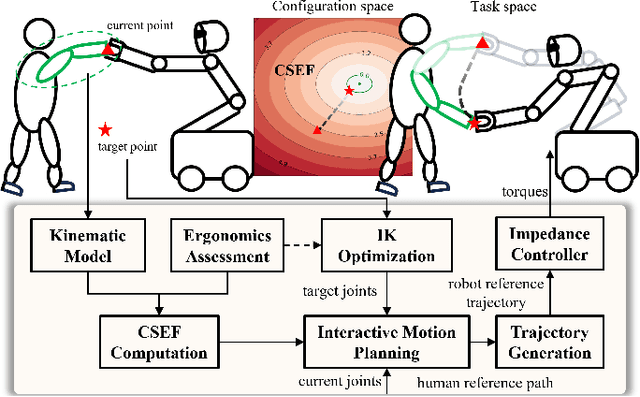
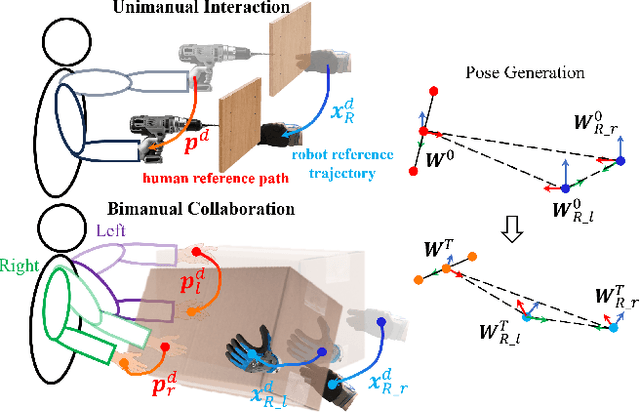
Industrial human-robot collaboration requires motion planning that is collision-free, responsive, and ergonomically safe to reduce fatigue and musculoskeletal risk. We propose the Configuration Space Ergonomic Field (CSEF), a continuous and differentiable field over the human joint space that quantifies ergonomic quality and provides gradients for real-time ergonomics-aware planning. An efficient algorithm constructs CSEF from established metrics with joint-wise weighting and task conditioning, and we integrate it into a gradient-based planner compatible with impedance-controlled robots. In a 2-DoF benchmark, CSEF-based planning achieves higher success rates, lower ergonomic cost, and faster computation than a task-space ergonomic planner. Hardware experiments with a dual-arm robot in unimanual guidance, collaborative drilling, and bimanual cocarrying show faster ergonomic cost reduction, closer tracking to optimized joint targets, and lower muscle activation than a point-to-point baseline. CSEF-based planning method reduces average ergonomic scores by up to 10.31% for collaborative drilling tasks and 5.60% for bimanual co-carrying tasks while decreasing activation in key muscle groups, indicating practical benefits for real-world deployment.
Towards Deploying VLA without Fine-Tuning: Plug-and-Play Inference-Time VLA Policy Steering via Embodied Evolutionary Diffusion
Nov 18, 2025Vision-Language-Action (VLA) models have demonstrated significant potential in real-world robotic manipulation. However, pre-trained VLA policies still suffer from substantial performance degradation during downstream deployment. Although fine-tuning can mitigate this issue, its reliance on costly demonstration collection and intensive computation makes it impractical in real-world settings. In this work, we introduce VLA-Pilot, a plug-and-play inference-time policy steering method for zero-shot deployment of pre-trained VLA without any additional fine-tuning or data collection. We evaluate VLA-Pilot on six real-world downstream manipulation tasks across two distinct robotic embodiments, encompassing both in-distribution and out-of-distribution scenarios. Experimental results demonstrate that VLA-Pilot substantially boosts the success rates of off-the-shelf pre-trained VLA policies, enabling robust zero-shot generalization to diverse tasks and embodiments. Experimental videos and code are available at: https://rip4kobe.github.io/vla-pilot/.
Integrating Ergonomics and Manipulability for Upper Limb Postural Optimization in Bimanual Human-Robot Collaboration
Nov 06, 2025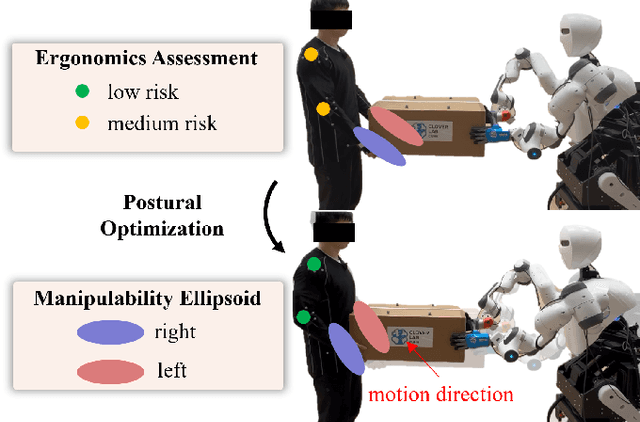

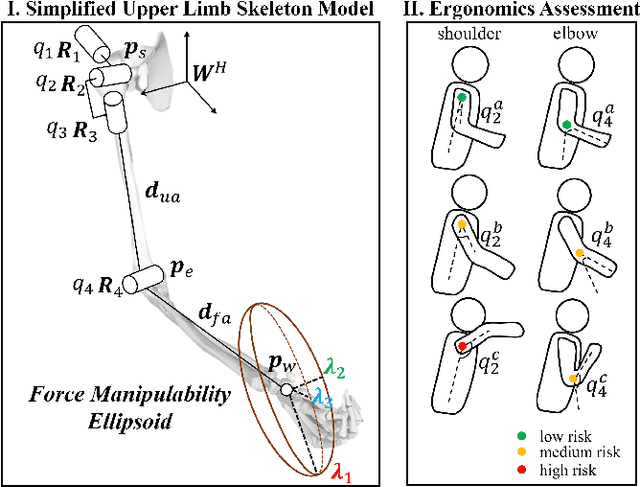
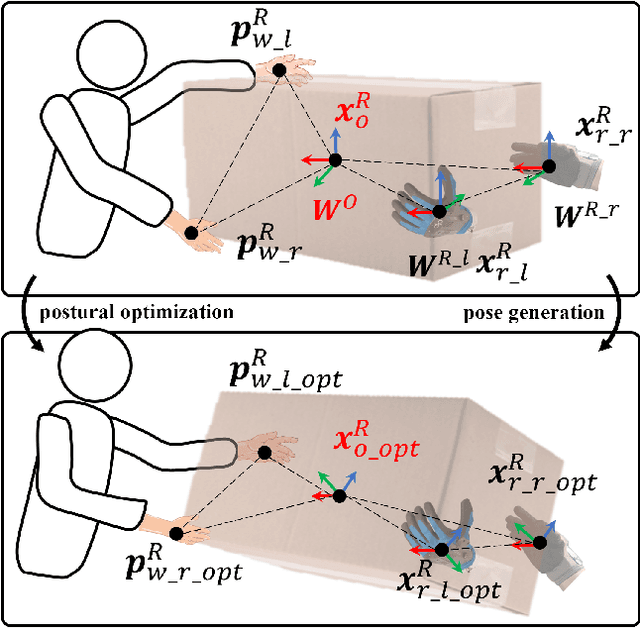
This paper introduces an upper limb postural optimization method for enhancing physical ergonomics and force manipulability during bimanual human-robot co-carrying tasks. Existing research typically emphasizes human safety or manipulative efficiency, whereas our proposed method uniquely integrates both aspects to strengthen collaboration across diverse conditions (e.g., different grasping postures of humans, and different shapes of objects). Specifically, the joint angles of a simplified human skeleton model are optimized by minimizing the cost function to prioritize safety and manipulative capability. To guide humans towards the optimized posture, the reference end-effector poses of the robot are generated through a transformation module. A bimanual model predictive impedance controller (MPIC) is proposed for our human-like robot, CURI, to recalibrate the end effector poses through planned trajectories. The proposed method has been validated through various subjects and objects during human-human collaboration (HHC) and human-robot collaboration (HRC). The experimental results demonstrate significant improvement in muscle conditions by comparing the activation of target muscles before and after optimization.
ManiDP: Manipulability-Aware Diffusion Policy for Posture-Dependent Bimanual Manipulation
Oct 27, 2025Recent work has demonstrated the potential of diffusion models in robot bimanual skill learning. However, existing methods ignore the learning of posture-dependent task features, which are crucial for adapting dual-arm configurations to meet specific force and velocity requirements in dexterous bimanual manipulation. To address this limitation, we propose Manipulability-Aware Diffusion Policy (ManiDP), a novel imitation learning method that not only generates plausible bimanual trajectories, but also optimizes dual-arm configurations to better satisfy posture-dependent task requirements. ManiDP achieves this by extracting bimanual manipulability from expert demonstrations and encoding the encapsulated posture features using Riemannian-based probabilistic models. These encoded posture features are then incorporated into a conditional diffusion process to guide the generation of task-compatible bimanual motion sequences. We evaluate ManiDP on six real-world bimanual tasks, where the experimental results demonstrate a 39.33$\%$ increase in average manipulation success rate and a 0.45 improvement in task compatibility compared to baseline methods. This work highlights the importance of integrating posture-relevant robotic priors into bimanual skill diffusion to enable human-like adaptability and dexterity.
Auditory Attention Decoding from Ear-EEG Signals: A Dataset with Dynamic Attention Switching and Rigorous Cross-Validation
Oct 22, 2025Recent promising results in auditory attention decoding (AAD) using scalp electroencephalography (EEG) have motivated the exploration of cEEGrid, a flexible and portable ear-EEG system. While prior cEEGrid-based studies have confirmed the feasibility of AAD, they often neglect the dynamic nature of attentional states in real-world contexts. To address this gap, a novel cEEGrid dataset featuring three concurrent speakers distributed across three of five distinct spatial locations is introduced. The novel dataset is designed to probe attentional tracking and switching in realistic scenarios. Nested leave-one-out validation-an approach more rigorous than conventional single-loop leave-one-out validation-is employed to reduce biases stemming from EEG's intricate temporal dynamics. Four rule-based models are evaluated: Wiener filter (WF), canonical component analysis (CCA), common spatial pattern (CSP) and Riemannian Geometry-based classifier (RGC). With a 30-second decision window, WF and CCA models achieve decoding accuracies of 41.5% and 41.4%, respectively, while CSP and RGC models yield 37.8% and 37.6% accuracies using a 10-second window. Notably, both WF and CCA successfully track attentional state switches across all experimental tasks. Additionally, higher decoding accuracies are observed for electrodes positioned at the upper cEEGrid layout and near the listener's right ear. These findings underscore the utility of dynamic, ecologically valid paradigms and rigorous validation in advancing AAD research with cEEGrid.