 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure Identification in Imitation Learning Via Statistical and Semantic Filtering
Apr 15, 2026Imitation learning (IL) policies in robotics deliver strong performance in controlled settings but remain brittle in real-world deployments: rare events such as hardware faults, defective parts, unexpected human actions, or any state that lies outside the training distribution can lead to failed executions. Vision-based Anomaly Detection (AD) methods emerged as an appropriate solution to detect these anomalous failure states but do not distinguish failures from benign deviations. We introduce FIDeL (Failure Identification in Demonstration Learning), a policy-independent failure detection module. Leveraging recent AD methods, FIDeL builds a compact representation of nominal demonstrations and aligns incoming observations via optimal transport matching to produce anomaly scores and heatmaps. Spatio-temporal thresholds are derived with an extension of conformal prediction, and a Vision-Language Model (VLM) performs semantic filtering to discriminate benign anomalies from genuine failures. We also introduce BotFails, a multimodal dataset of real-world tasks for failure detection in robotics. FIDeL consistently outperforms state-of-the-art baselines, yielding +5.30% percent AUROC in anomaly detection and +17.38% percent failure-detection accuracy on BotFails compared to existing methods.
Diverging Flows: Detecting Extrapolations in Conditional Generation
Feb 13, 2026The ability of Flow Matching (FM) to model complex conditional distributions has established it as the state-of-the-art for prediction tasks (e.g., robotics, weather forecasting). However, deployment in safety-critical settings is hindered by a critical extrapolation hazard: driven by smoothness biases, flow models yield plausible outputs even for off-manifold conditions, resulting in silent failures indistinguishable from valid predictions. In this work, we introduce Diverging Flows, a novel approach that enables a single model to simultaneously perform conditional generation and native extrapolation detection by structurally enforcing inefficient transport for off-manifold inputs. We evaluate our method on synthetic manifolds, cross-domain style transfer, and weather temperature forecasting, demonstrating that it achieves effective detection of extrapolations without compromising predictive fidelity or inference latency. These results establish Diverging Flows as a robust solution for trustworthy flow models, paving the way for reliable deployment in domains such as medicine, robotics, and climate science.
Extremum Flow Matching for Offline Goal Conditioned Reinforcement Learning
May 26, 2025Imitation learning is a promising approach for enabling generalist capabilities in humanoid robots, but its scaling is fundamentally constrained by the scarcity of high-quality expert demonstrations. This limitation can be mitigated by leveraging suboptimal, open-ended play data, often easier to collect and offering greater diversity. This work builds upon recent advances in generative modeling, specifically Flow Matching, an alternative to Diffusion models. We introduce a method for estimating the extremum of the learned distribution by leveraging the unique properties of Flow Matching, namely, deterministic transport and support for arbitrary source distributions. We apply this method to develop several goal-conditioned imitation and reinforcement learning algorithms based on Flow Matching, where policies are conditioned on both current and goal observations. We explore and compare different architectural configurations by combining core components, such as critic, planner, actor, or world model, in various ways. We evaluated our agents on the OGBench benchmark and analyzed how different demonstration behaviors during data collection affect performance in a 2D non-prehensile pushing task. Furthermore, we validated our approach on real hardware by deploying it on the Talos humanoid robot to perform complex manipulation tasks based on high-dimensional image observations, featuring a sequence of pick-and-place and articulated object manipulation in a realistic kitchen environment. Experimental videos and code are available at: https://hucebot.github.io/extremum_flow_matching_website/
From Vocal Instructions to Household Tasks: The Inria Tiago++ in the euROBIN Service Robots Coopetition
Dec 20, 2024This paper describes the Inria team's integrated robotics system used in the 1st euROBIN coopetition, during which service robots performed voice-activated household tasks in a kitchen setting.The team developed a modified Tiago++ platform that leverages a whole-body control stack for autonomous and teleoperated modes, and an LLM-based pipeline for instruction understanding and task planning. The key contributions (opens-sourced) are the integration of these components and the design of custom teleoperation devices, addressing practical challenges in the deployment of service robots.
Flying in air ducts
Oct 10, 2024Air ducts are integral to modern buildings but are challenging to access for inspection. Small quadrotor drones offer a potential solution, as they can navigate both horizontal and vertical sections and smoothly fly over debris. However, hovering inside air ducts is problematic due to the airflow generated by the rotors, which recirculates inside the duct and destabilizes the drone, whereas hovering is a key feature for many inspection missions. In this article, we map the aerodynamic forces that affect a hovering drone in a duct using a robotic setup and a force/torque sensor. Based on the collected aerodynamic data, we identify a recommended position for stable flight, which corresponds to the bottom third for a circular duct. We then develop a neural network-based positioning system that leverages low-cost time-of-flight sensors. By combining these aerodynamic insights and the data-driven positioning system, we show that a small quadrotor drone (here, 180 mm) can hover and fly inside small air ducts, starting with a diameter of 350 mm. These results open a new and promising application domain for drones.
Words2Contact: Identifying Support Contacts from Verbal Instructions Using Foundation Models
Jul 19, 2024



This paper presents Words2Contact, a language-guided multi-contact placement pipeline leveraging large language models and vision language models. Our method is a key component for language-assisted teleoperation and human-robot cooperation, where human operators can instruct the robots where to place their support contacts before whole-body reaching or manipulation using natural language. Words2Contact transforms the verbal instructions of a human operator into contact placement predictions; it also deals with iterative corrections, until the human is satisfied with the contact location identified in the robot's field of view. We benchmark state-of-the-art LLMs and VLMs for size and performance in contact prediction. We demonstrate the effectiveness of the iterative correction process, showing that users, even naive, quickly learn how to instruct the system to obtain accurate locations. Finally, we validate Words2Contact in real-world experiments with the Talos humanoid robot, instructed by human operators to place support contacts on different locations and surfaces to avoid falling when reaching for distant objects.
Flow Matching Imitation Learning for Multi-Support Manipulation
Jul 17, 2024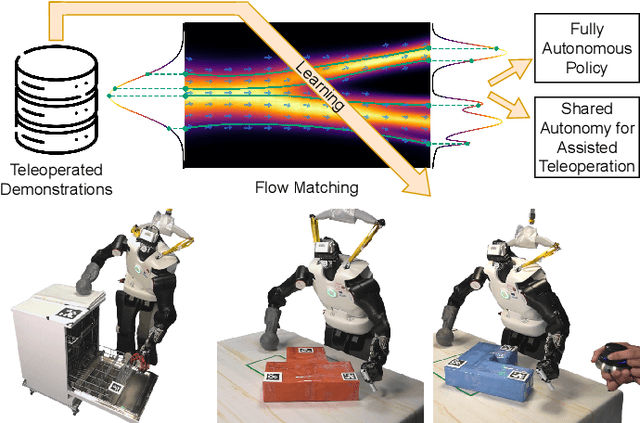

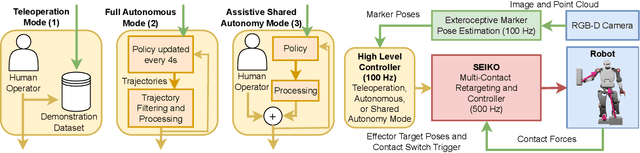
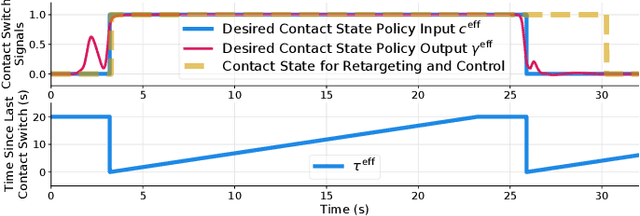
Humanoid robots could benefit from using their upper bodies for support contacts, enhancing their workspace, stability, and ability to perform contact-rich and pushing tasks. In this paper, we propose a unified approach that combines an optimization-based multi-contact whole-body controller with Flow Matching, a recently introduced method capable of generating multi-modal trajectory distributions for imitation learning. In simulation, we show that Flow Matching is more appropriate for robotics than Diffusion and traditional behavior cloning. On a real full-size humanoid robot (Talos), we demonstrate that our approach can learn a whole-body non-prehensile box-pushing task and that the robot can close dishwasher drawers by adding contacts with its free hand when needed for balance. We also introduce a shared autonomy mode for assisted teleoperation, providing automatic contact placement for tasks not covered in the demonstrations. Full experimental videos are available at: https://hucebot.github.io/flow_multisupport_website/
Parametric-Task MAP-Elites
Feb 02, 2024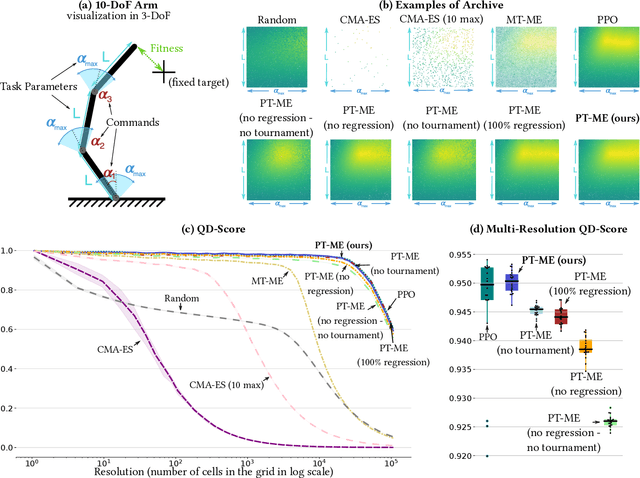
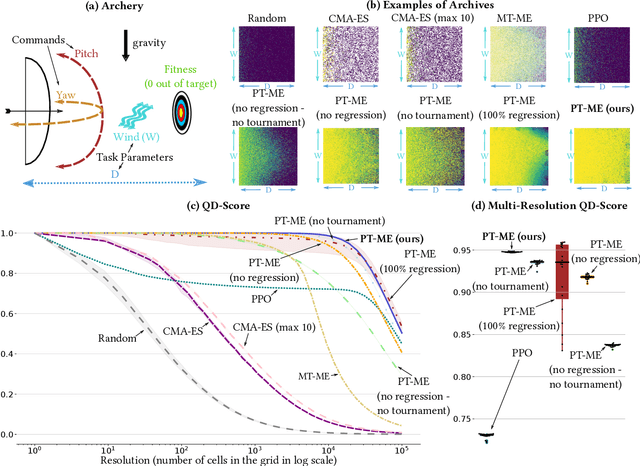
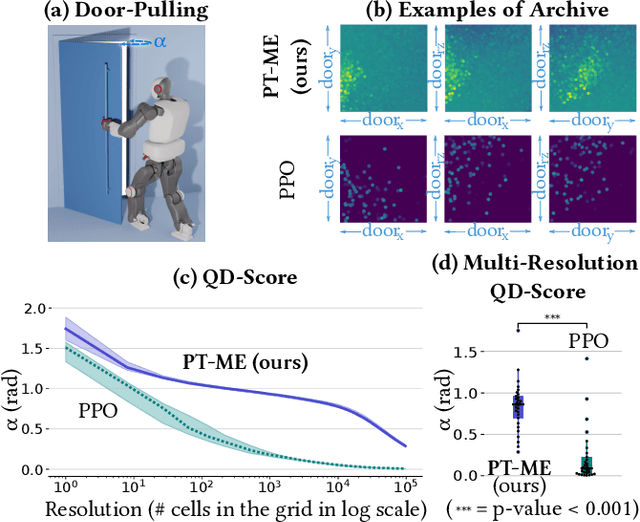
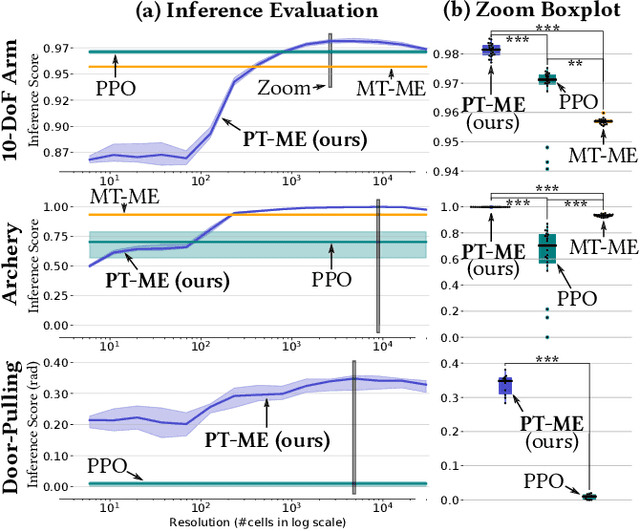
Optimizing a set of functions simultaneously by leveraging their similarity is called multi-task optimization. Current black-box multi-task algorithms only solve a finite set of tasks, even when the tasks originate from a continuous space. In this paper, we introduce Parametric-task MAP-Elites (PT-ME), a novel black-box algorithm to solve continuous multi-task optimization problems. This algorithm (1) solves a new task at each iteration, effectively covering the continuous space, and (2) exploits a new variation operator based on local linear regression. The resulting dataset of solutions makes it possible to create a function that maps any task parameter to its optimal solution. We show on two parametric-task toy problems and a more realistic and challenging robotic problem in simulation that PT-ME outperforms all baselines, including the deep reinforcement learning algorithm PPO.
Multi-Contact Whole Body Force Control for Position-Controlled Robots
Jan 16, 2024Many humanoid and multi-legged robots are controlled in positions rather than in torques, preventing direct control of contact forces, and hampering their ability to create multiple contacts to enhance their balance, such as placing a hand on a wall or a handrail. This paper introduces the SEIKO (Sequential Equilibrium Inverse Kinematic Optimization) pipeline, drawing inspiration from flexibility models used in serial elastic actuators to indirectly control contact forces on traditional position-controlled robots. SEIKO formulates whole-body retargeting from Cartesian commands and admittance control using two quadratic programs solved in real time. We validated our pipeline with experiments on the real, full-scale humanoid robot Talos in various multicontact scenarios, including pushing tasks, far-reaching tasks, stair climbing, and stepping on sloped surfaces. This work opens the possibility of stable, contact-rich behaviors while getting around many of the challenges of torque-controlled robots. Code and videos are available at https://hucebot.github.io/seiko_controller_website/ .
Feasibility Retargeting for Multi-contact Teleoperation and Physical Interaction
Aug 07, 2023



This short paper outlines two recent works on multi-contact teleoperation and the development of the SEIKO (Sequential Equilibrium Inverse Kinematic Optimization) framework. SEIKO adapts commands from the operator in real-time and ensures that the reference configuration sent to the underlying controller is feasible. Additionally, an admittance scheme is used to implement physical interaction, which is then combined with the operator's command and retargeted. SEIKO has been applied in simulations on various robots, including humanoid and quadruped robots designed for loco-manipulation. Furthermore, SEIKO has been tested on real hardware for bimanual heavy object carrying tasks.