 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying in air ducts
Oct 10, 2024Air ducts are integral to modern buildings but are challenging to access for inspection. Small quadrotor drones offer a potential solution, as they can navigate both horizontal and vertical sections and smoothly fly over debris. However, hovering inside air ducts is problematic due to the airflow generated by the rotors, which recirculates inside the duct and destabilizes the drone, whereas hovering is a key feature for many inspection missions. In this article, we map the aerodynamic forces that affect a hovering drone in a duct using a robotic setup and a force/torque sensor. Based on the collected aerodynamic data, we identify a recommended position for stable flight, which corresponds to the bottom third for a circular duct. We then develop a neural network-based positioning system that leverages low-cost time-of-flight sensors. By combining these aerodynamic insights and the data-driven positioning system, we show that a small quadrotor drone (here, 180 mm) can hover and fly inside small air ducts, starting with a diameter of 350 mm. These results open a new and promising application domain for drones.
Signal-based self-organization of a chain of UAVs for subterranean exploration
Mar 09, 2020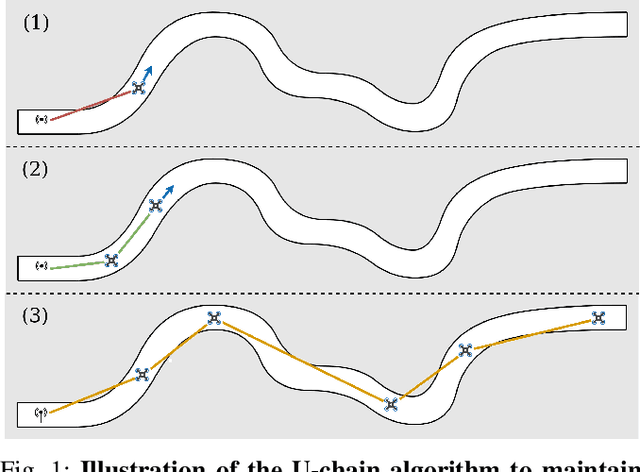
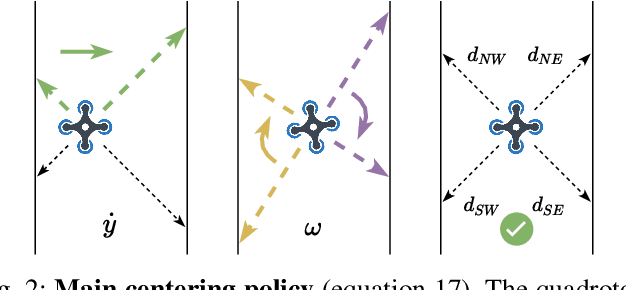
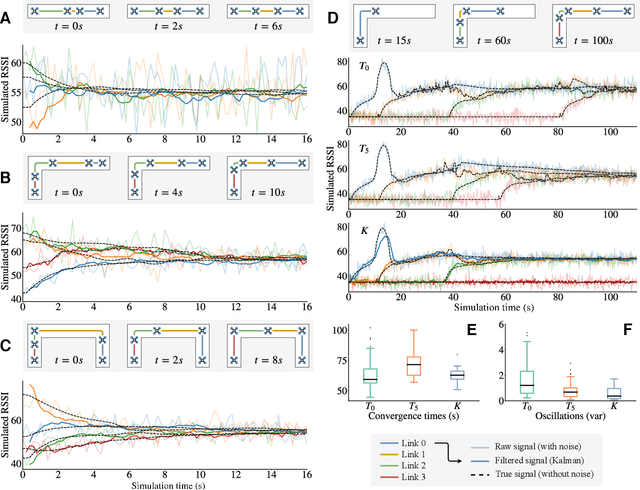
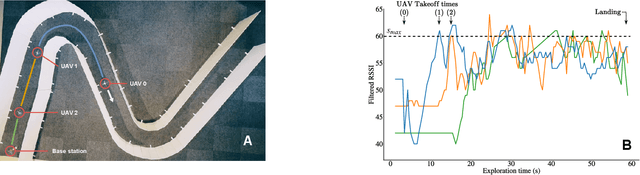
Miniature multi-rotors are promising robots for navigating subterranean networks, but maintaining a radio connection underground is challenging. In this paper, we introduce a distributed algorithm, called U-Chain (for Underground-chain), that coordinates a chain of flying robots between an exploration drone and an operator. Our algorithm only uses the measurement of the signal quality between two successive robots as well as an estimate of the ground speed based on an optic flow sensor. We evaluate our approach formally and in simulation, and we describe experimental results with a chain of 3 real miniature quadrotors (12 by 12 cm) and a base station.
Learning to Gather without Communication
Feb 21, 2018
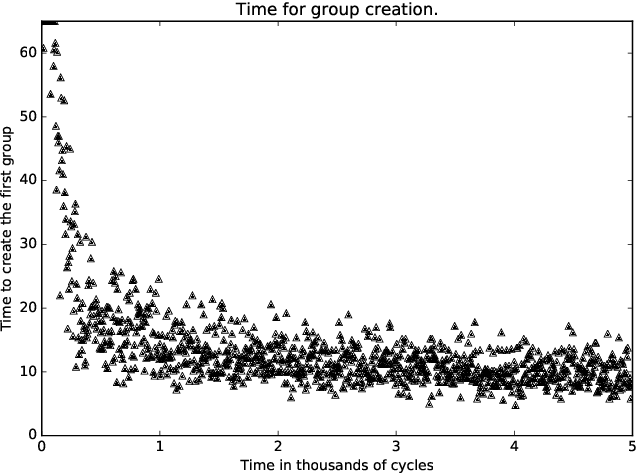
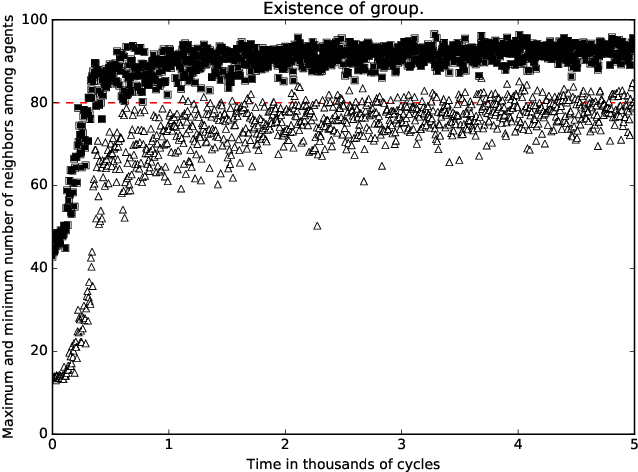
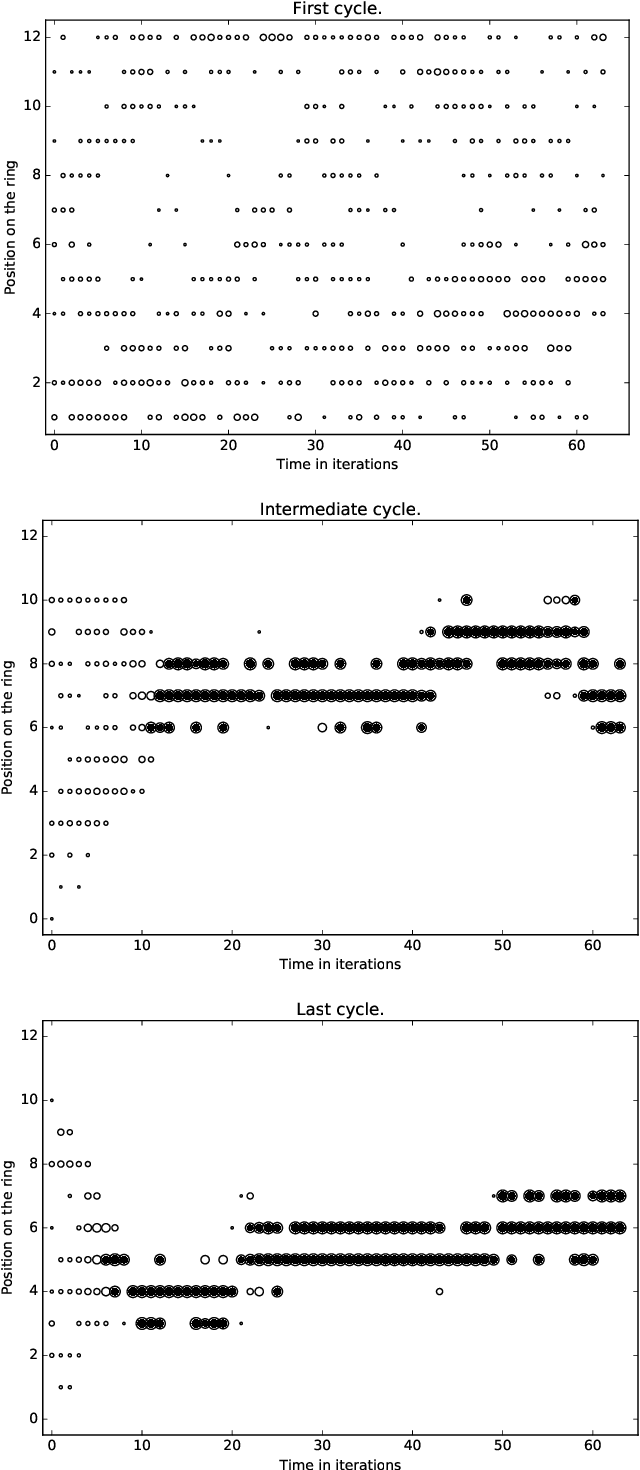
A standard belief on emerging collective behavior is that it emerges from simple individual rules. Most of the mathematical research on such collective behavior starts from imperative individual rules, like always go to the center. But how could an (optimal) individual rule emerge during a short period within the group lifetime, especially if communication is not available. We argue that such rules can actually emerge in a group in a short span of time via collective (multi-agent) reinforcement learning, i.e learning via rewards and punishments. We consider the gathering problem: several agents (social animals, swarming robots...) must gather around a same position, which is not determined in advance. They must do so without communication on their planned decision, just by looking at the position of other agents. We present the first experimental evidence that a gathering behavior can be learned without communication in a partially observable environment. The learned behavior has the same properties as a self-stabilizing distributed algorithm, as processes can gather from any initial state (and thus tolerate any transient failure). Besides, we show that it is possible to tolerate the brutal loss of up to 90\% of agents without significant impact on the behavior.