 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying in air ducts
Oct 10, 2024Air ducts are integral to modern buildings but are challenging to access for inspection. Small quadrotor drones offer a potential solution, as they can navigate both horizontal and vertical sections and smoothly fly over debris. However, hovering inside air ducts is problematic due to the airflow generated by the rotors, which recirculates inside the duct and destabilizes the drone, whereas hovering is a key feature for many inspection missions. In this article, we map the aerodynamic forces that affect a hovering drone in a duct using a robotic setup and a force/torque sensor. Based on the collected aerodynamic data, we identify a recommended position for stable flight, which corresponds to the bottom third for a circular duct. We then develop a neural network-based positioning system that leverages low-cost time-of-flight sensors. By combining these aerodynamic insights and the data-driven positioning system, we show that a small quadrotor drone (here, 180 mm) can hover and fly inside small air ducts, starting with a diameter of 350 mm. These results open a new and promising application domain for drones.
Visual collective behaviors on spherical robots
Sep 30, 2024The implementation of collective motion, traditionally, disregard the limited sensing capabilities of an individual, to instead assuming an omniscient perception of the environment. This study implements a visual flocking model in a ``robot-in-the-loop'' approach to reproduce these behaviors with a flock composed of 10 independent spherical robots. The model achieves robotic collective motion by only using panoramic visual information of each robot, such as retinal position, optical size and optic flow of the neighboring robots. We introduce a virtual anchor to confine the collective robotic movements so to avoid wall interactions. For the first time, a simple visual robot-in-the-loop approach succeed in reproducing several collective motion phases, in particular, swarming, and milling. Another milestone achieved with by this model is bridging the gap between simulation and physical experiments by demonstrating nearly identical behaviors in both environments with the same visual model. To conclude, we show that our minimal visual collective motion model is sufficient to recreate most collective behaviors on a robot-in-the-loop system that is scalable, behaves as numerical simulations predict and is easily comparable to traditional models.
Signal-based self-organization of a chain of UAVs for subterranean exploration
Mar 09, 2020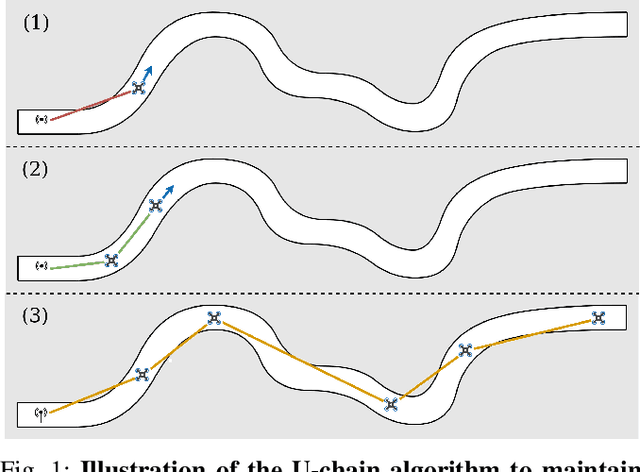
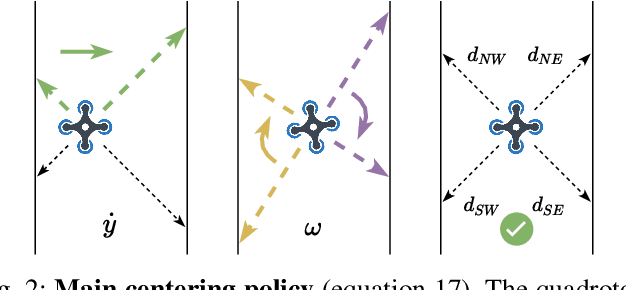
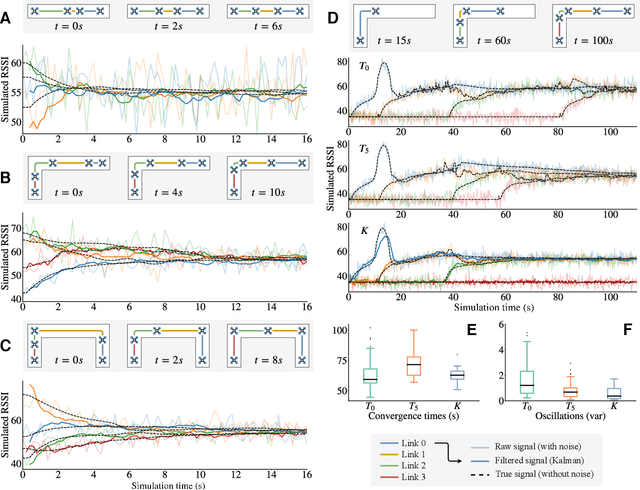
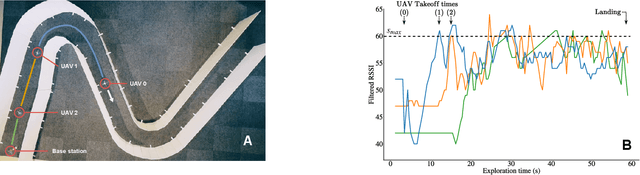
Miniature multi-rotors are promising robots for navigating subterranean networks, but maintaining a radio connection underground is challenging. In this paper, we introduce a distributed algorithm, called U-Chain (for Underground-chain), that coordinates a chain of flying robots between an exploration drone and an operator. Our algorithm only uses the measurement of the signal quality between two successive robots as well as an estimate of the ground speed based on an optic flow sensor. We evaluate our approach formally and in simulation, and we describe experimental results with a chain of 3 real miniature quadrotors (12 by 12 cm) and a base station.
Effect of top-down connections in Hierarchical Sparse Coding
Feb 03, 2020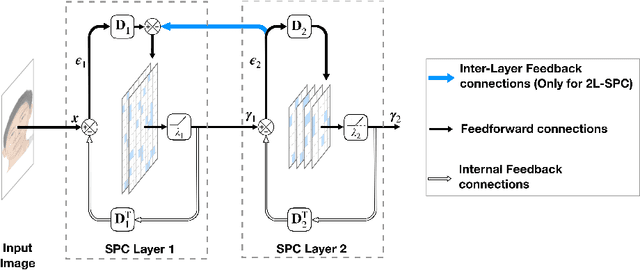
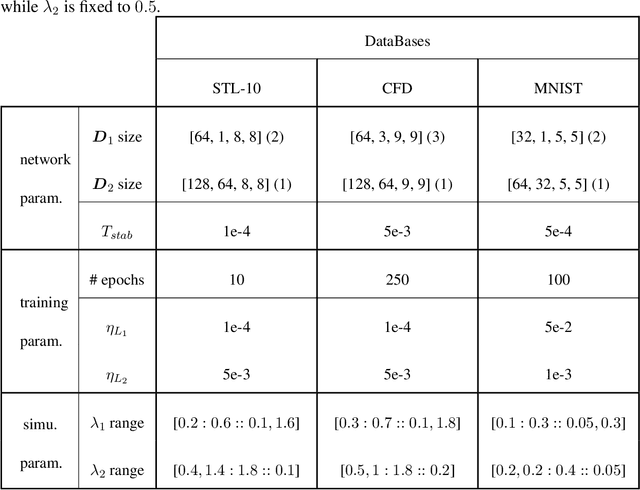
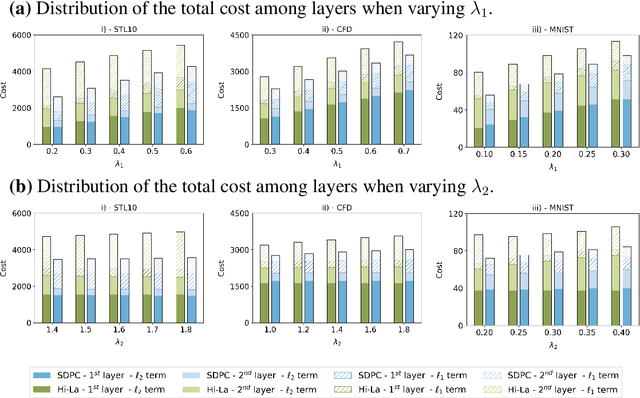
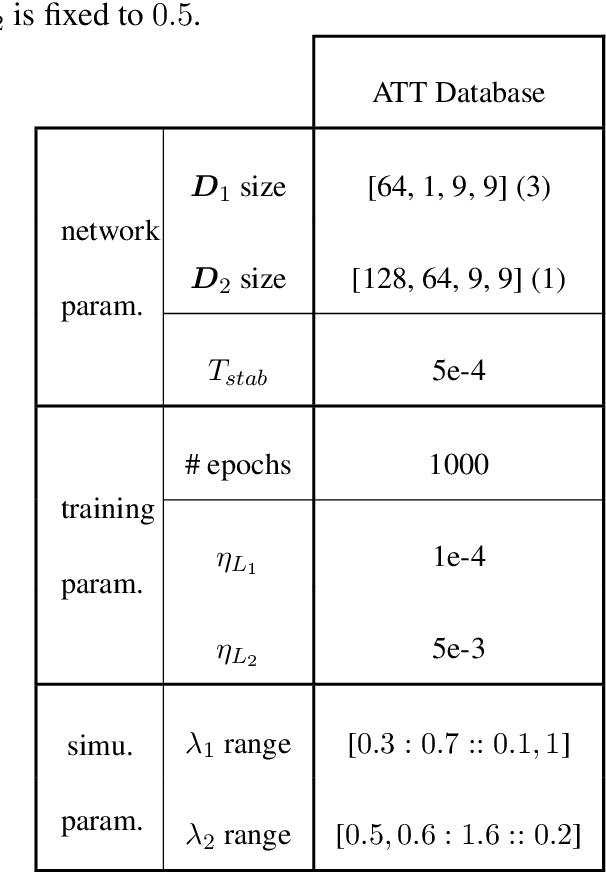
Hierarchical Sparse Coding (HSC) is a powerful model to efficiently represent multi-dimensional, structured data such as images. The simplest solution to solve this computationally hard problem is to decompose it into independent layer-wise subproblems. However, neuroscientific evidence would suggest inter-connecting these subproblems as in the Predictive Coding (PC) theory, which adds top-down connections between consecutive layers. In this study, a new model called 2-Layers Sparse Predictive Coding (2L-SPC) is introduced to assess the impact of this inter-layer feedback connection. In particular, the 2L-SPC is compared with a Hierarchical Lasso (Hi-La) network made out of a sequence of independent Lasso layers. The 2L-SPC and the 2-layers Hi-La networks are trained on 4 different databases and with different sparsity parameters on each layer. First, we show that the overall prediction error generated by 2L-SPC is lower thanks to the feedback mechanism as it transfers prediction error between layers. Second, we demonstrate that the inference stage of the 2L-SPC is faster to converge than for the Hi-La model. Third, we show that the 2L-SPC also accelerates the learning process. Finally, the qualitative analysis of both models dictionaries, supported by their activation probability, show that the 2L-SPC features are more generic and informative.
Meaningful representations emerge from Sparse Deep Predictive Coding
Feb 20, 2019
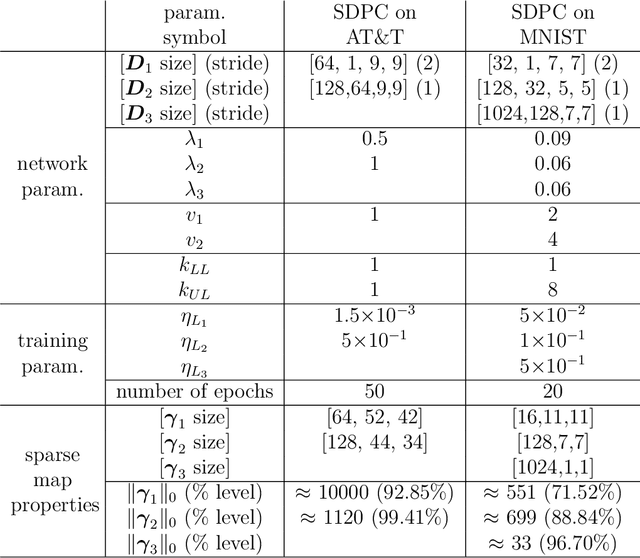
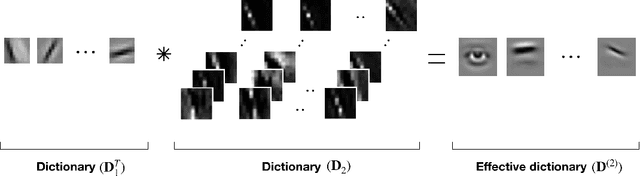
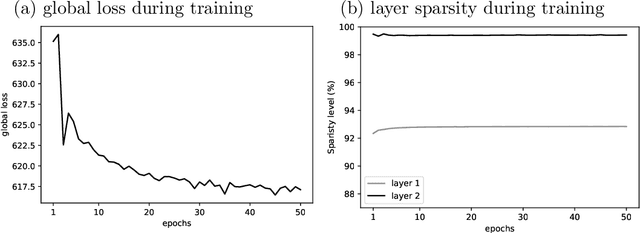
Convolutional Neural Networks (CNNs) are the state-of-the-art algorithms used in computer vision. However, these models often suffer from the lack of interpretability of their information transformation process. To address this problem, we introduce a novel model called Sparse Deep Predictive Coding (SDPC). In a biologically realistic manner, SDPC mimics how the brain is efficiently representing visual information. This model complements the hierarchical convolutional layers found in CNNs with the feed-forward and feed-back update scheme described in the Predictive Coding (PC) theory and found in the architecture of the mammalian visual system. We experimentally demonstrate on two databases that the SDPC model extracts qualitatively meaningful features. These features, besides being similar to some of the biological Receptive Fields of the visual cortex, also represent hierarchically independent components of the image that are crucial to describe it in a generic manner. For the first time, the SDPC model demonstrates a meaningful representation of features within the hierarchical generative model and of the decision-making process leading to a specific prediction. A quantitative analysis reveals that the features extracted by the SDPC model encode the input image into a representation that is both easily classifiable and robust to noise.
From biological vision to unsupervised hierarchical sparse coding
Dec 04, 2018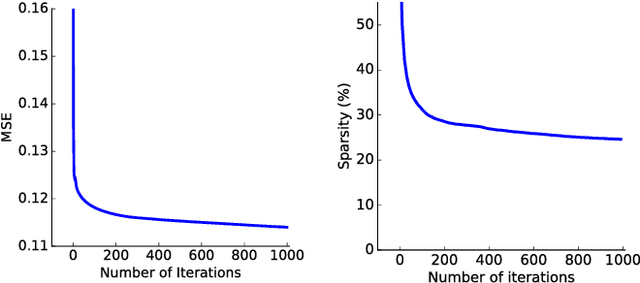

The formation of connections between neural cells is emerging essentially from an unsupervised learning process. For instance, during the development of the primary visual cortex of mammals (V1), we observe the emergence of cells selective to localized and oriented features. This leads to the development of a rough contour-based representation of the retinal image in area V1. We propose a biological model of the formation of this representation along the thalamo-cortical pathway. To achieve this goal, we replicated the Multi-Layer Convolutional Sparse Coding (ML-CSC) algorithm developed by Michael Elad's group.