 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing health-related recommendations in social media: A Case Study of Abortion on YouTube
Apr 11, 2024
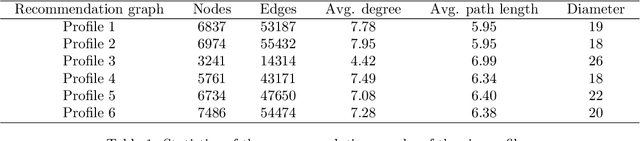
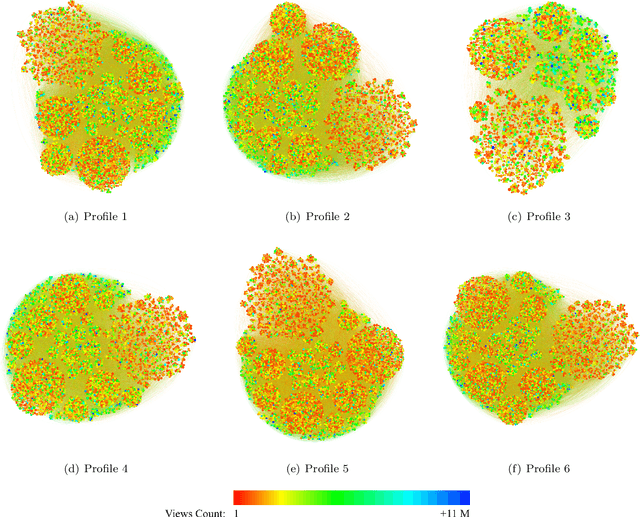
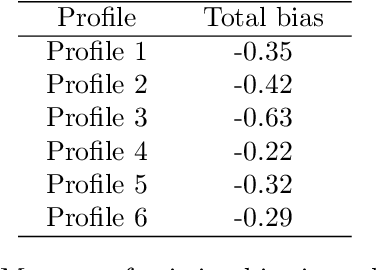
Recommendation algorithms (RS) used by social media, like YouTube, significantly shape our information consumption across various domains, especially in healthcare. Hence, algorithmic auditing becomes crucial to uncover their potential bias and misinformation, particularly in the context of controversial topics like abortion. We introduce a simple yet effective sock puppet auditing approach to investigate how YouTube recommends abortion-related videos to individuals with different backgrounds. Our framework allows for efficient auditing of RS, regardless of the complexity of the underlying algorithms
FEBR: Expert-Based Recommendation Framework for beneficial and personalized content
Jul 17, 2021
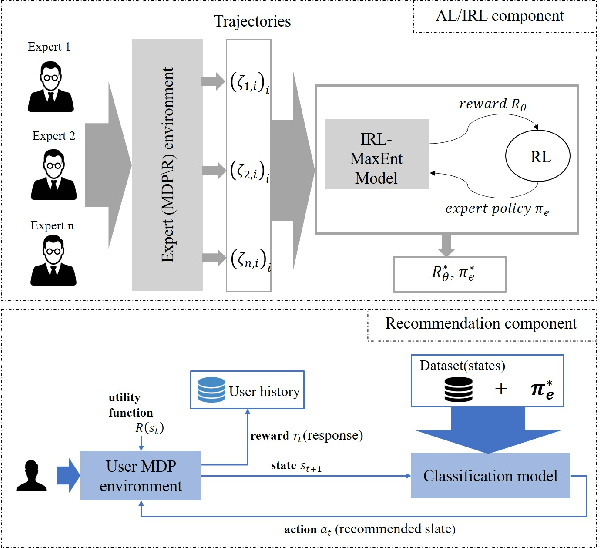


So far, most research on recommender systems focused on maintaining long-term user engagement and satisfaction, by promoting relevant and personalized content. However, it is still very challenging to evaluate the quality and the reliability of this content. In this paper, we propose FEBR (Expert-Based Recommendation Framework), an apprenticeship learning framework to assess the quality of the recommended content on online platforms. The framework exploits the demonstrated trajectories of an expert (assumed to be reliable) in a recommendation evaluation environment, to recover an unknown utility function. This function is used to learn an optimal policy describing the expert's behavior, which is then used in the framework to provide high-quality and personalized recommendations. We evaluate the performance of our solution through a user interest simulation environment (using RecSim). We simulate interactions under the aforementioned expert policy for videos recommendation, and compare its efficiency with standard recommendation methods. The results show that our approach provides a significant gain in terms of content quality, evaluated by experts and watched by users, while maintaining almost the same watch time as the baseline approaches.
Removing Algorithmic Discrimination (With Minimal Individual Error)
Jun 07, 2018
We address the problem of correcting group discriminations within a score function, while minimizing the individual error. Each group is described by a probability density function on the set of profiles. We first solve the problem analytically in the case of two populations, with a uniform bonus-malus on the zones where each population is a majority. We then address the general case of n populations, where the entanglement of populations does not allow a similar analytical solution. We show that an approximate solution with an arbitrarily high level of precision can be computed with linear programming. Finally, we address the inverse problem where the error should not go beyond a certain value and we seek to minimize the discrimination.
Virtuously Safe Reinforcement Learning
May 29, 2018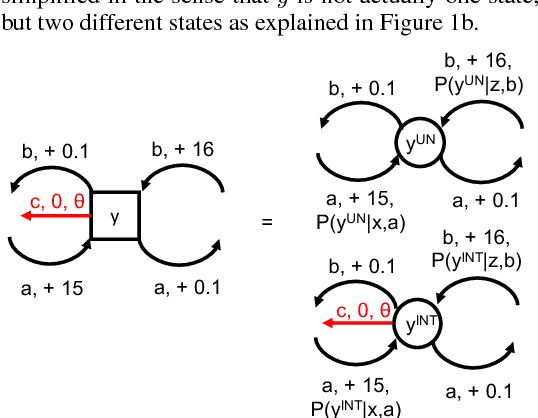
We show that when a third party, the adversary, steps into the two-party setting (agent and operator) of safely interruptible reinforcement learning, a trade-off has to be made between the probability of following the optimal policy in the limit, and the probability of escaping a dangerous situation created by the adversary. So far, the work on safely interruptible agents has assumed a perfect perception of the agent about its environment (no adversary), and therefore implicitly set the second probability to zero, by explicitly seeking a value of one for the first probability. We show that (1) agents can be made both interruptible and adversary-resilient, and (2) the interruptibility can be made safe in the sense that the agent itself will not seek to avoid it. We also solve the problem that arises when the agent does not go completely greedy, i.e. issues with safe exploration in the limit. Resilience to perturbed perception, safe exploration in the limit, and safe interruptibility are the three pillars of what we call \emph{virtuously safe reinforcement learning}.
Learning to Gather without Communication
Feb 21, 2018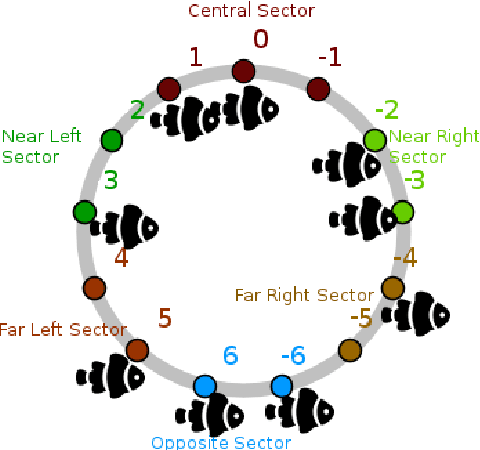
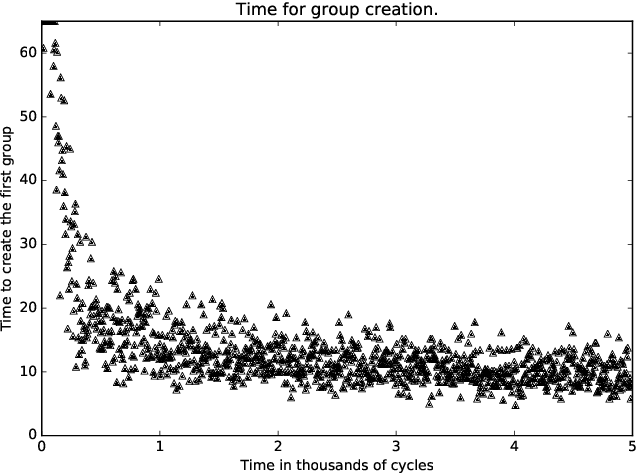
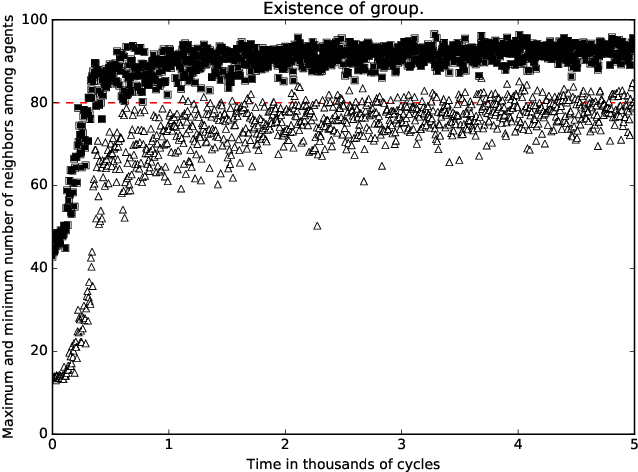
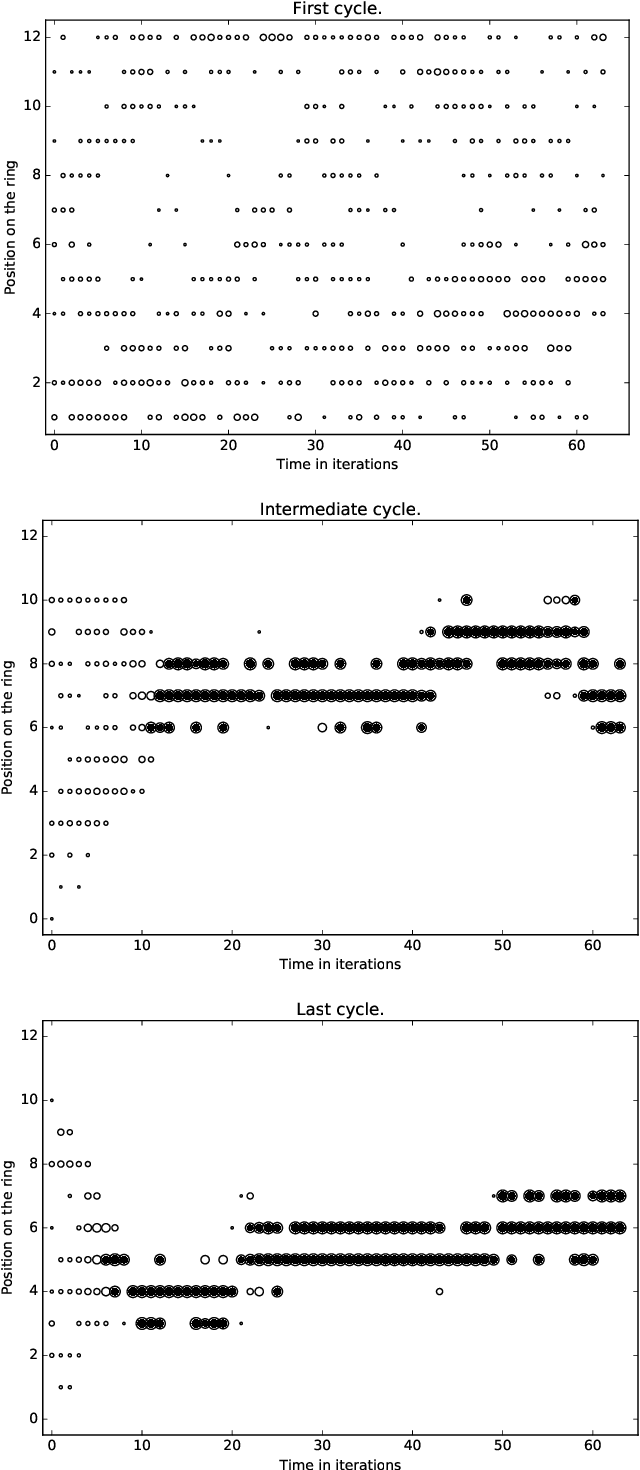
A standard belief on emerging collective behavior is that it emerges from simple individual rules. Most of the mathematical research on such collective behavior starts from imperative individual rules, like always go to the center. But how could an (optimal) individual rule emerge during a short period within the group lifetime, especially if communication is not available. We argue that such rules can actually emerge in a group in a short span of time via collective (multi-agent) reinforcement learning, i.e learning via rewards and punishments. We consider the gathering problem: several agents (social animals, swarming robots...) must gather around a same position, which is not determined in advance. They must do so without communication on their planned decision, just by looking at the position of other agents. We present the first experimental evidence that a gathering behavior can be learned without communication in a partially observable environment. The learned behavior has the same properties as a self-stabilizing distributed algorithm, as processes can gather from any initial state (and thus tolerate any transient failure). Besides, we show that it is possible to tolerate the brutal loss of up to 90\% of agents without significant impact on the behavior.
Dynamic Safe Interruptibility for Decentralized Multi-Agent Reinforcement Learning
May 22, 2017In reinforcement learning, agents learn by performing actions and observing their outcomes. Sometimes, it is desirable for a human operator to \textit{interrupt} an agent in order to prevent dangerous situations from happening. Yet, as part of their learning process, agents may link these interruptions, that impact their reward, to specific states and deliberately avoid them. The situation is particularly challenging in a multi-agent context because agents might not only learn from their own past interruptions, but also from those of other agents. Orseau and Armstrong defined \emph{safe interruptibility} for one learner, but their work does not naturally extend to multi-agent systems. This paper introduces \textit{dynamic safe interruptibility}, an alternative definition more suited to decentralized learning problems, and studies this notion in two learning frameworks: \textit{joint action learners} and \textit{independent learners}. We give realistic sufficient conditions on the learning algorithm to enable dynamic safe interruptibility in the case of joint action learners, yet show that these conditions are not sufficient for independent learners. We show however that if agents can detect interruptions, it is possible to prune the observations to ensure dynamic safe interruptibility even for independent learners.